
読み取り、インデックスから分析へ、Web3データインデックス分野の概要

 本文は、ブロックチェーンデータのアクセス可能性の発展の歴史を探討し、The Graph、Chainbase、Space and Timeの三つのデータサービスプロトコルのアーキテクチャとAI技術の応用の特徴を比較し、ブロックチェーンデータサービスがスマート化と安全化の方向に発展していることを指摘し、今後も業界のインフラとして重要な役割を果たすことを示しています。
本文は、ブロックチェーンデータのアクセス可能性の発展の歴史を探討し、The Graph、Chainbase、Space and Timeの三つのデータサービスプロトコルのアーキテクチャとAI技術の応用の特徴を比較し、ブロックチェーンデータサービスがスマート化と安全化の方向に発展していることを指摘し、今後も業界のインフラとして重要な役割を果たすことを示しています。# 1 はじめに
2017年の最初の波のdApp Etheroll、ETHLend、CryptoKittiesから始まり、現在ではさまざまなブロックチェーンに基づく金融、ゲーム、ソーシャルdAppが花盛りです。私たちが分散型のオンチェーンアプリケーションについて話すとき、これらのdAppがインタラクションで採用しているさまざまなデータの出所について考えたことはありますか?
2024年、ホットな話題はAIとWeb3に集中しています。人工知能の世界では、データはその成長と進化の生命源のようなものです。植物が太陽光と水分に依存して成長するように、AIシステムも膨大なデータに依存して「学習」し「考える」ことを続けます。データがなければ、AIのアルゴリズムがどれほど巧妙であっても、空中楼閣に過ぎず、その知能と効率を発揮することはできません。
この記事では、ブロックチェーンデータの可用性(Data Accessibility)の観点から、業界の発展過程におけるブロックチェーンデータインデックスの進化を深く分析し、老舗データインデックスプロトコルThe Graphと新興のブロックチェーンデータサービスプロトコルChainbaseおよびSpace and Timeを比較し、特にAI技術を組み合わせたこれら2つの新しいプロトコルのデータサービスと製品アーキテクチャの特徴の違いについて探ります。
# 2 データインデックスの複雑さと単純さ:ブロックチェーンノードから全チェーンデータベースへ
## 2.1 データの出所:ブロックチェーンノード
「ブロックチェーンとは何か」を理解し始めたとき、私たちはよくこのような言葉を目にします:ブロックチェーンは分散型の帳簿です。ブロックチェーンノードは、ブロックチェーンネットワーク全体の基盤であり、オンチェーンのすべての取引データを記録、保存、伝播する責任を担っています。各ノードは完全なブロックチェーンデータのコピーを持ち、ネットワークの分散型特性を維持します。しかし、一般のユーザーにとって、自分でブロックチェーンノードを構築し維持することは容易ではありません。専門的な技術能力が必要であり、高額なハードウェアと帯域幅のコストが伴います。また、一般的なノードのクエリ能力も限られており、開発者が必要とする形式でデータをクエリすることはできません。したがって、理論的には誰でも自分のノードを運営できますが、実際にはユーザーは通常、第三者サービスに依存する傾向があります。
この問題を解決するために、RPC(リモートプロシージャコール)ノードプロバイダーが登場しました。これらのプロバイダーはノードのコストと管理を担当し、RPCエンドポイントを通じてデータを提供します。これにより、ユーザーは自分でノードを構築することなく、簡単にブロックチェーンデータにアクセスできるようになります。公共のRPCエンドポイントは無料ですが、速度制限があり、dAppのユーザー体験に悪影響を及ぼす可能性があります。プライベートRPCエンドポイントは混雑を減らすことでより良いパフォーマンスを提供しますが、単純なデータ取得でも大量の往復通信が必要です。これにより、リクエストが重くなり、複雑なデータクエリの効率が低下します。さらに、プライベートRPCエンドポイントは通常、拡張が難しく、異なるネットワーク間の互換性が欠けています。しかし、ノードプロバイダーの標準化されたAPIインターフェースは、ユーザーがオンチェーンデータにアクセスするためのハードルを下げ、後続のデータ解析とアプリケーションの基盤を築きました。
