
讀懂專注於 AI 的去中心化 Web3 底層協議KIP Protocol #2

 RAG 是生成式AI中使用的一種創新技術,涉及AI中的 3 個關鍵價值創造者(App開發者、模型製作者和數據所有者)。
KIP Protocol是世界上第一個支持去中心化RAG的協議,實質上是提供了一種將所有AI去中心化的基礎框架,這是幫助擺脫AI巨頭壟斷的第一步。
RAG 是生成式AI中使用的一種創新技術,涉及AI中的 3 個關鍵價值創造者(App開發者、模型製作者和數據所有者)。
KIP Protocol是世界上第一個支持去中心化RAG的協議,實質上是提供了一種將所有AI去中心化的基礎框架,這是幫助擺脫AI巨頭壟斷的第一步。1)RAG簡述
AI模型是透過大量投餵數據從而進行訓練。它們從數據中學習,調整內部權重以識別模式,從而能夠根據新數據做出預測或決策。然後,模型就能根據新獲得的 "原始"知識回答用戶的問題。
但是,這種訓練過程需要將整個數據集暴露給模型,基本上會導致數據會被 "吸收"到模型中。如果數據中包含機密信息或版權信息,那麼模型就有可能在未來的某個時刻逐字逐句地吐露這些信息。
那麼,如果你不想讓你的數據面臨風險呢?
這就是RAG(檢索增強生成)出現的原因。
RAG 是一種複雜的技術,它能讓AI模型透過檢索外部知識庫和數據庫中的數據和信息,生成它原本不知道的答案。
它就像一個智能助手,雖然不知道你問題的答案,但卻能專業地從外部數據中找到你想要的答案。
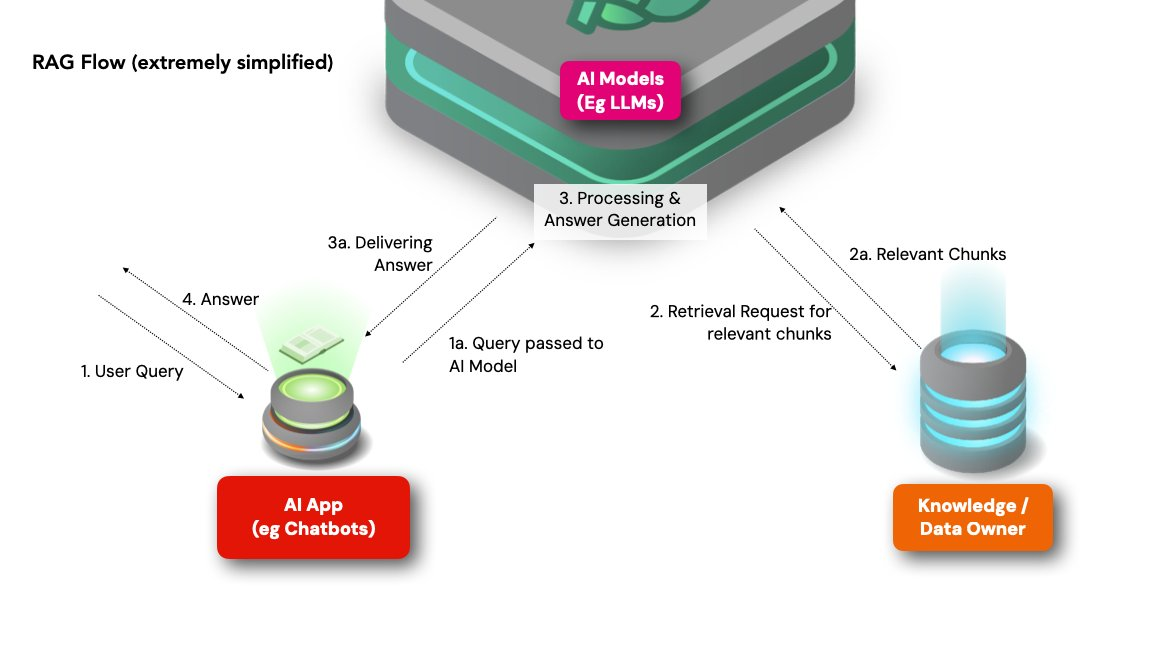
1. 用戶查詢輸入:
首先,用戶向運行 RAG 系統的聊天機器人提出問題。
例如,"COVID-19 的症狀是什麼?"
2. 從外部數據庫檢索:
該模型搜索已連接的外部知識庫和數據庫,如醫學期刊、健康網站和臨床數據庫,來啟動檢索階段,只檢索與用戶查詢相關的數據和信息。
3. 數據處理、過濾和生成:
對檢索到的數據進行處理和過濾,以提取關鍵信息並消除不相關的數據。AI模型將檢索到的數據與用戶查詢的上下文進行整合並生成答案。
在 COVID-19 症狀查詢的案例中,RAG 可能會生成一個列出發燒、咳嗽和呼吸急促等常見症狀的響應,但也可能包括模型訓練時沒有的最新醫學研究論文信息--一個更高質量的答案。
4.發送回覆:
生成的回覆會透過聊天機器人界面呈現給用戶。
因此,RAG 允許使用外部數據來回答AI查詢,而無需透過訓練過程讓模型先 "吸收 "這些數據。
RAG 技術日趨成熟,在我們的研究文件中,我們展示了RAG給出答案的質量可以超越那些訓練有素的模型。https://arxiv.org/pdf/2311.05903.pdf
2)RAG的重要性
RAG 將變得越來越重要,因為:
訓練模型是一項技術性和專業性很強的事情,通常成本很高--不是每個人都具備訓練模型所需的技能或資源。
很多數據(機密數據、專有數據等)的所有者可能不放心讓數據暴露給那些他們不完全擁有或不受他們掌控的模型。
你可能還注意到一個重要問題:
在 RAG 框架下,App開發者、模型製作者和數據所有者能夠一起合作,各自為回答用戶的查詢做出貢獻。
因此,在公平的情況下,各方都應為其貢獻獲得公平的補償。

