ABCDE 연구 보고서: 협처리기 및 각 회사의 솔루션 심층 탐구

 시스템은 시장에 있는 몇몇 협처리기 경로의 기술 솔루션 비교를 정리하여, 시장과 사용자에게 협처리 경로에 대한 보다 명확한 인식을 제공하고자 합니다.
시스템은 시장에 있는 몇몇 협처리기 경로의 기술 솔루션 비교를 정리하여, 시장과 사용자에게 협처리 경로에 대한 보다 명확한 인식을 제공하고자 합니다.저자:Kris \& Laobai,ABCDE;Mo Dong,Celer Network
최근 몇 달 동안 협처리기 개념이 뜨거운 관심을 받고 있으며, 이 새로운 ZK 사용 사례는 점점 더 많은 사람들의 주목을 받고 있습니다.
하지만 우리는 대부분의 사람들이 협처리기 개념에 대해 여전히 상대적으로 낯설다는 것을 발견했습니다. 특히 협처리기의 정확한 정의 --- 협처리기가 무엇인지, 무엇이 아닌지에 대한 이해가 아직 모호합니다. 시중에 있는 몇몇 협처리기 기술 솔루션의 비교에 대해서도 체계적으로 정리된 바가 없으므로, 이 글은 시장과 사용자에게 협처리기 트랙에 대한 보다 명확한 인식을 제공하고자 합니다.
1. 협처리기 Co-Processor는 무엇이며, 무엇이 아닙니까?
비기술자나 개발자가 협처리기를 한 문장으로 설명해야 한다면, 어떻게 설명하시겠습니까?
저는 박사님이 말씀하신 이 문장이 표준 답변에 매우 가깝다고 생각합니다 --- 협처리기는 간단히 말해 "스마트 계약에 Dune Analytics의 능력을 부여하는 것"입니다.
이 문장은 어떻게 해석할 수 있을까요?
Dune을 사용하는 상황을 상상해 보세요 --- Uniswap V3에서 LP를 하여 수수료를 벌고 싶습니다. 그래서 Dune을 열고 최근 Uniswap의 다양한 거래 쌍의 거래량, 수수료의 최근 7일 APR, 주요 거래 쌍의 상하 변동 범위 등을 찾습니다…
또는 StepN이 인기를 끌던 시절, 당신은 신발을 사고 팔기 시작했지만 언제 팔아야 할지 확신이 서지 않아 매일 Dune에서 StepN의 데이터를 주시합니다. 일일 거래량, 신규 사용자 수, 신발의 바닥 가격 등을 살펴보며 성장 둔화나 하락 추세가 나타나면 즉시 팔기로 결심합니다.
물론, 당신만 이러한 데이터를 주시하는 것은 아닙니다. Uniswap과 StepN의 개발 팀도 이러한 데이터에 주목하고 있습니다.
이 데이터는 매우 의미가 있습니다 --- 트렌드 변화를 판단하는 데 도움을 줄 뿐만 아니라, 인터넷 대기업들이 자주 사용하는 "빅데이터" 접근 방식처럼 더 많은 변화를 만들어낼 수 있습니다.
예를 들어, 사용자가 자주 거래하는 신발 스타일과 가격에 따라 유사한 신발을 추천합니다.
또는 사용자가 창세 신발을 보유한 기간에 따라 "사용자 충성도 보상 프로그램"을 도입하여 충성 고객에게 더 많은 에어드롭이나 혜택을 제공합니다.
또는 Uniswap에서 LP 또는 트레이더가 제공하는 TVL 또는 거래량에 따라 Cex와 유사한 VIP 프로그램을 도입하여 트레이더에게 거래 수수료 면제 또는 LP 수수료 비율 증가의 혜택을 제공합니다…
이때 문제가 발생합니다 --- 인터넷 대기업이 빅데이터와 AI를 활용하는 것은 기본적으로 블랙박스이며, 어떻게든 할 수 있지만 사용자는 이를 볼 수 없고 신경 쓰지 않습니다.
하지만 Web3에서는 투명성과 신뢰를 거부하는 것이 우리의 본질적인 정치적 올바름입니다!
