Privaseaを深く解読する。顔データを使ってNFTを鋳造するのはこんな風にも楽しめる?

 顔データはどれくらいの大きさでもブロックチェーンに載せられますか?私の顔情報は盗まれますか?Privaseaは何をしているのですか?
顔データはどれくらいの大きさでもブロックチェーンに載せられますか?私の顔情報は盗まれますか?Privaseaは何をしているのですか?著者:十四君
1.はじめに
最近、Privasea が発起した顔NFTの鋳造プロジェクトが異常に人気を集めています! 一見すると簡単そうですが、このプロジェクトではユーザーがIMHUMAN(私は人間です)** モバイルアプリで自分の顔を入力し、その顔データをNFTとして鋳造することができます。この顔データのブロックチェーン化 + NFT** の組み合わせにより、プロジェクトは4月末のローンチ以来、20W+ のNFT鋳造量を達成し、その人気は明らかです。 私も不思議に思いました、なぜでしょう?顔データはどれほど大きくてもブロックチェーンに載せられるのでしょうか?私の顔情報は盗用されるのでしょうか?Privaseaは何をしているのでしょうか? などなど、プロジェクト自体とプロジェクトの運営者Privaseaについて調査を続け、真相を探ります。 キーワード:NFT、AI、FHE(完全同型暗号)、DePIN
2.Web2からWeb3へ - 人間と機械の対抗は決して止まらない
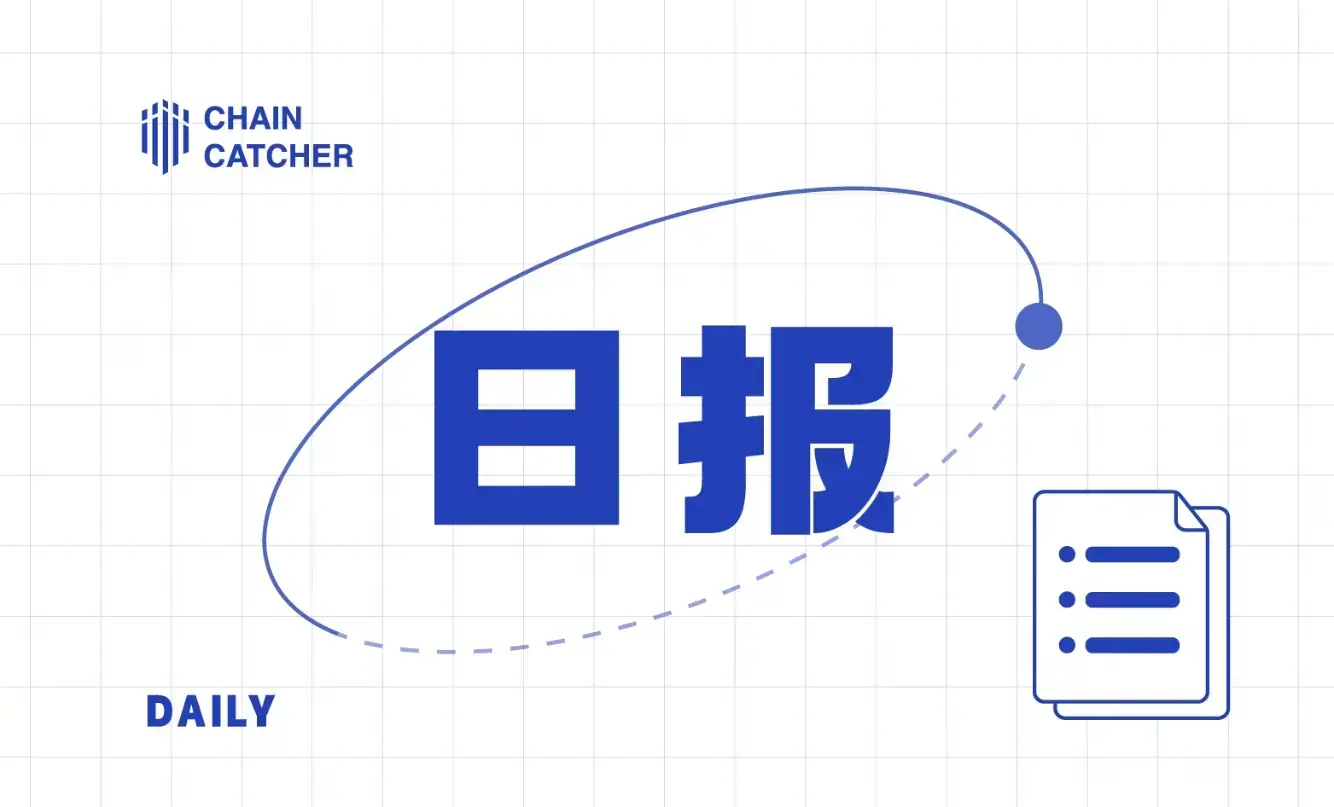
まず、顔NFT鋳造というプロジェクト自体の目的を解読しましょう。このプロジェクトが単に顔データをNFTに鋳造するだけだと思ったら、大間違いです。 上述のプロジェクトのアプリ名IMHUMAN(私は人間です) はこの問題をよく説明しています:実際、このプロジェクトは顔認識を通じて画面の前にいるあなたが本物の人間かどうかを判断することを目的としています。 まず、なぜ人間と機械の識別が必要なのでしょうか? Akamaiが提供した2024Q1レポート(付録参照)によると、ボット(自動化プログラムで、HTTPリクエストなどの操作を人間のように模倣する)はインターネットトラフィックの42.1%を占めており、その中で悪意のあるトラフィックは全体の27.5%を占めています。 悪意のあるボットは、中央集権的なサービスプロバイダーに遅延応答やダウンなどの壊滅的な結果をもたらし、実際のユーザーの使用体験に影響を与える可能性があります。
