
3D生成AI技术:敲开空间智能大门

 2023年苹果发布新一代空间计算平台、头戴显示设备Vision Pro,其远超竞品的配置带来第三次3D热潮。不同于前两次主要基于硬件的热潮,此次热潮有了新的加成——3D生成技术的井喷式发展。受益于更大的数据集Objaverse和Objaverse XL、训练效果更好的表示方式神经场、2D预训练模型
2023年苹果发布新一代空间计算平台、头戴显示设备Vision Pro,其远超竞品的配置带来第三次3D热潮。不同于前两次主要基于硬件的热潮,此次热潮有了新的加成——3D生成技术的井喷式发展。受益于更大的数据集Objaverse和Objaverse XL、训练效果更好的表示方式神经场、2D预训练模型作者:Iris Chen, Dr. Ni

一、AI+3D管线降本增效显著
2022年ChatGPT爆火引发AIGC浪潮,生成式AI对很多行业都产生了颠覆性作用,游戏、影视、3D打印等场景下的3D内容领域也正在生成式AI的作用下重塑行业格局。相比于追求准确性的工业场景CAD、建筑场景BIM,这些场景下的3D内容更追求创作性,生成式AI可以有更大的用武之地。
3D生成技术指利用深度神经网络学习并生成物体或场景的3D模型,并在3D模型的基础上将色彩与光影赋予物体或场景使生成结果更加逼真,包括AI建模、AI骨骼绑定、AI表情、AI动作、AI渲染等研究方向。3D内容产业链包括提供技术的基础层、提供资产的中间层和资产开发的应用层,其中基础层的技术提供方为产业提供生产3D内容的基础工具,3D生成技术主要在该层替代传统生产工具以促进行业发展。

传统3D管线包括概念设计、原画制作、3D建模、纹理贴图、驱动和渲染等环节,其中原画制作、3D建模、纹理贴图等3D相关环节制作周期长、高度依赖人工,是主要研发成本所在。以3D游戏为例,3D游戏中3D相关环节通常会占研发成本的60-70%,其中3D建模环节成本极高,一个十万面以上的3D高模资源,厂商如果委托外包团队生产,价格至少需要3万元,时间需要30-45天,如果在3D资产库购买,除了存在可选资产有限的问题,通常也需要5-10人/天进行清洗才可以使用。据全球最大3D内容公司Sketchfab的数据,3D模型生产大概费用在3-40美元左右,所需时间在2-15小时左右。

生成式AI几乎可以在传统3D管线的所有环节中发挥作用,很多游戏工作室目前已是美术成员人手一个Midjourney和Stable Diffusion,大模型的应用也降低了3D建模的门槛,基于生成式AI的3D管线可降低3D内容的生产成本、提高生产效率。以2024年初大卖的Steam游戏《幻兽帕鲁》为例,一个建模师制作一个帕鲁(游戏中的生物)的3D模型需要一个月,每个帕鲁需要约20个动作,以每天一个动作计算则还需要额外20天,该游戏约有100种帕鲁,按照传统3D管线的生产方式总共需要5000天左右,而工作室利用生成式AI,在3年内完成该作品。
据方正证券的测算,使用RTX 3090显卡在Zero123方法迭代30000次,生成一个3D资产的成本约5元,未来随着方法的发展成熟,迭代速度变快2倍的情况下成本将降至2.6元,且单场景只需要约3.3-4.2小时,相较于前文的3-40美元和2-15小时,生成式AI的应用显著降低了生产成本并提高了生产效率。