따라서 위의 상황을 실현하고자 할 때, 당신은 두 가지 선택의 딜레마에 직면하게 됩니다 --- 하나는 중앙화된 수단을 통해 "백엔드 수동"으로 Dune에서 이러한 인덱스 데이터를 통계 내고 배포 및 실행하는 것이고, 다른 하나는 스마트 계약을 작성하여 자동으로 체인에서 이러한 데이터를 가져오고 계산하여 자동으로 배포하는 것입니다.
전자는 "정치적으로 올바르지 않은" 신뢰 문제에 빠지게 됩니다.
후자는 체인에서 발생하는 가스 비용이 천문학적인 숫자가 될 것이며, 당신(프로젝트 측)의 지갑은 이를 감당할 수 없습니다.
이때 협처리기가 등장하게 됩니다. 방금 언급한 두 가지 방법을 결합하고, "백엔드 수동" 단계를 기술적으로 "자기 증명"하여, 즉 ZK 기술을 통해 체외의 "인덱스 + 계산" 부분을 "자기 증명"한 후 이를 스마트 계약에 전달함으로써 신뢰 문제를 해결하고 대량의 가스 비용도 사라지게 됩니다. 완벽합니다!
왜 "협처리기"라고 불리나요? 사실 이는 Web2.0 발전 역사에서 "GPU"에서 유래되었습니다. GPU가 당시 독립적인 계산 하드웨어로 도입된 이유는 CPU가 근본적으로 처리하기 어려운 계산, 예를 들어 대규모 병렬 반복 계산, 그래픽 계산 등을 처리할 수 있는 설계 구조 때문입니다. 이러한 "협처리기" 구조 덕분에 오늘날 우리는 멋진 CG 영화, 게임, AI 모델 등을 갖게 되었으며, 이러한 협처리기 구조는 실제로 계산 시스템 아키텍처의 비약적인 발전입니다. 현재 각 협처리기 팀은 이러한 구조를 Web3.0에 도입하고자 하며, 여기서 블록체인은 Web3.0의 CPU와 유사합니다. L1이든 L2이든 이러한 "무거운 데이터"와 "복잡한 계산 논리" 작업에 본질적으로 적합하지 않기 때문에 블록체인 협처리기를 도입하여 이러한 계산을 처리함으로써 블록체인 응용 프로그램의 가능성을 크게 확장하고자 합니다.
따라서 협처리기가 하는 일을 요약하면 두 가지입니다:
블록체인에서 데이터를 가져오고, ZK를 통해 내가 가져온 데이터가 진짜임을 증명합니다, 조작이 없습니다;
방금 가져온 데이터를 기반으로 적절한 계산을 수행하고, 다시 ZK를 통해 내가 계산한 결과도 진짜임을 증명합니다, 조작이 없습니다. 계산 결과는 스마트 계약에서 "저비용 + 신뢰 없는" 호출이 가능합니다.
최근 Starkware에서 Storage Proof라는 개념이 뜨고 있으며, 이는 기본적으로 단계 1을 수행합니다. Herodotus, Langrage 등 많은 ZK 기술 기반의 크로스 체인 브릿지 기술의 핵심도 단계 1에 있습니다.
협처리기는 단계 1이 완료된 후 단계 2를 추가하여 신뢰 없는 데이터 추출 후 신뢰 없는 계산을 수행하면 됩니다.
따라서 기술적으로 좀 더 정확하게 표현하자면, 협처리기는 Storage Proof/State Proof의 슈퍼셋이며, Verifiable Computation(검증 가능한 계산)의 서브셋입니다.
하나 주의할 점은, 협처리기는 Rollup이 아닙니다.
기술적으로 볼 때, Rollup의 ZK 증명은 위의 단계 2와 유사하며, 단계 1 "데이터 가져오기" 과정은 Sequencer를 통해 직접 구현됩니다. 비록 탈중앙화된 Sequencer라도, 이는 어떤 경쟁이나 합의 메커니즘을 통해 데이터를 가져오는 것이지 Storage Proof와 같은 ZK 형태가 아닙니다. 더 중요한 것은 ZK Rollup은 계산 계층 외에도 L1 블록체인과 유사한 저장 계층을 구현해야 하며, 이 저장은 영구적으로 존재합니다. 반면 ZK Coprocessor는 "무상태"로, 계산이 완료된 후 모든 상태를 보존할 필요가 없습니다.