チケットの取得シーンを例に挙げると、詐欺者は複数の仮想アカウントを新たに作成してチケットを取得する操作を行うことで、チケット取得の成功確率を大幅に高めることができます。さらに、彼らは自動化プログラムをサービスプロバイダーのデータセンターの近くに配置し、ほぼ0遅延での購入を実現します。
一般のユーザーは、これらのハイテクユーザーに対してほとんど勝ち目がありません。
サービスプロバイダーもこれに対していくつかの努力をしています。クライアント側では、Web2のシーンで本人確認や行動キャプチャなどのさまざまな方法を導入して人間と機械を区別し、サーバー側ではWAFポリシーなどの手段を通じて特徴フィルタリングを行っています。
では、これで問題は解決するのでしょうか?
明らかにそうではありません。なぜなら、詐欺による利益は非常に大きいからです。
また、人間と機械の対抗は持続的であり、詐欺者と検証者の二つの役割は常に自らの武器庫をアップグレードしています。
詐欺者の例を挙げると、近年のAIの急速な発展を背景に、クライアント側の行動キャプチャはさまざまな視覚モデルによって効果的に打破され、AIは人間よりも速く正確に識別できる能力を持っています。これにより、検証者は受動的にアップグレードせざるを得なくなり、初期のユーザーの行動特徴検出(画像キャプチャ)から、生物学的特徴検出(感知検証:クライアント環境の監視、デバイスフィンガープリンティングなど)へと移行し、高リスクな操作では生物学的特徴検出(指紋、顔認識)にまで至る可能性があります。
Web3においても、人間と機械の検出は強い需要があります。
いくつかのプロジェクトのエアドロップでは、詐欺者が複数の偽アカウントを作成してウィッチ攻撃を仕掛けることができるため、この時に私たちは本物の人間を識別する必要があります。
Web3の金融属性により、アカウントのログイン、出金、取引、送金などの高リスクな操作では、ユーザーが本物の人間であるだけでなく、アカウントの所有者であることを確認する必要があり、顔認識が最適な選択肢となります。 需要は明確ですが、問題はどのように実現するかです。 よく知られているように、分散化はWeb3の本来の目的です。Web3上で顔認識を実現する方法を議論する際、実際にはより深い問題はWeb3がAIシーンにどのように適応すべきかです:
- 私たちはどのように分散型の機械学習計算ネットワークを構築すべきか?
