
Arweave 第 17 版白皮书解読(4):完全なデータコピーを保存することが王道である

 ArweaveはSPoResメカニズムを通じてそのコアコンセンサスプロトコルを構築しています。前提として、インセンティブの下で、個々のマイナーやグループ協力マイナーが、完全なデータコピーを維持することがマイニングの最良の戦略であると実行することを仮定しています。完全なデータコピーを保存することが王道です!
ArweaveはSPoResメカニズムを通じてそのコアコンセンサスプロトコルを構築しています。前提として、インセンティブの下で、個々のマイナーやグループ協力マイナーが、完全なデータコピーを維持することがマイニングの最良の戦略であると実行することを仮定しています。完全なデータコピーを保存することが王道です!
解釈(三)では、数学的な導出を通じて #SPoRes の実現可能性を証明しました。文中のボブとアリスは、この証明ゲームに参加しました。そして、#Arweave のマイニングでは、プロトコルがこのSPoResゲームの修正版を展開しました。マイニングプロセスでは、プロトコルがボブの役割を果たし、ネットワーク内のすべてのマイナーが共同でアリスの役割を担います。SPoResゲームの各有効な証明は、Arweaveの次のブロックを生成するために使用されます。具体的には、Arweaveブロックの生成は以下のパラメータに関連しています:

ここで:
BI = Arweaveネットワークのブロックインデックス Block Index;
800*np = 各チェックポイントごとに各パーティションで最大800回のハッシュを解除します。npはマイナーが保存するサイズ3.6TBのパーティションの数であり、両者を掛け合わせると、そのマイナーが1秒間に最大で試行できるハッシュ計算の回数になります。
d = ネットワークの難易度。
成功した有効な証明は、難易度値を超える証明であり、この難易度値は時間とともに調整され、平均して120秒ごとに1つのブロックが生成されることを保証します。ブロックiとブロック(i+10)の間の時間差がtである場合、古い難易度diから新しい難易度d{i+10}への調整は以下のように計算されます:

ここで:
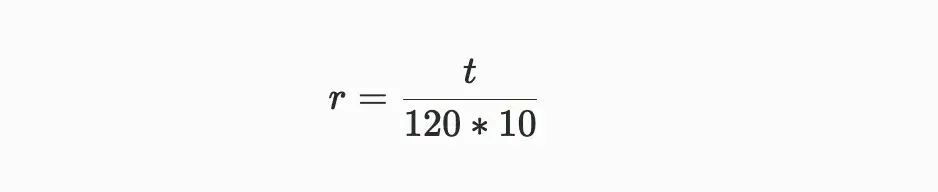
公式の注釈:上記の2つの公式から、ネットワークの難易度の調整は主にパラメータrに依存しており、rは実際のブロック生成に必要な時間がシステムの期待する120秒ごとの基準時間からの偏差を示します。
新しく計算された難易度は、生成された各SPoA証明に基づいて、ブロックを掘る成功の確率を決定します。具体的には以下の通りです:

公式の注釈:上記の導出により、新しい難易度での掘削成功確率は、古い難易度での成功確率にパラメータrを掛けたものです。
同様に、VDFの難易度も再計算され、目的はチェックポイント周期が時間的に毎秒発生することを維持することです。
完全なコピーのインセンティブメカニズム
Arweaveは、SPoResメカニズムを通じて各ブロックを生成することを、次の仮定に基づいています:
インセンティブの下で、個々のマイナーでも共同で協力するマイナーでも、完全なデータコピーを維持することがマイニングの最良の戦略として実行されます。
以前に紹介したSPoResゲームでは、データセットの同じ部分の2つのコピーが解放するSPoAハッシュの数は、データセット全体の完全なコピーを保存する場合と同じであり、これによりマイナーに投機的行動の可能性が残されました。したがって、Arweaveはこのメカニズムを実際に展開する際にいくつかの修正を行い、プロトコルは毎秒解放されるSPoAチャレンジの数を2つの部分に分けました。
- 一部は、マイナーが保存するパーティション内で特定のパーティションを指定して一定数のSPoAチャレンジを解放します;
- もう一部は、Arweaveのすべてのデータパーティションの中からランダムに1つのパーティションを指定してSPoAチャレンジを解放します。もしマイナーがそのパーティションのコピーを保存していない場合、その部分のチャレンジ数を失います。
ここで、SPoAとSPoResの関係について疑問に思うかもしれません。合意メカニズムはSPoResですが、なぜ解放されるのはSPoAのチャレンジなのでしょうか?実際、これらの間には従属関係があります。SPoResはこの合意メカニズムの総称であり、マイナーが行う必要のある一連のSPoA証明チャレンジが含まれています。
これを理解するために、前のセクションで説明したVDFがどのようにSPoAチャレンジを解放するために使用されるかを確認します。