응용 시나리오 측면에서 협처리기는 모든 Layer1/Layer2의 서비스형 플러그인으로 볼 수 있으며, Rollup은 새로운 실행 계층을 생성하여 결제 계층의 확장을 돕습니다.
2. 왜 ZK를 사용해야 하며, OP로는 안 됩니까?
위의 내용을 읽고 나면, 협처리기는 꼭 ZK를 사용해야 하는지 의문이 생길 수 있습니다. 마치 "ZK가 추가된 Graph"처럼 들리며, 우리는 Graph의 결과에 대해 큰 의심을 하지 않는 것 같습니다.
그렇게 말할 수 있는 이유는, 평소에 Graph를 사용할 때 실제 돈과 관련이 없기 때문입니다. 이러한 인덱스는 오프체인 서비스에 의해 제공되며, 프론트엔드 사용자 인터페이스에서 볼 수 있는 거래량, 거래 이력 등의 데이터는 여러 데이터 인덱스 제공업체를 통해 제공되지만, 이러한 데이터를 스마트 계약에 다시 넣는 것은 불가능합니다. 왜냐하면 데이터를 다시 넣으면 이 인덱스 서비스에 대한 추가적인 신뢰를 요구하게 되기 때문입니다. 데이터가 실제 돈, 특히 대규모 TVL과 연결될 때 이러한 추가 신뢰가 중요해집니다. 친구가 당신에게 100원을 빌려달라고 하면, 당신은 눈 하나 깜짝하지 않고 빌려줄 수 있지만, 1만 원, 심지어 100만 원을 요청할 때는 어떻게 될까요?
하지만 다시 말해, 협처리기에서 모든 시나리오가 정말로 ZK를 사용해야 하는 것일까요? 결국 Rollup에는 OP와 ZK 두 가지 기술 경로가 있으며, 최근 유행하는 ZKML에도 해당하는 OPML 개념이 제안되었습니다. 그렇다면 협처리기에도 OP의 분기가 있을까요? 예를 들어 OP-Coprocessor 같은 것이요?
사실 그렇게 존재합니다 --- 하지만 구체적인 세부사항은 비밀로 하겠습니다. 곧 더 자세한 정보를 발표할 예정입니다.