- ユーザーデータのプライバシーが漏洩しないようにするには?
- ネットワークの運営をどのように維持するかなど?
3、Privasea AI NetWork - プライバシー計算 + AIの探求
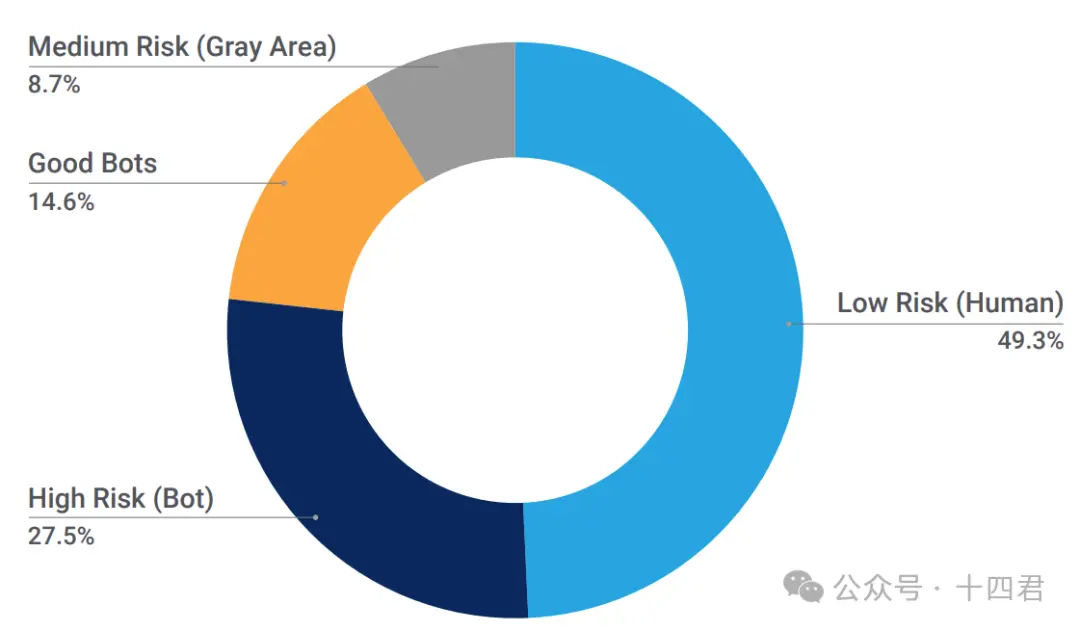
前章で触れた問題に対して、Privaseaは革新的な解決策を提供しました:PrivaseaはFHE(完全同型暗号)に基づいてPrivasea AI NetWorkを構築し、Web3上のAIシーンのプライバシー計算問題を解決します。 FHEは、平文と暗号文が同じ演算を行った後に結果が一致することを保証する暗号技術です。 Privaseaは従来のTHEを最適化してパッケージ化し、アプリケーション層、最適化層、算術層、原始層に分割し、HESeaライブラリを形成しました。これにより、機械学習シーンに適応しました。以下は各層の具体的な機能です:
 階層構造を通じて、Privaseaは各ユーザーの独自のニーズを満たすために、より具体的でカスタマイズされた解決策を提供します。 Privaseaの最適化パッケージは主にアプリケーション層と最適化層に集中しており、他の同型ライブラリの基本的な解決策と比較して、これらのカスタマイズされた計算は千倍以上の加速を提供できます。
階層構造を通じて、Privaseaは各ユーザーの独自のニーズを満たすために、より具体的でカスタマイズされた解決策を提供します。 Privaseaの最適化パッケージは主にアプリケーション層と最適化層に集中しており、他の同型ライブラリの基本的な解決策と比較して、これらのカスタマイズされた計算は千倍以上の加速を提供できます。
3.1 Privasea AI NetWorkのネットワークアーキテクチャ
Privasea AI NetWorkのアーキテクチャを見ると:
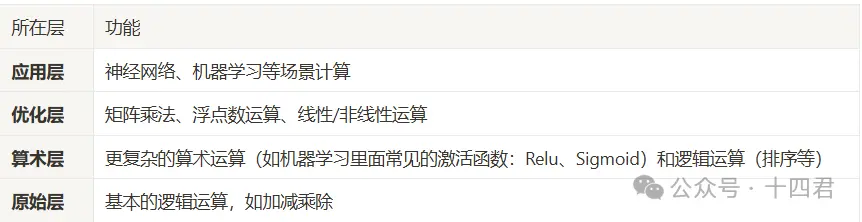
 そのネットワークには合計4つの役割があります:データ所有者、Privanetixノード、復号器、結果受取者。
そのネットワークには合計4つの役割があります:データ所有者、Privanetixノード、復号器、結果受取者。
データ所有者 :Privasea APIを通じて、安全にタスクとデータを提出します。
Privanetixノード :ネットワーク全体のコアであり、先進的なHESeaライブラリを装備し、ブロックチェーンに基づくインセンティブメカニズムを統合して、安全かつ効率的な計算を実行し、基盤となるデータのプライバシーを保護し、計算の完全性と機密性を確保します。