## 2.2 データ解析:原型データから利用可能なデータへ
ブロックチェーンノードから取得したデータは、しばしば暗号化され、コーディング処理された原始データです。これらのデータはブロックチェーンの完全性と安全性を保持していますが、その複雑さはデータ解析の難易度を増加させます。一般のユーザーや開発者にとって、これらの原型データを直接処理するには大量の技術知識と計算リソースが必要です。
この背景の中で、データ解析のプロセスは特に重要です。複雑な原型データを解析し、理解しやすく操作しやすい形式に変換することで、ユーザーはこれらのデータをより直感的に理解し、利用できるようになります。データ解析の成功は、ブロックチェーンデータアプリケーションの効率と効果を直接決定する重要なステップです。
## 2.3 データインデクサーの進化
ブロックチェーンデータの量が増加するにつれて、データインデクサーの需要も高まっています。インデクサーは、オンチェーンデータを整理し、データベースに送信してクエリを容易にする上で重要な役割を果たします。インデクサーの動作原理は、ブロックチェーンデータをインデックスし、SQLのようなクエリ言語(GraphQLなどのAPI)を通じていつでも利用できるようにすることです。クエリデータの統一インターフェースを提供することで、インデクサーは開発者が標準化されたクエリ言語を使用して迅速かつ正確に必要な情報を取得できるようにし、プロセスを大幅に簡素化します。
さまざまなタイプのインデクサーは、さまざまな方法でデータ取得を最適化します:
- 完全ノードインデクサー:これらのインデクサーは完全なブロックチェーンノードを運営し、そこから直接データを抽出します。データの完全性と正確性を確保しますが、大量のストレージと処理能力が必要です。
- 軽量インデクサー:これらのインデクサーは、完全ノードから必要に応じて特定のデータを取得し、ストレージ要件を減少させますが、クエリ時間が増加する可能性があります。
- 専用インデクサー:これらのインデクサーは特定のタイプのデータや特定のブロックチェーンに特化しており、NFTデータやDeFi取引など特定のユースケースの取得を最適化します。
- 集約インデクサー:これらのインデクサーは、複数のブロックチェーンやソースからデータを抽出し、オフチェーン情報を含めて、統一されたクエリインターフェースを提供します。これはマルチチェーンdAppに特に有用です。
現在、イーサリアムアーカイブノード(Archive Node)はGethクライアントのアーカイブモードで約13.5TBのストレージスペースを占有しており、Erigonクライアントではアーカイブ要件が約3TBです。ブロックチェーンが成長するにつれて、アーカイブノードのデータストレージ量も増加します。このような膨大なデータ量に直面して、主流のインデクサープロトコルはマルチチェーンインデックスをサポートするだけでなく、さまざまなアプリケーションのデータニーズに応じてデータ解析フレームワークをカスタマイズしています。たとえば、The Graphの「サブグラフ」(Subgraph)フレームワークは典型的なケースです。
インデクサーの登場は、データのインデックスとクエリの効率を大幅に向上させました。従来のRPCエンドポイントと比較して、インデクサーは大量のデータを効率的にインデックスし、高速クエリをサポートします。これらのインデクサーは、ユーザーが複雑なクエリを実行し、データを簡単にフィルタリングし、抽出後に分析を行うことを可能にします。さらに、一部のインデクサーは、複数のブロックチェーンからのデータソースを集約し、マルチチェーンdAppで複数のAPIを展開する必要がある問題を回避します。複数のノードで分散して運営することで、インデクサーはより強力なセキュリティとパフォーマンスを提供し、集中型RPCプロバイダーによる中断やダウンタイムのリスクを軽減します。
対照的に、インデクサーは事前に定義されたクエリ言語を通じて、ユーザーが基盤となる複雑なデータを処理することなく、必要な情報を直接取得できるようにします。このメカニズムは、データ取得の効率と信頼性を大幅に向上させ、ブロックチェーンデータアクセスの重要な革新となっています。