3. 협처리기, 어느 회사가 강한가 --- 시중에 있는 몇 가지 협처리기 기술 솔루션 비교
Brevis
Brevis의 아키텍처는 세 가지 구성 요소로 이루어져 있습니다: zkFabric, zkQueryNet 및 zkAggregatorRollup.
아래는 Brevis의 아키텍처 다이어그램입니다:
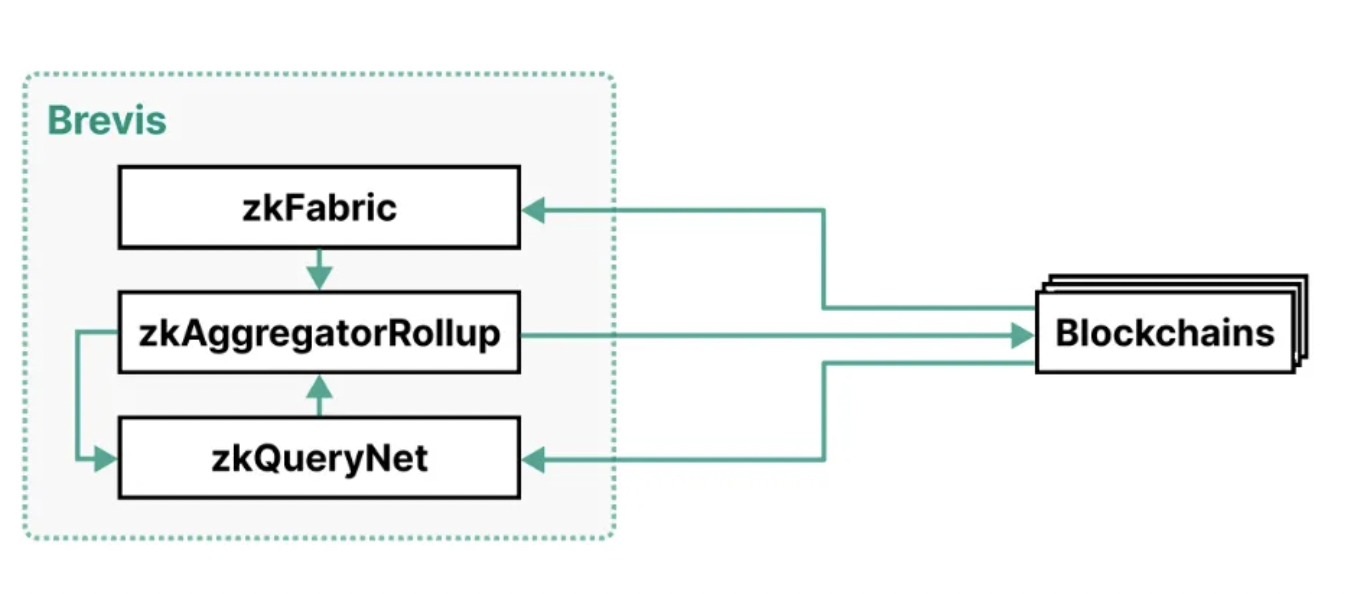
zkFabric: 모든 연결된 블록체인에서 블록 헤드를 수집하고, 이러한 블록 헤드의 유효성을 증명하는 ZK 합의 증명을 생성합니다. zkFabric을 통해 Brevis는 다중 체인 상호 운용이 가능한 협처리기를 구현하여 한 블록체인이 다른 블록체인의 모든 역사적 데이터에 접근할 수 있게 합니다.
zkQueryNet: dApp의 데이터 쿼리를 수용하고 이를 처리하는 개방형 ZK 쿼리 엔진 시장입니다. 데이터 쿼리는 zkFabric에서 검증된 블록 헤드를 사용하여 이러한 쿼리를 처리하고 ZK 쿼리 증명을 생성합니다. 이러한 엔진은 고도로 전문화된 기능과 일반화된 쿼리 언어를 갖추고 있어 다양한 응용 요구를 충족할 수 있습니다.
zkAggregatorRollup: zkFabric과 zkQueryNet의 집계 및 저장 계층 역할을 하는 ZK 집합 블록체인입니다. 이 블록체인은 두 구성 요소에서 오는 증명을 검증하고, 검증된 데이터를 저장하며, zk 검증된 상태 루트를 모든 연결된 블록체인에 제출합니다.
ZK Fabric은 블록 헤드에 대한 증명을 생성하는 핵심 부분으로, 이 부분의 안전성을 보장하는 것이 매우 중요합니다. 아래는 zkFabric의 아키텍처 다이어그램입니다:
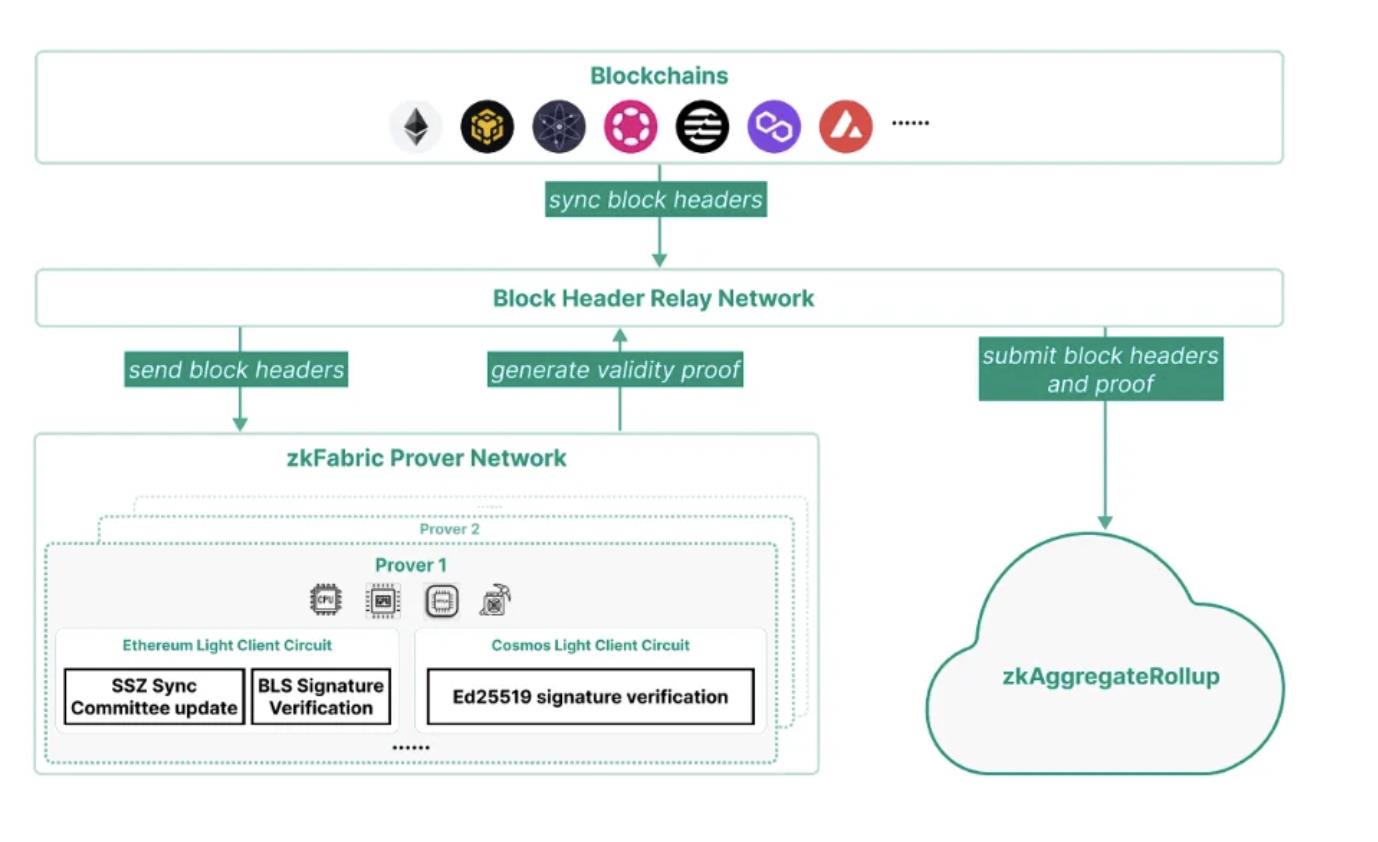