復号器 :Privasea APIを通じて復号された結果を取得し、結果を検証します。
結果受取者 :タスクの結果はデータ所有者およびタスク発行者が指定した人に返されます。
3.2 Privasea AI NetWorkのコアワークフロー
以下はPrivasea AI NetWorkの一般的なワークフローチャートです:
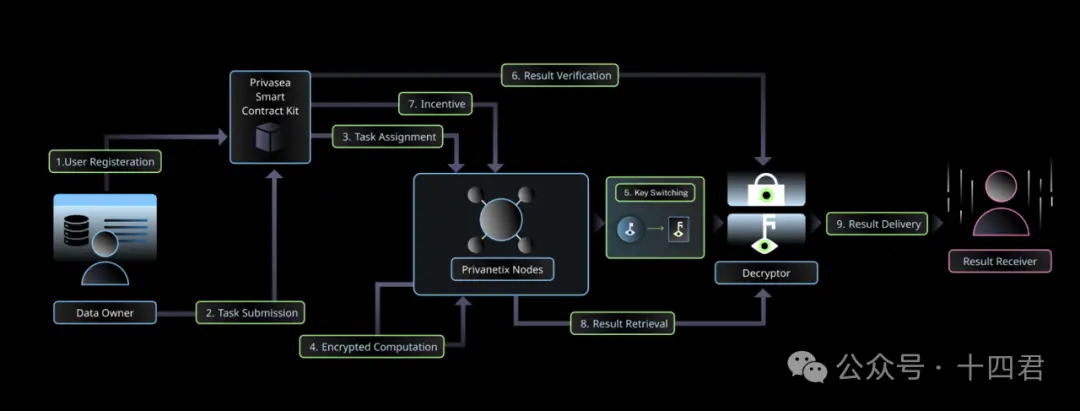
STEP 1:ユーザー登録 :データ所有者は必要な認証と承認証明書を提供してプライバシーAIネットワークでの登録プロセスを開始します。このステップにより、承認されたユーザーのみがシステムにアクセスし、ネットワーク活動に参加できることが保証されます。
STEP 2:タスク提出 :計算タスクと入力データを提出します。データはHEseaライブラリで暗号化されたデータであり、データ所有者は最終結果にアクセスできる承認された復号者と結果受取者を指定します。
STEP 3:タスク割り当て :ネットワーク上に展開されたブロックチェーンに基づくスマートコントラクトが、可用性と能力に基づいて計算タスクを適切なPrivanetixノードに割り当てます。この動的な割り当てプロセスにより、効率的なリソース配分と計算タスクの割り当てが確保されます。
STEP 4:暗号計算 :指定されたPrivanetixノードが暗号化データを受け取り、HESeaライブラリを使用して計算を行います。これらの計算は、機密データを復号することなく実行され、その機密性が保持されます。計算の完全性をさらに検証するために、Privanetixノードはこれらのステップに対してゼロ知識証明を生成します。
STEP 5:キー切り替え :計算が完了した後、指定されたPrivanetixノードはキー切り替え技術を使用して最終結果が承認されたものであり、指定された復号器のみがアクセスできることを保証します。
STEP 6:結果検証 :計算が完了した後、Privanetixノードは暗号化された結果と対応するゼロ知識証明をブロックチェーンに基づくスマートコントラクトに返送し、将来の検証に供します。
STEP 7:インセンティブメカニズム :Privanetixノードの貢献を追跡し、報酬を配分します。
STEP 8:結果取得 :復号器はPrivasea APIを利用して暗号化された結果にアクセスします。彼らの最優先事項は計算の完全性を検証し、Privanetixノードがデータ所有者の意図に従って計算を実行したことを確認することです。
STEP 9:結果配信 :復号された結果をデータ所有者が事前に指定した結果受取者と共有します。