## 2.4 全チェーンデータベース:ストリーム優先の整合
インデックスノードを使用してデータをクエリすることは、通常、APIがオンチェーンデータを消化する唯一のポータルとなることを意味します。しかし、プロジェクトが拡張段階に入ると、標準化されたAPIでは提供できない、より柔軟なデータソースが必要になることがよくあります。アプリケーションのニーズが複雑化するにつれて、初級データインデクサーとその標準化されたインデックス形式は、ますます多様化するクエリニーズ(たとえば、検索、クロスチェーンアクセス、オフチェーンデータマッピング)を満たすことが難しくなっています。

現代のデータパイプラインアーキテクチャにおいて、「ストリーム優先」アプローチは、従来のバッチ処理の限界を解決するための一つの手段となり、リアルタイムのデータ取り込み、処理、分析を実現します。このパラダイムの転換により、組織は受信データに即座に反応し、ほぼ瞬時に洞察を得て意思決定を行うことができます。同様に、ブロックチェーンデータサービスプロバイダーの発展も、ブロックチェーンデータストリームの構築に向かっています。従来のインデクサーサービスプロバイダーは、The GraphのSubstreams、GoldskyのMirrorなど、リアルタイムでブロックチェーンデータを取得するためのストリーム方式の製品を次々と発表しています。また、ChainbaseやSubSquidのように、ブロックチェーンに基づいてデータストリームを生成するリアルタイムデータレイクもあります。
これらのサービスは、ブロックチェーン取引のリアルタイム解析とより包括的なクエリ能力の提供に対する需要を解決することを目的としています。「ストリーム優先」アーキテクチャが遅延を低減し、応答能力を強化することで、従来のデータパイプラインにおけるデータ処理と消費の方法を革新したように、これらのブロックチェーンデータストリームサービスプロバイダーも、より高度で成熟したデータソースを通じて、より多くのアプリケーションの発展を支援し、オンチェーンデータ分析を補助することを目指しています。
現代のデータパイプラインの視点からオンチェーンデータの課題を再定義することで、私たちはオンチェーンデータの管理、ストレージ、提供のすべての潜在能力を新たな視点から見ることができます。サブグラフやイーサリアムETLなどのインデクサーをデータパイプライン内のデータストリームとして捉えると、あらゆるビジネスユースケースに合わせて高性能なデータセットをカスタマイズできる可能性のある世界を想像できます。
# 3 AI + データベース? The Graph、Chainbase、Space and Timeの詳細比較
## 3.1 The Graph
The Graphネットワークは、分散型ノードネットワークを通じてマルチチェーンデータのインデックスとクエリサービスを実現し、開発者がブロックチェーンデータを簡単にインデックスし、分散型アプリケーションを構築できるようにします。その主な製品モデルは、データクエリ実行市場とデータインデックスキャッシュ市場であり、これらの市場は本質的にユーザーの製品クエリニーズに応えるものです。データクエリ実行市場は、消費者が必要なデータに対して適切なデータを提供するインデックスノードに対して支払うことを指し、データインデックスキャッシュ市場は、インデックスノードがサブグラフの過去のインデックスの人気、受け取ったクエリ料金、オンチェーンキュレーターのサブグラフ出力の需要に基づいてリソース配分を調整する市場です。
サブグラフ(Subgraphs)は、The Graphネットワークの基本的なデータ構造です。これらは、ブロックチェーンからデータを抽出し、クエリ可能な形式(たとえば、GraphQLスキーマ)に変換する方法を定義します。誰でもサブグラフを作成でき、複数のアプリケーションがこれらのサブグラフを再利用できるため、データの再利用性と使用効率が向上します。
 The Graph製品構造 (出典: The Graphホワイトペーパー)
The Graph製品構造 (出典: The Graphホワイトペーパー)
The Graphネットワークは、インデクサー、キュレーター、委託者、開発者の4つの重要な役割で構成されており、彼らは共同でweb3アプリケーションにデータサポートを提供します。以下はそれぞれの役割です:
- インデクサー(Indexer):インデクサーはThe Graphネットワークのノードオペレーターであり、GRT(The Graphのネイティブトークン)をステーキングしてネットワークに参加し、インデックスとクエリ処理サービスを提供します。