zkFabric은 제로 지식 증명(ZKP)을 기반으로 한 경량 클라이언트로, 완전히 신뢰할 필요가 없으며, 외부 검증 엔티티에 의존하지 않습니다. 그 안전성은 완전히 기본 블록체인과 수학적으로 신뢰할 수 있는 증명에서 비롯됩니다.
zkFabric Prover 네트워크는 각 블록체인의 라이트 클라이언트 프로토콜을 위한 회로를 구현하며, 이 네트워크는 블록 헤드의 유효성 증명을 생성합니다. 증명자는 GPU, FPGA 및 ASIC과 같은 가속기를 활용하여 증명 시간과 비용을 최소화합니다.
zkFabric은 블록체인과 기본 암호화 프로토콜의 안전 가정에 의존합니다. 그러나 zkFabric의 유효성을 보장하기 위해서는 최소한 하나의 정직한 중계기가 올바른 포크를 동기화해야 합니다. 따라서 zkFabric은 단일 중계기 대신 탈중앙화된 중계 네트워크를 채택하여 zkFabric의 유효성을 최적화합니다. 이 중계 네트워크는 Celer 네트워크의 상태 모니터링 네트워크와 같은 기존 구조를 활용할 수 있습니다.
증명자 할당: 증명자 네트워크는 분산된 ZKP 증명자 네트워크로, 각 증명 생성 작업에 대해 증명자를 선택하고 이들에게 비용을 지불해야 합니다.
현재 배포:
현재 이더리움 PoS, Cosmos Tendermint 및 BNB 체인을 포함한 다양한 블록체인에 대해 라이트 클라이언트 프로토콜이 구현되어 있으며, 이는 예시 및 개념 증명으로 사용됩니다.
Brevis는 현재 uniswap hook과 협력하고 있으며, hook은 사용자 정의 uniswap 풀을 크게 추가했습니다. 그러나 CEX와 비교할 때 UnisWap은 여전히 대규모 사용자 거래 데이터(예: 거래량 기반 충성도 프로그램)에 의존하는 기능을 생성하는 데 효과적인 데이터 처리 기능이 부족합니다.