上記のコードは、VDF(暗号時計)を通じて、特定のSPoA数から構成される回溯範囲を解放するプロセスを詳細に説明しています。
- 約1秒ごとに、VDFハッシュチェーンはチェックポイント(Check)を出力します;
- このチェックポイントCheckは、マイニングアドレス(addr)、パーティションインデックス(index(p))、および元のVDFシード(seed)と共にRandomXアルゴリズムを使用してハッシュ値H0を計算します。このハッシュ値は256ビットの数字です;
- C1は回溯オフセットで、H0をパーティションのサイズsize(p)で割った余りから得られ、これは最初の回溯範囲の開始オフセットになります;
- この開始オフセットからの連続した100MBの範囲内の400個の256KBのデータブロックが、解放された最初の回溯範囲のSPoAチャレンジです。
- C2は第2回溯範囲の開始オフセットで、H0をすべてのパーティションサイズの合計で割った余りから得られ、同様に第2回溯範囲の400個のSPoAチャレンジを解放します。
- これらのチャレンジの制約は、第2範囲内のSPoAチャレンジが第1範囲の対応する位置にもSPoAチャレンジが必要であることです。
各パッケージ化されたパーティションの性能
各パッケージ化されたパーティションの性能は、各パーティションが各VDFチェックポイントで生成するSPoAチャレンジの数を指します。マイナーがパーティションの唯一のコピーUnique Replicasを保存している場合、SPoAチャレンジの数は、マイナーが同じデータの複数のバックアップCopiesを保存している場合よりも多くなります。
ここでの「唯一のコピー」という概念は「バックアップ」とは大きく異なり、具体的には過去の文章『Arweave 2.6は中本聡のビジョンにより適しているかもしれない』を読むことができます。
もしマイナーがパーティションの唯一のコピーのデータを保存している場合、各パッケージ化されたパーティションはすべての最初の回溯範囲のチャレンジを生成し、その後、保存されたパーティションコピーの数に基づいてそのパーティション内の第2回溯範囲を生成します。もし全体のArweave織りネットワークにm個のパーティションがあり、マイナーがその中のn個のパーティションの唯一のコピーを保存している場合、各パッケージ化されたパーティションの性能は:

マイナーが保存するパーティションが同じデータのバックアップである場合、各パッケージ化されたパーティションは依然としてすべての最初の回溯範囲のチャレンジを生成します。しかし、1/mの確率でのみ、第2回溯範囲がこのパーティション内に位置します。これにより、このストレージ戦略行動には顕著な性能ペナルティが生じ、SPoAチャレンジの数の比率は次のようになります:


図1:マイナー(または協力するマイナーのグループ)がデータセットをパッケージ化する際、特定のパーティションの性能が向上します。
図1の青い線は、パーティションの唯一のコピーを保存する性能perf_{unique}(n,m)を示しており、この図は、マイナーが非常に少数のパーティションコピーしか保存していない場合、各パーティションのマイニング効率が50%に過ぎないことを直感的に示しています。すべてのデータセット部分を保存および維持する場合、すなわちn=mの場合、マイニング効率は最大の1に達します。
総ハッシュレート
総ハッシュレート(図2参照)は、以下の方程式によって与えられ、各パーティション(per partition)の値にnを掛けたものです:

上記の公式は、織りネットワーク(Weave)のサイズが増加するにつれて、唯一のコピーのデータを保存しない場合、ペナルティ関数(Penalty Function)が保存されるパーティションの数の増加に伴い二次的に増加することを示しています。

図2:唯一のデータセットとバックアップデータセットの総マイニングハッシュレート
限界パーティション効率
このフレームワークに基づいて、マイナーが新しいパーティションを追加する際に直面する意思決定問題を探ります。すなわち、既存のパーティションをコピーするか、他のマイナーから新しいデータを取得して唯一のコピーとしてパッケージ化するかです。彼らが最大可能なm個のパーティションの中からn個のパーティションの唯一のコピーをすでに保存している場合、彼らのマイニングハッシュレートは比例します:

したがって、新しいパーティションの唯一のコピーを追加することによる追加の利益は:

既にパッケージ化されたパーティションをコピーする(より小さな)利益は:

最初の数を2番目の数で割ると、マイナーの相対限界パーティション効率(relative marginal partition efficiency)が得られます:


図3:マイナーは、既存のデータの追加コピーを作成する(オプション2)よりも、完全なコピーを構築するように促されます(オプション1)。
rmpe値は、マイナーが新しいデータを追加する際に既存のパーティションをコピーすることに対するペナルティとして見ることができます。この式では、mを無限大に近づけて処理し、その後異なるn値での効率のトレードオフを考慮します:
- マイナーがほぼ完全なデータセットのコピーを持っている場合、コピーを完成させる報酬が最も高くなります。なぜなら、nがmに近づき、mが無限大に近づくと、rmpeの値は3になるからです。これは、完全なコピーに近い場合、新しいデータを探す効率が既存のデータを再パッケージ化する効率の3倍であることを意味します。
- マイナーが織りネットワーク(Weave)の半分を保存している場合、例えばn=1/2 mのとき、rmpeは2です。これは、新しいデータを探すマイナーの利益が既存のデータをコピーする利益の2倍であることを示しています。
- より低いn値の場合、rmpe値は1より大きくなる傾向があります。これは、唯一のコピーを保存する利益が常に既存のデータをコピーする利益よりも大きいことを意味します。
ネットワークが成長するにつれて(mが無限大に近づく)、マイナーが完全なコピーを構築する動機が強まります。これにより、少なくとも1つのデータセットの完全なコピーを共同で保存する協力マイニンググループの形成が促進されます。
✨✨✨✨✨✨✨✨✨✨✨✨✨✨✨✨✨✨✨✨✨✨
この記事では、Arweave合意プロトコルの構築の詳細を主に紹介しましたが、これはこの部分の核心内容の序章に過ぎません。メカニズムの紹介とコードから、プロトコルの具体的な詳細を非常に直感的に理解できることを願っています。