二、3D生成技术发展
3D生成技术的研究最开始是在计算机视觉和图形学领域展开,早在1970年MIT教授Berthold K.P. Horn就提出了Shape from shading,基于图像中的明暗信息,借助反射光照模型恢复出3D模型。2023年,3D生成技术出现井喷式发展,生成质量、速度和丰富性都得到大幅提升,契机在于:①3D数据集从早期小规模的ShapeNet到Objaverse(2022年12月)、Objaverse XL(2023年7月),其中0bjaverse-XL数据集包含1020万3D资产,比Objaverse多了一个数量级;②将3D内容表达为神经网络参数的神经场诞生;③2D预训练模型的发展推动多视角重建。
3D生成技术可以划分为3D原生和2D升维两大类发展路线。3D原生通常使用3D数据集进行训练,从训练到推理都基于3D数据,从文字/图像直接生成3D内容,而可学习的3D数据集十分有限,即使是最大的开源3D数据集Objaverse-XL的数据量也只有2D数据集的一个零头。为解决这一问题,部分研究尝试使用2D数据集进行训练,从文字先到2D图像,再通过扩散模型或者NeRF模型生成3D内容,此为2D升维。

1、 3D原生路线
3D原生路线使用3D数据集进行训练,实现从文字/图片输入直接到3D内容的生成。主要优劣势在于:
l 优势
生成质量高:由于使用的是3D数据集,在特定范围内针对性强,能够生成质量较高的3D内容,比如通过高质量的3D人脸数据可以训练出4k以上高质量的3D人脸,同时避免了2D升维的多面问题。
生成速度快:2D升维通常利用扩散模型或者NeRF模型来指导3D表示的优化,需要多步迭代导致耗时长,而3D原生可直接由文字/图片进行3D生成。
兼容性强:通常有几何和纹理的分别生成,可以直接在标准图形引擎中进行后续编辑。
l 劣势
丰富性不足:缺乏高质量、大规模的3D数据集,且数据质量和一致性较差,制约了模型想象力,难以生成数据集中没有见过的物品或组合。
3D原生早期使用的方法有VAE模型、流模型、GAN模型、EBM模型等,其中GAN模型在生成效果方面的优势使其在2022年前一直是3D原生的主流模型,但由于GAN存在训练病态问题,很难在不存在规范坐标系的数据上进行训练,训练难度极大且对硬件要求极高。2022年9月,Nvidia发布Get3D,可以生成具有高保真纹理和复杂几何细节的3D内容。之后,OpenAI发布Point-E和Shap-E,打破3D数据和字幕的数量限制,收集了数百万个3D资源和相应文本字幕,支持大词汇量的3D生成。近期大火的LRM通过结合高效的神经网络架构和大规模的多视角数据集,实现了从单张图像到高保真3D模型的快速转换,DMV3D提出T步骤扩散模型对LRM进行改进实现了更高质量的结果生成。

2022年9月,Nvidia发布Get3D。Get3D的生成过程分为两个部分:①几何分支部分,可以输出任意拓扑结构的表面网格;②纹理分支部分,产生纹理场以实现在表面点上进行查询。
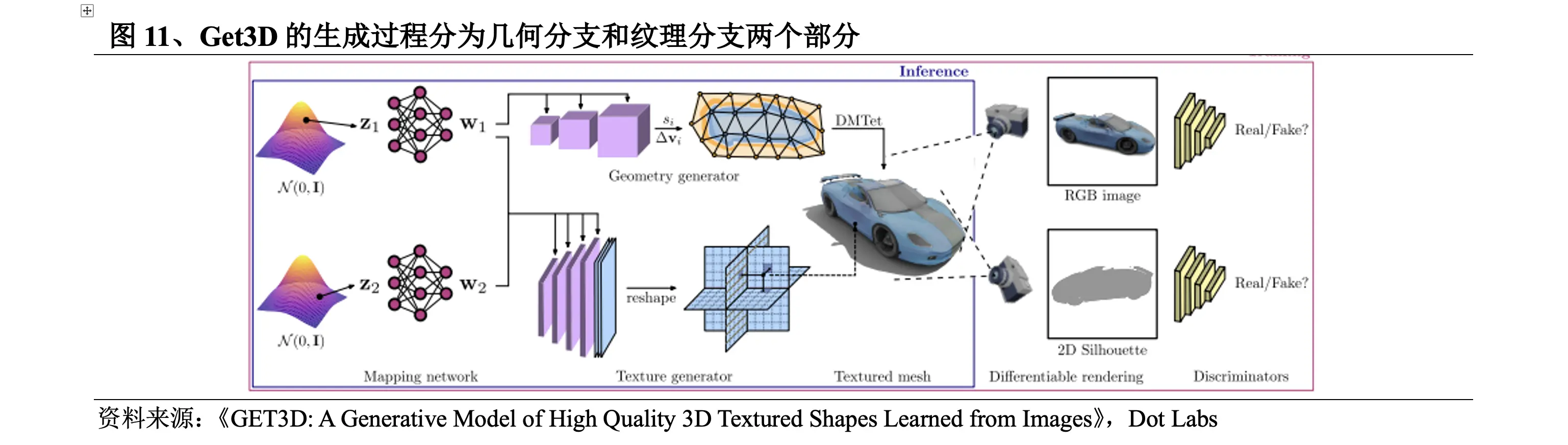
该方法的具体突破在于:
l 在该方法出现之前,3D生成技术生成的内容缺乏几何细节和纹理。而在Get3D的生成过程下,其3D内容的几何细节更加丰富,且可以带纹理。
l 当时最先进的反向渲染方法也只能一次构建一个3D物体。而在单个Nvidia的GPU上训练,Get3D每秒可以生成大约20个对象,且所学习的训练数据集越大、越多样化,输出的多样性和详细程度就越高,Nvidia研究团队称,仅用2天时间就使用A100 GPU在大约100万张图像上训练了模型。
l 可以根据受训练时使用的数据生成几乎无限量的3D内容。例如,学习2D汽车图像的数据集,Get3D可以创建轿车、卡车、赛车和面包车等系列集。