- 委託者(Delegator):委託者は、インデックスノードの運営を支援するためにGRTトークンをステーキングするユーザーです。委託者は、彼らが委託したインデックスノードから一部の報酬を得ます。
- キュレーター(Curator):キュレーターは、どのサブグラフがネットワークにインデックスされるべきかを信号します。キュレーターは、価値のあるサブグラフが優先的に処理されることを確保するのを助けます。
- 開発者(Developer):他の3者が供給側であるのに対し、開発者は需要側であり、The Graphの主要なユーザーです。彼らはサブグラフを作成し、The Graphネットワークに提出し、ネットワークがデータニーズを満たすのを待ちます。

現在、The Graphは完全な分散型サブグラフホスティングサービスに移行しており、さまざまな参加者間で流通する経済的インセンティブがシステムの運営を確保しています:
- インデックスノードの報酬:インデックスノードは、消費者のクエリ料金と一部のGRTトークンブロック報酬を通じて収益を得ます。
- 委託者の報酬:委託者は、彼らが支援するインデックスノードから一部の報酬を得ます。
- キュレーターの報酬:キュレーターが価値のあるサブグラフを信号した場合、彼らはクエリ料金から一部の報酬を得ることができます。
実際、The Graphの製品もAIの波の中で急速に発展しています。The Graphエコシステムのコア開発チームの一つであるSemiotic Labsは、AI技術を利用してインデックス価格設定とユーザーのクエリ体験を最適化することに取り組んでいます。現在、Semiotic Labsが開発したAutoAgora、Allocation Optimizer、AgentCツールは、それぞれエコシステムのパフォーマンスを向上させるためのさまざまな側面で機能しています。
- AutoAgoraは動的価格設定メカニズムを導入し、クエリ量とリソース使用状況に基づいてリアルタイムで価格を調整し、価格設定戦略を最適化し、インデクサーの競争力と収益を最大化します。
- Allocation Optimizerはサブグラフのリソース配分の複雑な問題を解決し、インデクサーがリソースを最適に配置して収益とパフォーマンスを向上させるのを助けます。
- AgentCは実験的なツールで、ユーザーが自然言語を通じてThe Graphのブロックチェーンデータにアクセスできるようにし、ユーザー体験を向上させます。
これらのツールの適用により、The GraphはAIを組み合わせてシステムの知能とユーザーフレンドリーさをさらに向上させました。
## 3.2 Chainbase
Chainbaseは、すべてのブロックチェーンデータを一つのプラットフォームに統合し、開発者がアプリケーションをより簡単に構築し維持できるようにする全チェーンデータネットワークです。その独自の機能には以下が含まれます:
- リアルタイムデータレイク:Chainbaseは、ブロックチェーンデータストリーム専用のリアルタイムデータレイクを提供し、データが生成されると同時に即座にアクセスできるようにします。
- デュアルチェーンアーキテクチャ:ChainbaseはEigenlayer AVSに基づいて実行層を構築し、CometBFTのコンセンサスアルゴリズムと並行するデュアルチェーンアーキテクチャを形成しています。この設計は、クロスチェーンデータのプログラマビリティとコンビナビリティを強化し、高スループット、低遅延、最終性をサポートし、デュアルステーキングモデルを通じてネットワークのセキュリティを向上させます。
- 革新的なデータフォーマット標準:Chainbaseは「manuscripts」と呼ばれる新しいデータフォーマット標準を導入し、暗号業界におけるデータの構造化と利用方法を最適化します。
- 暗号世界モデル:Chainbaseは、その膨大なブロックチェーンデータリソースを活用し、AIモデル技術を組み合わせて、ブロックチェーン取引を効果的に理解、予測し、相互作用するAIモデルを構築しています。現在、基礎版モデルTheiaが一般に提供されています。

これらの機能により、Chainbaseはブロックチェーンインデックスプロトコルの中で際立っており、特にリアルタイムデータの可用性、革新的なデータフォーマット、オンチェーンとオフチェーンデータの組み合わせを通じて、よりインテリジェントなモデルを作成し、洞察力を向上させています。