Brevis의 도움으로 hook은 이 도전을 해결했습니다. hook은 이제 사용자 또는 LP의 전체 역사적 체인 데이터에서 읽을 수 있으며, 완전히 신뢰 없는 방식으로 사용자 정의 계산을 실행할 수 있습니다.
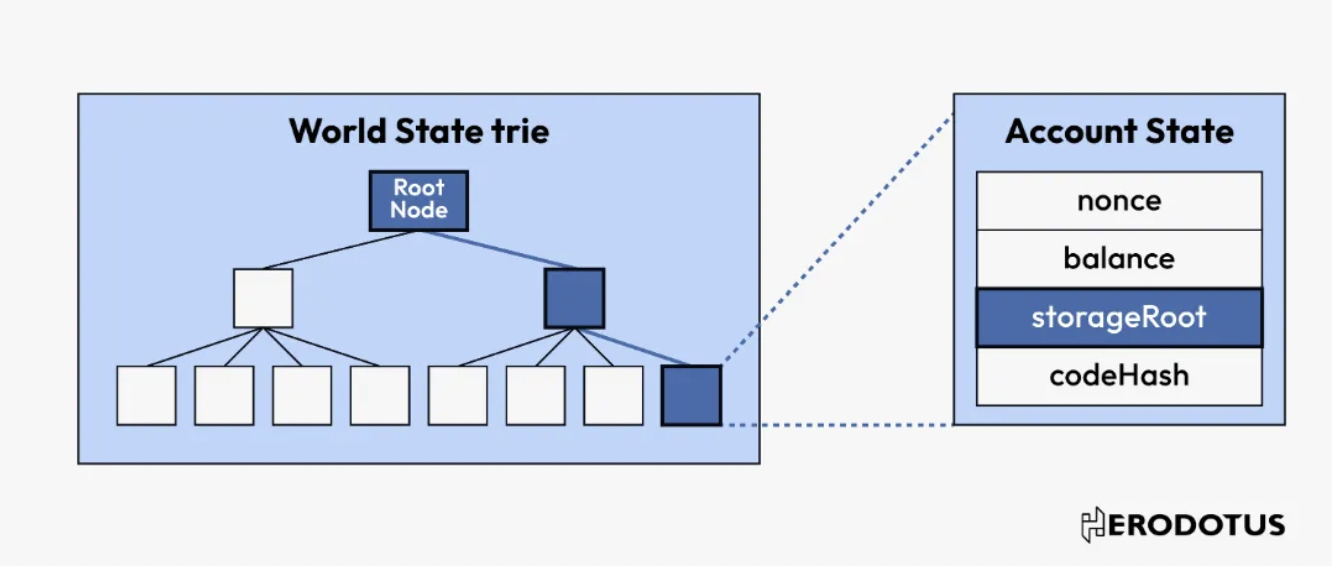
Herodotus
Herodotus는 스마트 계약에 다음과 같은 이더리움 레이어 간 동기화 접근 기능을 제공하는 강력한 데이터 접근 미들웨어입니다:
L2에서 L1 상태
L1 및 다른 L2에서 L2 상태
L3/App-Chain 상태를 L2 및 L1으로
Herodotus는 저장 증명이라는 개념을 제안하며, 저장 증명은 데이터의 존재를 확인하는 증명과 다단계 워크플로우의 실행을 검증하는 계산 증명을 결합하여 대규모 데이터 세트(예: 전체 이더리움 블록체인 또는 롤업)에서 하나 이상의 요소의 유효성을 증명합니다.
블록체인의 핵심은 데이터베이스이며, 그 데이터는 Merkle 트리, Merkle Patricia 트리 등의 데이터 구조를 사용하여 암호화 보호됩니다. 이러한 데이터 구조의 독특한 점은 데이터가 안전하게 제출되면 해당 데이터가 구조 내에 포함되어 있다는 것을 확인하는 증거를 생성할 수 있다는 것입니다.