Privasea AI NetWorkのコアワークフローでは、ユーザーに公開されるのはオープンAPIであり、ユーザーは入力パラメータと対応する結果にのみ注目すればよく、ネットワーク内部の複雑な計算を理解する必要はなく、心的負担が軽減されます。また、エンドツーエンドの暗号化により、データ処理に影響を与えることなく、データ自体が漏洩することはありません。 PoW & PoSの二重メカニズムの重ね合わせ Privaseaが最近発表したWorkHeart NFTとStarFuel NFTは、PoWとPoSの二重メカニズムを通じてネットワークノードの管理と報酬の配分を行います。WorkHeart NFTを購入することでPrivanetixノードになる資格を得てネットワーク計算に参加し、PoWメカニズムに基づいてトークン収益を得ることができます。StarFuel NFTはノードブースター(限定5000)であり、WorkHeartと組み合わせることができ、PoSのように、質権を持つトークンの数が多いほど、WorkHeartノードの収益倍率が大きくなります。 では、なぜPoWとPoSなのか? 実はこの質問は比較的簡単に答えられます。 PoWの本質は、計算の時間コストを通じてノードの悪行率を低下させ、ネットワークの安定性を維持することです。BTCのランダム数検証による大量の無効計算とは異なり、このプライバシー計算ネットワークノードの実際の作業成果(計算)は、作業量メカニズムに直接結びついており、自然にPoWに適しています。 一方、PoSは経済資源のバランスを取りやすくします。 こうして、WorkHeart NFTはPoWメカニズムを通じて収益を得て、StarFuel NFTはPoSメカニズムを通じて収益倍率を向上させ、多層的で多様なインセンティブメカニズムを形成し、ユーザーが自身のリソースと戦略に基づいて適切な参加方法を選択できるようにします。二つのメカニズムの組み合わせにより、収益分配構造を最適化し、ネットワーク内の計算資源と経済資源の重要性のバランスを取ることができます。
3.3 まとめ
このように、Privatosea AI NetWorkはFHEに基づいて暗号化された機械学習システムを構築しました。FHEのプライバシー計算の特性により、計算タスクを分散環境下の各計算ノード(Privanetix)に分割し、ZKPを通じて結果の有効性を検証し、PoWとPoSの二重メカニズムを利用して計算結果を提供するノードに報酬または罰を与え、ネットワークの運営を維持します。Privasea AI NetWorkの設計は、さまざまな分野のプライバシー保護AIアプリケーションの道を開いていると言えます。
4、FHE同型暗号 - 新しい暗号学の聖杯?