ChainbaseのAIモデルTheiaは、他のデータサービスプロトコルと差別化する重要なポイントです。TheiaはNVIDIAが開発したDORAモデルに基づき、オンチェーンとオフチェーンデータ、時空間活動を組み合わせて、暗号パターンを学習し分析し、因果推論を通じて応答することで、オンチェーンデータの潜在的な価値と規則を深く掘り下げ、ユーザーによりインテリジェントなデータサービスを提供します。
AIによって強化されたデータサービスにより、Chainbaseは単なるブロックチェーンデータサービスプラットフォームではなく、より競争力のあるインテリジェントなデータサービスプロバイダーとなりました。強力なデータリソースとAIの積極的な分析を通じて、Chainbaseはより広範なデータ洞察を提供し、ユーザーのデータ処理プロセスを最適化することができます。
## 3.3 Space and Time
Space and Time (SxT)は、検証可能な計算層を構築し、分散型データウェアハウス上でゼロ知識証明を拡張することを目指しており、スマートコントラクト、大規模言語モデル、企業に信頼できるデータ処理を提供します。現在、Space and Timeは最新のAラウンドで2000万ドルの資金調達を受けており、Framework Ventures、Lightspeed Faction、Arrington Capital、Hivemind Capitalが主導しています。
データインデックスと検証の分野で、Space and Timeは新しい技術的アプローチであるProof of SQLを導入しました。これは、Space and Timeが開発した革新的なゼロ知識証明(ZKP)技術であり、分散型データウェアハウス上で実行されるSQLクエリが改ざん防止と検証可能であることを保証します。クエリを実行すると、Proof of SQLは暗号証明を生成し、クエリ結果の完全性と正確性を検証します。この証明はクエリ結果に付加され、任意の検証者(スマートコントラクトなど)がデータが処理中に改ざんされていないことを独立して確認できます。従来のブロックチェーンネットワークは通常、データの真実性を検証するためにコンセンサスメカニズムに依存していますが、Space and TimeのProof of SQLはより効率的なデータ検証方法を実現しています。具体的には、Space and Timeのシステムでは、1つのノードがデータの取得を担当し、他のノードがzk技術を通じてそのデータの真実性を検証します。この方法は、コンセンサスメカニズムの下で複数のノードが同じデータを繰り返しインデックスすることによるリソースの浪費を変え、システム全体のパフォーマンスを向上させます。この技術が成熟するにつれて、データの信頼性を重視する一連の従来の業界がブロックチェーン上のデータを使用して製品を構築するための足がかりを提供します。
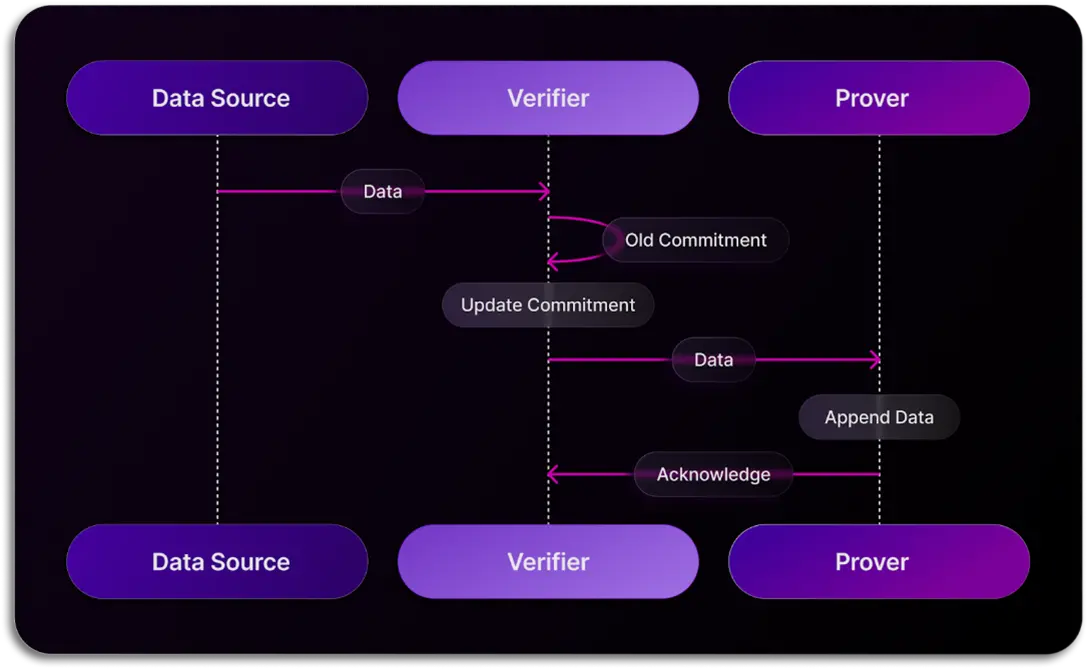
同時に、SxTはMicrosoft AI共同イノベーションラボと密接に協力し、生成的AIツールの開発を加速し、ユーザーが自然言語を通じてブロックチェーンデータにアクセスしやすくしています。現在、Space and Time Studioでは、ユーザーが自然言語クエリを入力し、AIが自動的にそれをSQLに変換し、ユーザーのためにクエリ文を実行して必要な最終結果を提示することができます。
## 3.4 差異対比

# 結論と展望
以上のように、ブロックチェーンデータインデックス技術は、最初のノードデータソースからデータ解析とインデクサーの発展を経て、最終的にAIによって強化された全チェーンデータサービスへと進化し、段階的に改善されてきました。これらの技術の進化は、データアクセスの効率と正確性を向上させるだけでなく、ユーザーに前例のないインテリジェントな体験をもたらしました。
将来を展望すると、AI技術やゼロ知識証明などの新技術の進展に伴い、ブロックチェーンデータサービスはさらにインテリジェントで安全なものになるでしょう。私たちは、ブロックチェーンデータサービスが今後もインフラストラクチャとして重要な役割を果たし、業界の進歩と革新を強力に支援することを信じる理由があります。