Merkle 트리와 Merkle Patricia 트리의 사용은 이더리움 블록체인의 보안을 강화합니다. 트리의 각 수준에서 데이터에 대해 암호화 해시를 수행함으로써, 데이터가 변경되는 것은 거의 불가능합니다. 데이터 포인트의 변경은 트리에서 해당 해시 값을 루트 해시 값으로 변경해야 하며, 이는 블록체인 헤더에서 공개적으로 확인할 수 있습니다. 블록체인의 이러한 기본 특성은 높은 수준의 데이터 무결성과 불변성을 제공합니다.
둘째로, 이러한 트리는 포함 증명을 통해 유효한 데이터 검증을 수행할 수 있습니다. 예를 들어, 거래의 포함 여부나 계약의 상태를 검증할 때 전체 이더리움 블록체인을 검색할 필요 없이 관련 Merkle 트리 내의 경로만 검증하면 됩니다.
Herodotus가 정의한 저장 증명은 다음의 융합입니다:
포함 증명: 이러한 증명은 암호화 데이터 구조(예: Merkle 트리 또는 Merkle Patricia 트리) 내에서 특정 데이터의 존재를 확인하여 관련 데이터가 데이터 세트에 실제로 존재함을 보장합니다.
계산 증명: 다단계 워크플로우의 실행을 검증하여 대규모 데이터 세트에서 하나 이상의 요소의 유효성을 증명합니다. 데이터의 존재를 나타내는 것 외에도, 해당 데이터에 적용된 변환이나 작업을 검증합니다.
제로 지식 증명: 스마트 계약이 필요로 하는 상호작용 데이터의 양을 간소화합니다. 제로 지식 증명은 스마트 계약이 모든 기본 데이터를 처리하지 않고도 청구의 유효성을 확인할 수 있게 합니다.
워크플로우
- 블록 해시 얻기
블록체인上的每个数据都属于特定的区块。区块哈希作为该区块的唯一标识符,通过区块头来总结其所有内容。在存储证明的工作流程中,首先需要确定和验证包含我们感兴趣的数据的区块的区块哈希,这是整个过程中的首要步骤。
- 获得区块头
一旦获得了相关的区块散列,下一步就是访问区块头。为此,需要与上一步获取的区块哈希值相关联的区块头进行哈希处理。然后,将提供的区块头的哈希值与所得的区块哈希值进行比较:
取得哈希的方式有两种:
(1)使用 BLOCKHASH opcode 来检索
(2)从 Block Hash Accumulator 来查询历史中已经被验证过的区块的哈希
这一步骤可确保正在处理的区块头是真实的。该步骤完成后,智能合约就可以访问区块头中的任何值。
- 确定所需的根 ( 可选)
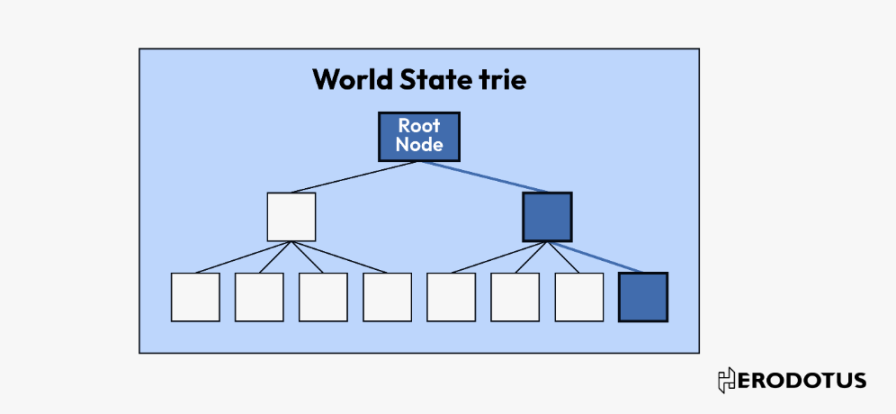
有了区块头,我们就可以深入研究它的内容,特别是:
stateRoot: 区块链发生时整个区块链状态的加密摘要。
receiptsRoot: 区块中所有交易结果(收据)的加密摘要。
事务根(transactionsRoot): 区块中发生的所有交易的加密摘要。
跟可以被解码,使得能够核实区块中是否包含特定账户、收据或交易。
- 根据所选根来验证数据(可选)
 有了我们所选的根,并考虑到以太坊采用的是 Merkle-Patricia Trie 结构,我们就可以利用 Merkle 包含证明来验证树中是否存在数据。验证步骤将根据数据和区块内数据的深度而有所不同。
有了我们所选的根,并考虑到以太坊采用的是 Merkle-Patricia Trie 结构,我们就可以利用 Merkle 包含证明来验证树中是否存在数据。验证步骤将根据数据和区块内数据的深度而有所不同。
目前支持的网络:
From Ethereum to Starknet
From Ethereum Goerli* to Starknet Goerli*
From Ethereum Goerli* to zkSync Era Goerli*