2023年5月,OpenAI发布Shap-E,在其Point-E的基础上进行提升。Shap-E流程为:①训练一个编码器生成隐式表征;②在编码器产生的潜表征上训练扩散模型。

l Shap-E使用隐式表示法生成既有神经场又有纹理网格的3D模型,可以轻松导入到3D软件中进行后续处理。相比其他方法,Get3D只能生成网格,Point-E只能生成点云。
l 在使用大型3D和文本对应数据集进行训练后,Shap-E可以在几秒钟内生成复杂且多样化的3D模型,在推理速度上比Point-E快,且比其他方法快几个数量级。
但是和Point-E存在的问题一样,Shap-E的样本质量较差,编码器有时会丢失详细的纹理。

2023年11月,Adobe研究院和澳大利亚国立大学的研究团队介绍了一种创新的大型重建模型LRM。该方法流程为:①应用预先训练过的视觉模型DINO对输入的图像进行编码;②图像特征由大型Transformer解码器通过交叉注意力投影到3D三平面空间,使用NeRF模型进行表示;③使用多层感知器MLP预测体积渲染的点颜色和密度。

l 耗时短。2D升维主要利用扩散模型通过优化算法优化3D表示,推理即训练,耗时很长,其他3D原生方法是在3D表示上训练扩散模型,推理需要迭代多步,耗时较长。而LRM是训练回归模型,直接一步推理出3D表示,可在短短5秒内从单张输入图像中生成高保真度的3D物体模型。
l 强通用性。与过去在小数据集上以特定类别进行训练的方法不同,LRM采用了高度可扩展的基于transformer的架构,具有5亿个可学习参数,并使用Objaverse和MVImgNet数据集中约100万个3D对象进行端到端训练,具有很强的通用性。
l 处理真实场景图片。LRM使用户可以从智能手机拍摄的照片中生成高质量的3D模型,扩展了3D建模的民主化,打开了无限创意和商业可能。
LRM是第一个大型重建模型,其突破性在于其快速、高效地生成高质量的3D图像,为增强现实、虚拟现实系统、游戏、影视动画和工业设计等领域带来了转变。其在生成速度和质量上的显著优势掀起了3D生成技术领域的重建模型潮,很多工作在LRM的基础上进行改进,重建模型大量涌现。
2D升维路线使用2D数据集进行训练,先从文字到2D图像,再通过扩散模型或者NeRF模型生成3D内容。主要优劣势在于:
l 优势
丰富性强:可以利用大量的2D图像数据进行预训练,生成的3D模型复杂度提高,富有想象力。
l 劣势
生成质量低:受限于采样数量、视角数量及计算资源的平衡,目前2D升维方法在分辨率、纹理细节上都较粗糙,且扩散模型的3D先验能力不足,生成结果易出现几何结构不合理问题。
生成速度慢:NeRF的训练和推理过程都需要大量计算资源,需要对3D空间进行密集的采样,耗费时间。
兼容性弱:NeRF格式无法直接在Unity等3D引擎中进行后续编辑,需要通过Matching cubes等转换成3D网格再到3D引擎中进行编辑,兼容性较弱。