前章で見たように、Privatosea AI NetWorkの安全性はその基盤となるFHEに依存しています。FHEの分野でのリーダーであるZAMAが技術的なブレークスルーを続ける中、FHEは投資家から新しい暗号学の聖杯と称されています。これをZKPや関連する解決策と比較してみましょう。
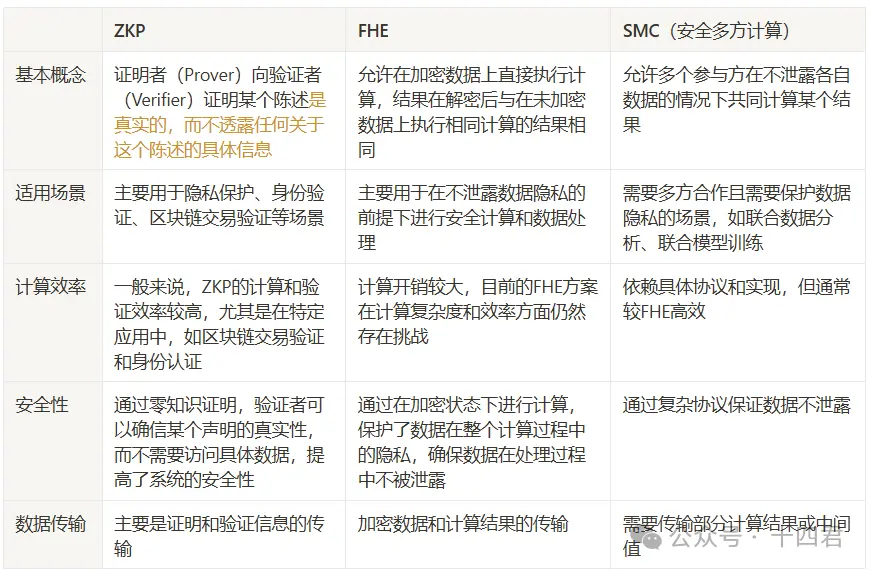 比較すると、ZKPとFHEの適用シーンには大きな違いがあり、FHEはプライバシー計算に重点を置き、ZKPはプライバシー検証に重点を置いています。 SMCはFHEとより大きな重複があるようで、SMCの概念は安全な共同計算であり、共同計算のコンピュータ個体のデータプライバシー問題を解決します。
比較すると、ZKPとFHEの適用シーンには大きな違いがあり、FHEはプライバシー計算に重点を置き、ZKPはプライバシー検証に重点を置いています。 SMCはFHEとより大きな重複があるようで、SMCの概念は安全な共同計算であり、共同計算のコンピュータ個体のデータプライバシー問題を解決します。
5、FHEの限界
FHEはデータ処理権とデータ所有権の分離を実現し、計算に影響を与えることなくデータ漏洩を防ぎます。しかし同時に、犠牲にされるのは計算速度です。 暗号化は両刃の剣のようなもので、安全性を高める一方で、計算速度が大幅に低下します。 近年、さまざまなタイプのFHEの性能向上策が提案されており、アルゴリズムの最適化に基づくものや、ハードウェア加速に依存するものがあります。
- アルゴリズムの最適化に関しては、新しいFHEソリューション(CKKSや最適化されたブートストラップ法)がノイズの増加と計算コストを大幅に削減しています。
- ハードウェア加速に関しては、カスタムGPUやFPGAなどのハードウェアが多項式計算の性能を大幅に向上させています。
さらに、混合暗号化ソリューションの適用も探求されています。部分同型暗号(PHE)と検索暗号(SE)を組み合わせることで、特定のシーンで効率を向上させることができます。それでも、FHEは性能面で平文計算と大きな差があります。
6、まとめ
Privaseaはその独自のアーキテクチャと比較的効率的なプライバシー計算技術を通じて、ユーザーに高度に安全なデータ処理環境を提供するだけでなく、Web3とAIの深い統合の新たな章を開きました。 その基盤となるFHEは本質的に計算速度に劣るものの、Privaseaは最近ZAMAと協力し、プライバシー計算の難題に共同で取り組んでいます。今後、技術のブレークスルーが続く中で、Privaseaはより多くの分野でその潜在能力を発揮し、プライバシー計算とAIアプリケーションの探求者となることが期待されます。