Axiom
Axiom 提供了一种方式可以让开发人员从以太坊的整个历史记录中查询区块头,帐户或存储值。AXIOM 引入了一种基于密码学的链接的新方法。Axiom 返回的所有结果均通过零知识证明在链上验证,这意味着智能合约可以在没有其他信任假设的情况下使用它们。
Axiom 最近发布了Halo2-repl ,是一个基于浏览器的用 Javascript 编写的 halo2 REPL。这使得开发人员只需使用标准的 Javascript 就能编写 ZK 电路,而无需学习 Rust 等新语言、安装证明库或处理依赖关系。
Axiom 由两个主要技术组件组成:
- AxiomV1 --- 以太坊区块链缓存,从 Genesis 开始。
- AxiomV1Query --- 执行针对 AxiomV1 查询的智能合约。
(1)在 AxiomV1 中缓存区块哈希值:
AxiomV1 智能合约以两种形式缓存自创世区块以来的以太坊区块哈希:
首先, 缓存了连续 1024 个区块哈希的 Keccak Merkle 根。这些 Merkle 根通过 ZK 证明进行更新,验证区块头哈希是否形成以 EVM 直接可访问的最近 256 个区块之一或已存在于 AxiomV1 缓存中的区块哈希为结束的承诺链。
其次。Axiom 从创世区块开始存储这些 Merkle 根的 Merkle Mountain Range。该 Merkle Mountain Range 是在链上构建的,通过对缓存的第一部分 Keccak Merkle 根进行更新。
(2)在 AxiomV1Query 中履行查询:
AxiomV1Query 智能合约用于批量查询,以实现对历史以太坊区块头、账户和账户存储的任意数据的无信任访问。查询可以在链上进行,并且通过针对 AxiomV1 缓存的区块哈希进行的 ZK 证明来在链上完成。
这些 ZK 证明检查相关的链上数据是否直接位于区块头中,或者位于区块的账户或存储 Trie 中,通过验证 Merkle-Patricia Trie 的包含(或不包含)证明来实现。
Nexus
Nexus 试图利用零知识证明为可验证的云计算搭建一个通用平台。目前是 machine archetechture agnostic 的,对 risc 5/ WebAssembly/ EVM 都支持。Nexus 利用的是 supernova 的证明系统,团队测试生成证明所需的内存为 6GB,未来还会在此基础上优化使得普通的用户端设备电脑可以生成证明。
确切的说,架构分为两部分:
Nexus zero:由零知识证明和通用 zkVM 支持的去中心化可验证云计算网络。
Nexus: 由多方计算、状态机复制和通用 WASM 虚拟机驱动的分散式可验证云计算网络。
Nexus 和 Nexus Zero 应用程序可以用传统编程语言编写,目前支持 Rust,以后将会支持更多的语言。
Nexus 应用程序在去中心化云计算网络中运行,该网络本质上是一种直接连接到以太坊的通用 「无服务器区块链」。因此,Nexus 应用程序并不继承以太坊的安全性,但作为交换,由于其网络规模缩小,可以获得更高的计算能力(如计算、存储和事件驱动 I/O)。Nexus 应用程序在专用云上运行,该云可达成内部共识,并通过以太坊内部可验证的全网阈值签名提供可验证计算的 「证明」(而非真正的证明)。
Nexus Zero 应用程序确实继承了以太坊的安全性,因为它们是带有零知识证明的通用程序,可以在 BN-254 椭圆曲线上进行链上验证。
由于 Nexus 可在复制环境中运行任何确定性 WASM 二进制文件,预计它将被用作证明生成应用的有效性 / 分散性 / 容错性来源,包括 zk-rollup 排序器、乐观的 rollup 排序器和其他证明器,如 Nexus Zero 的 zkVM 本身。