2018年,将3D内容表达为神经网络参数的神经场诞生,虽然神经场表达的仍然是3D数据,且由于缺乏学习数据在2018-2020年期间发展缓慢,但为2D升维奠定了技术基础。2020年,伯克利、谷歌与加大圣地亚哥分校的联合团队提出NeRF算法,生成的图像精度高且可以生成大场景的3D感知图像,大大加速了2D升维的发展,但由于训练难度大、对硬件要求高、生成效率低等问题,仅能进行试验性与娱乐性的小范围应用。2022年,以Stable Diffusion、Dall·E为代表的2D图像生成应用快速发展,提升了2D升维的商业化价值,技术发展再次提速。具体技术的发展上,2D升维的最初探索是Google2021年末发布的DreamFields,其于2022年9月发布在此基础上改进的DreamFusion,利用Imagen扩散模型计算损失和SDS方法进行采样,显著提高了文本到3D的质量。之后,Nvidia发布Magic3D,引入两阶段的优化策略提高生成速度和质量。ProlificDreamer采用VSD解决SDS方法过饱和、过平滑和低多样性的问题。DreamGaussian将3D高斯整合到3D内容的创建中,此后3D高斯在很大程度上替代了NeRF,近半年出现大量基于3D高斯的系列改进工作。
2022年9月,Google发布DreamFusion,在其DreamFields的基础上进行提升。DreamFusion流程为:①用NeRF在预定的机位渲染图片,和高斯分布混合得到加噪图片;②将图片输入Imagen扩散模型,采用类似于NeRF的随机权重初始化模型;③反复渲染的视图作为环绕Imagen的SDS函数的输入。该方法的具体突破在于:
l 通过文本到图像的Imagen扩散模型来计算损失以替代CLIP,相当于一个由扩散模型优化之后的NeRF,对3D模型进行了优化。
l 使用新的图像采样方法SDS,在参数空间而不是像素空间中进行采样,由于参数限制生成的图像质量走向可以很好控制。
l 在生成图像的过程中,参数会经过优化成为扩散模型的一个训练样本,经过扩散模型训练之后的参数具备多尺度特性,更利于后续的图像生成,且扩散模型能够直接预测更新的方向则不需要反向传播。
虽然DreamFusion提升了3D模型的结构准确性与渲染的真实性,但其生成3D内容要进行1.5万次的优化,每个模型生成要1.5小时,耗时太长,在规模、渲染与结构细节方面难以满足产业级应用的要求。

2022年11月,Nvidia发布Magic3D,在DreamFusion的基础上进行两阶段优化。Magic3D流程为:①低分辨率优化。通过重复采样和渲染低分辨率图像计算SDS损失,采用其3D重建模型Instant NGP给出结果,使用DMTet提取初始3D mesh作为第二阶段的输入;②高分辨率优化。用同样方法对高分辨率图像进行采样和渲染,并使用相同方法进行更新得到最终结果。与DreamFusion相比,该方法的具体突破在于:
l 生成质量更高。Magic3D的分辨率比DreamFusion高8倍,具体效果上Magic3D的生成结果也更加细节。
l 生成速度更快。Magic3D可以在40分钟内创建高质量的3D网格模型,比DreamFusion快2倍。
l 衔接更好。由于Magic3D的渲染方式与传统计算机图形学有非常紧密的关系,且其生成结果可以直接在标准的图像软件中进行查看,因此可以更好地与传统3D生成工作进行衔接,已具备进行产业应用的能力基础。

2023年9月,来自百度、南洋理工和北大的作者共同发布DreamGaussian。DreamGaussian流程为:①在UV空间使用3D Gaussian Splatting建模文本或图像指示的内容;②使用SDS Loss进行优化并提取纹理网格;③通过多轮计算MSE Loss细化网格上图像的纹理。与基于NeRF的方法相比,该方法的具体突破在于:
l 生成质量更高。DreamGaussian设计了从3D高斯提取网格的算法和UV空间纹理细化阶段,进一步提高了生成质量。
l 生成速度更快。通过将高斯分割适应生成设置,显著减少了2D升维方法的生成时间,DreamGaussian可以在2分钟内从单视图图像生成具有明确网格和纹理映射的3D内容,相较于现有方法加速了约10倍。

前期的2D升维方法主要利用2D数据集进行训练,只能提炼有限的3D几何知识。2023年3月,哥伦比亚大学刘若石博士发表Zero123,探索到将3D信息注入2D预训练模型中,可以有效弥补扩散模型3D先验能力不足的问题。于是,生成多个视角的图像后通过3D重建的方法得到3D模型的多视角重建方法兴起。之后,在Zero123的基础上,加州大学圣地亚戈分校苏昊教授团队提出了One-2-3-45和One-2-3-45++,借助扩散模型实现更好的生成泛化性,同时利用有限的3D数据实现相对正确的几何结构,以及字节跳动发布MVDream、VAST发布Wonder3D、Meta发布MVDiffusion++。

2023年3月,哥伦比亚大学的研究团队发布Zero123。Zero123流程为:①输入单个RGB图像进行编码;②对噪声图像进行去噪;③选择另外的摄像机视角生成新视角图像;④把这些多视角图片加入扩散模型进行训练并3D重建。该方法的具体突破在于:虽然颠倒了3D重建和新视图合成的顺序,但保留了输入图像中所描述对象的身份,以至可以利用旋转物体时的概率生成模型,来模拟自遮挡引起的随机不确定性,有效利用了扩散模型学习到的语义和几何先验,扩散模型在训练过程中已经知道3D物体多个角度的真实样子,可以更好猜测物体另外角度样子。

2023年8月,字节跳动发布MVDream。MVDream流程为:①通过在自注意力层中连接不同的视图来将原始的2D自注意力层转换为3D,并为每个视图添加相机嵌入;②使用多视角扩散模型作为3D优化的先验,并通过SDS进行3D生成。该方法的具体突破在于:
l 通过利用在大规模网络数据集上预训练的图像扩散模型以及从3D资源渲染的多视图数据集,得到的多视图扩散模型既能够实现2D扩散的通用性,又能够实现3D数据的一致性。相对于当前开源的2D升维方法,可以获得更好的稳定性和质量。
l 多视角扩散模型可以在少样本设置下进行训练微调,允许用户进行个性化的3D生成。

三、2D升维方法商业化可期
通过不断地发展和完善,3D生成技术在生成质量、速度和丰富性已取得很大进步,若能更好地解决以下问题,3D生成技术将有十分值得期待的未来:
l 数据集。训练数据不足是制约3D生成技术发展的重要原因,主要由于:①3D数据集的生产历史很短;②3D资产通常需要3D设计师花费大量时间使用专业软件进行创建;③由于使用场景和创作者风格的不同,3D资产在规模、质量和风格上存在很大差异,从而增加了3D数据的复杂性;④3D数据获取不便,大量3D数据分散在了游戏公司、影视特效公司和个人建模师的手里难以收集。探索如何利用2D数据进行3D生成是解决方案之一,但大规模、高质量的3D数据集仍然非常必要。
l 表示方式。3D生成技术中,隐式表示能够有效地建模复杂的几何拓扑结构,但优化速度慢,显式表示有助于快速优化收敛,但难以封装复杂的拓扑结构,并需要大量的存储资源,开发一种可以同时具有高训练效率和高精细度的表示方式,3D生成效果会更上一个台阶。
l 评估体系。全面评估生成的3D内容需要理解其物理属性和预期设计,目前对3D内容质量的评估主要依赖人工评分,开发能全面衡量几何和纹理保真度的稳健指标,可以推动3D生成技术的优化工作。
l 可控性。3D生成技术的目的是以廉价和可控的方式生成大量用户友好、高质量和多样化的3D内容,但是将生成的3D内容嵌入到实际应用中时,兼容性问题不利于3D设计师交互和编辑,且生成内容的风格受到训练数据集的限制,统一通过不同方法制作的3D内容并建立包含丰富编辑功能的工具链以增强技术的可控性非常必要。
对不同3D生成技术的生成质量、生成速度和丰富性进行比较可以发现,这些方法在以上三者之间存在一个“不可能三角”:3D原生路线的方法使用3D数据集,基本上保证了质量和速度,但是在丰富性上由于数据集过小而存在明显短板,2D升维路线的方法使用2D数据集,能够很好地满足丰富性要求,既有Zero123这样生成质量让人亮眼的方法,也有DreamGaussian这种在生成速度上追求极致的方法。
“不可能三角”让3D生成技术在商业化进程中面临较大挑战。对于面向专业人士的场景,在生成质量上有较高要求,如工业、建筑业与医疗需要3D生成高度准确,对于面向普通消费者的场景,更强调生成速度。3D原生方法在生成质量和速度上的优势更接近商业化的要求,可实现特定场景下的先行商业化。例如影眸科技的Dreamface已经可以在游戏领域替代一部分前期建模的工作,Get3D正在一些元宇宙类场景里进行简单物品生成。相比之下,2D升维方法离商业化更远一些,但能看到2023年下半年以来大量2D升维相关学术成果发布,2D升维方法在生成质量、生成速度上都有不同程度的显著提升,可以预期未来一年内,2D升维有机会在一些对生成质量要求不苛刻的场景初步落地,比如元宇宙、VR家装等。

四、头显完善开拓无限潜力
虽然现有3D生成技术还存在一些问题,但不可否认的是,3D生成的未来应用空间巨大,主要集中在3D打印、游戏、影视等领域。据Wohlers Report的数据,2022年全球3D打印总产值182亿美元,同比增长18%,增速持续保持高位,预计2031年市场规模将达到853亿美元,据Newzoo的预测,全球VR游戏市场规模在2024年可达32亿美元。在其下游3D内容应用领域的发展下,3D生成技术拥有广阔的需求和市场期待。
而从长期的视角来看,3D生成的更大潜力空间在于头显设备的完善。硬件是技术的载体,硬件的发展会促进技术的发展。头显设备的完善有望带来3D原生应用爆发,开发者可以借助3D生成技术开发头显应用,促进头显设备生态走向成熟。虽然从用户反馈来看,初代设备Vision Pro还有很多不尽如人意之处,但借鉴智能手机的发展历史,预计应用爆发会在3-5年内实现,从中可以窥探到的未来依旧值得兴奋。

五、3D生成初创企业入局市场
解决3D生成技术的问题并不能简单依靠发几篇论文,更需要对3D工业标准和专业用户需求有清晰的认知。除了Nvidia、OpenAI、Google等大型科技企业外,在3D生成领域,一些新兴的3D生成创业公司也在可用性方面做了很多工作,最终效果不一定比巨头差,他们的表现和未来值得市场期待。
l CSM(Common Sense Machines):2020年成立于美国马萨诸塞州,由前Google DeepMind高级研究科学家Tejas Kulkarni和麻省理工博士研究员、红杉资本的侦察投资者Max Kleiman-Weiner共同创立。该公司提供了一个平台CSM.ai,允许用户将照片、文本和手绘草图转换为完全实现的3D世界。CSM创新地提出了不同于显示游戏引擎和隐式游戏引擎的第三种框架——结合高度灵活性和可控性的隐式学习游戏引擎,开发了基于扩散的实时渲染引擎,推出快速生成高分辨率3D资产和自定义风格图像的Cube应用。在三轮融资中已筹集了1010万美元。
l Luma:2021年由前苹果AR/CV工程师Amit Jain、伯克利实验室负责人Alberto Taiuti和Alex Yu共同创立,总部位于美国加州,旨在通过AI简化3D图像和视频的创建过程,核心技术基于NeRF。其今年1月发布的Genie 1.0可在10秒内根据文本生成3D模型,其本月推出的革命性AI视频生成器Dream Machine,可以根据文本和图像创建高质量、逼真的视频,且速度快至120秒内120帧。凭借出色的技术实力和广阔的市场前景,Luma已经成功筹集了超过7000万美元的资金,主要投资者包括Andreessen Horowitz、Matrix Partners和Amplify Partners等知名风投公司。截至2024年,Luma的估值已达到3亿美元。
l Polycam:2021年成立于美国加州,其APP允许用户利用iPhone的LiDAR和摄像头生成3D模型。推出AI Texture Generato用于创建3D纹理、免费的3D高斯溅射创建者和查看器用于3D高斯溅射重建。Polycam拥有近10万名付费客户,APP下载量已超过1000万次,制作了超过2000万个3D模型,执行了超过5000万次3D编辑工作。其收入从2021年的28万美元增长至2022年的180万美元,2023年飙升至650万美元,今年上半年已超400万美元,预计全年收入将再创新高。完成了1800万美元的A轮融资,投资方为Left Lane Capital、Adjacent、Adobe Ventures、YouTube联合创始人Chad Hurley。
l Yellow:成立于2023年的3D角色生成公司,由A16z提供500万美元的种子资金支持,其CEO Mandeep Waraich曾是Google大模型和Core ML产品负责人,大部分团队成员拥有麻省理工、牛津、斯坦福等名校背景。已发布第一个产品YellowSculpt,实现了拓扑感知的3D生成,使其更易于使用和编辑。虽然目前大多数生成式AI技术都会产生刚性对象,但Yellow的结构化网格生成会产生易于设置动画的3D模型,且生成的网格可以与Unity、Unreal和Roblox等顶级游戏引擎或Daz Studio、Maya和Blender等其他3D创作工具无缝集成。2024年1月与Daz Studio的开发商Tafi建立了独家合作关系,Yellow可以利用Daz的3D库以安全的方式训练模型。
六、3D生成加码空间智能时代
空间智能是一个支持实时渲染的3D虚拟环境,需要身份认证、数据确权、资产交易、监管治理等作为支撑,而Web 3的去中心化思想恰好为其提供了一个安全、可靠且公开的基础设施环境,空间智能也将成为Web 3大规模应用的重要场景,Web 3与空间智能在相互促进的发展中到来,空间智能中重要的3D生成技术在Web 3的互联网环境下将拥有广阔的应用和发展空间。
1、 Lifeform:视觉DID先驱引领Web 3破圈机遇
在Web 3和空间智能的风口,数字虚拟身份成为行业内关键且缺乏的基础设施。Lifeform是去中心化数字身份(DID)解决方案的先驱提供商,为Web 3用户提供数字虚拟身份,并用来登录任何DApp和元宇宙,有望实现区块链互操作性,为Web 3带来破圈式的发展机遇。项目在一年间进行了4亿美元总估值的两轮融资,投资机构包括币安、IDG Capital、GeekCartel,上线174天就在Twitter收获了10万关注量,现月交易量已超350万美元,约占BSC市场份额的35%,仅次于OpenSea,其代币LFT今年5月上线Bybit、KuCoin。
l 视觉DID以提升心理体验。已有的DID是在链上保存用户的个人信息,通过NFT或SBT等方式来实现钱包与链上身份的绑定,而Lifeform采用视觉DID,除了兼容DID标准之外,还为用户提供虚拟人编辑器及相应的DID协议、智能合约等,允许用户以可视化的3D虚拟人物形象参与元宇宙活动,提升用户的视觉和心理体验。
l 超百亿组合满足个性化需求。Lifeform的产品AvatarID有基于UE5的Hyper-Realistic和卡通风格的Cartoon Version两种,其虚拟人编辑包含7个创建部件,每个部件拥有超过1000个组件,用户可以创建超过100亿个头像组合,且还提供大量模板以降低用户的制作难度,制作完成后支持形成NFT。
l 通用域名确保跨链可用。与依赖于不同区块链而限制了跨链能力和应用范围的其他DID解决方案不同,Lifeform创造的通用域名服务,通过.btc后缀简化跨区块链的身份验证和定位,是首个支持多条区块链(比特币、以太坊、BNB Chain、Solana、Base、Avalanche、OPBNB等)的域名解析平台,用户可以完全控制自己的身份信息,确保了数字身份的全球可用性。未来计划与各类钱包合作,将.btc域名SDK接入交易所钱包,以及支持跨多个第1层和第2层网络无缝交互。
2、 Param Labs:模块互联系统创新Web 3游戏生态
Param Labs是一家AAA级游戏和区块链开发工作室,致力于创建模块化、互联的Web3游戏生态系统,通过赋予用户数字产权确保他们创造的价值能够返还,彻底改变玩家和开发者的游戏体验。项目现已完成700万美元融资,由Animoca Brands领投,Delphi Ventures和Cypher Capital等参投,拥有约90万Twitter关注者、50万Discord用户和30万每日活跃用户,即将在Bitget和Gate.io等交易所推出其代币PARAM。其主要产品有:
l Pixel to Poly:用于大规模生产元宇宙资产的平台,可将用户上传的2D图像转换为高质量、可用于游戏的3D资产,且这些资产可以集成到Fortnite和GTAV等热门游戏中,大大缩短了游戏开发者的制作时间,加速3D游戏行业的资产创造。该平台还有在游戏中使用的独特NFT,为玩家和收藏家提供有价值的数字资产。
l Kiraverse:免费的多人射击游戏,用户可通过导入自定义IP进一步个性化,以获得独特、跨IP和跨生态系统的体验。今年5月宣布与游戏生态系统Pixelverse合作,Pixelverse将把其智慧财产权和角色整合到Kiraverse中,从而增强游戏的叙事并扩展其宇宙。
3、 NeuralAI:开发Bittensor子网革新Web 3 3D生成
NeuralAI利用其$NEURAL生态系统和dapp为用户提供3D资产生成服务,且提供市场允许用户无缝地交易其创作资产。项目正在进行Bittensor子网的开发工作,即将发布第一个dapp,旨在成为3D资产生成的首要Bittensor子网。项目已与世界顶级去中心化计算市场Akash Network达成战略合作,Akash为其提供了56个功能强大的A6000 GPU,可按需扩展。
l LRM模型优化多边形数。NeuralAI使用的主要模型是LRM,其显著优势是能够生成优化多边形数网格,在保留细节的同时具有较少的多边形数,适合在高FPS(画面每秒帧数)下运行,确保模型高效并保持详细,非常适合游戏环境,且允许3D艺术家在后期制作中使用软件操纵和细化网格,或将其直接添加到游戏引擎中。
l Bittensor子网降本3D生成。生成3D资产是资源密集型过程,需要大量的计算能力和人力资源。Bittensor作为一个分散的机器学习网络,可以在全球节点分配大量计算任务,NeuralAI正在Bittensor网络中开发一个专用子网,为3D资产生成提供更好的解决方案。据该项目测算,聘请专业的3D艺术家每小时的费用为30-100美元,对于一个需要10个小时才能创建的复杂资产,则需要300-1000美元,且并不包括软件和硬件的额外管理费用。而在Bittensor子网中,Bittensor会使用代币TAO奖励验证器和矿工,Neural dApp、Neural插件或API的用户可以免费生成3D资产,如果网络的激励措施涵盖了生成3D资产的奖励,那么成本可以节省90-100%。

七、风险提示
风险一:价格波动
- 加密货币价格波动较大,无法保证或预测未来价格
风险2:财务
- 项目可能会破产,或者无法偿还SWEAT本金或利息
风险3:黑客攻击
- SWEAT可能会被恶意行为者窃取,项目方可能无法退还资金
风险4:法律
- 部分国家和地区禁止该类行为,项目方可能无法偿还SWEAT本金或利息