但目前還沒有一種簡單的方法,可以在不損害各方獨立性或所有權的情況下做到這一點。 (順便提一下,這個問題正是促使我們在一年多前開始建設 KIP 的原因)。
這就是"收益問題"。
3)RAG與中心化AI的"收益問題"
讓我們想像一種情境,其中一個實體擁有人工智能價值創造的所有三個要素:無需在各方之間重新分配從用戶那裡收集的支付,因為可以直接內部進行核算。
但反過來說,如果我們不能接受一個實體擁有AI的價值創造的所有三個要素,(app開發者、模型製作者和數據所有者),我們就必須解決如何在不同行業的AI價值創造角色之間的收益問題。
不解決"收益問題",App開發者、模型製作者和數據所有者就無法保持各自的獨立性和交易自由。
然而AI行業的壟斷現在已經開始了。
以下是我們對 OpenAI 壟斷的看法:
OpenAI 顯然擁有一些最強大的模型--像 GPT-4 這樣的閉源模型,這些模型是收集我們多年來從互聯網發布的知識和內容訓練而成的。這為他們App(如 ChatGPT)和用戶自製的 GPT 提供了燃料。
通過他們的版權保護措施(即承諾為任何被發現在其平台上上傳受版權保護數據的人支付法律費用),他們鼓勵用戶大膽地將數據上傳到他們的封閉平台,而不必擔心法律後果。
鑒於 OpenAI 是一個中心化、閉源 web2 平台,我們應該扪心自問:用戶上傳的數據(無論是 ChatGPT 還是 GPT App)是否仍屬於上傳者?
因此,根據他們現有的模型、以及對所有數據毫無保留的"搜刮"、版權保護措施和龐大的資金儲備,你可能會發現OpenAI是有史以來最貪婪的"數據吸塵器",不斷地吸入數據和資源來滿足他們的模型需求。
將上述所有因素(以及他們為硬件籌集的70億美元)總結在一起,我們就不難看出,除非採取一些措施,否則由一家或幾家公司完全壟斷AI行業的事實將不可避免。
基於我們已經分享過的原因,我們堅信AI行業的壟斷對人類不利,並我們也會接下來積極想出擺脫被壟斷的解決辦法。
4)去中心化RAG的意義
RAG 涉及AI價值創造的所有 3 個核心因素(App開發者、模型製作者和數據所有者)。
因此,透過建立一個去中心化 RAG 的框架,KIP 本質上其實是建立了一個去中心化控制AI價值創造的框架,從而為所有價值創造者提供一個公平競爭的環境,從而擺脫AI壟斷。
我們允許AI以高效的方式發揮作用,成為數百萬小規模和大規模創作者共同努力的結晶,而無需任何一個大型公司來一手掌控每個核心功能。
為此,我們將首先解決阻礙 RAG 去中心化的 3 個基礎問題:
1. 所有權: 保證(App開發者、模型製作者和數據所有者)可以輕鬆、安全地向 web3 發布內容,透過創建以ERC 3525半同質令牌(Semi-Fungible Tokens)的形式構建他們的Web3"交易實體",從而使他們能夠在鏈上證明其數字產權。
2. 鏈上/鏈下連接:確保鏈下和鏈上互動的絲滑度,為App開發者、模型製作者和數據所有者提供一個開放的環境,使其能夠輕鬆自由地相互連接。
3. 貨幣化: 提供一個通用的框架,用於記錄和核算每個AI價值創造者的貢獻,以及自動收入分成和提款。

透過實現 RAG(d/RAG)去中心化,KIP 正在繪製第一張擺脫AI壟斷的重要藍圖。
為每個AI價值創造者解鎖數字產權,讓每個人都能在保持獨立的同時進行交易,這也與web2的大型科技公司試圖實現的目標恰恰相反。
KIP 協議會為AI價值創造者提供擺脫AI壟斷所必需的工具。
關於 KIP Protocol
KIP Protocol 為 AI App 開發者、模型製作者和數據所有者構建 Web3 底層協議,使 AI 資產能夠輕鬆部署和實現貨幣化,同時保留完整的數字產權。
KIP 將搭建全新的 AI 商業生態系統,以解決去中心化 AI 部署中面臨的問題與挑戰,並確保所有人都能享受 AI 帶來的經濟利益。
KIP 團隊匯集了自 2019 年以來致力於 AI 研究的資深博士和技術專家,他們同時在 Web3 領域擁有深厚的專業背景和豐富經驗,致力於推動 AI 去中心化,成為去中心化 AI 浪潮的加速催化劑。
要了解更多信息,請關注我們的官方賬號:






