
対話 0G Labs:DA 終局の道とチェーン上の AI 新時代

 初のモジュール式AIチェーンの野望と夢。
初のモジュール式AIチェーンの野望と夢。編訳:思考が独特な、BlockBeats
翻訳者注:今年の3月、0G LabsはHack VCがリードした3500万ドルのプレシードラウンドの資金調達を完了しました。0G Labsは、開発者が高性能でプログラム可能なデータ可用性層の上にAI dAppを展開できるようにするための最初のモジュラーAIチェーンを構築することを目指しています。革新的なシステム設計を通じて、0G Labsは毎秒GBレベルのチェーン上データ転送を実現し、AIモデルのトレーニングなどの高性能アプリケーションシナリオをサポートすることを目指しています。
DealFlow第4期ポッドキャスト番組では、BSCN編集長のJonny Huang、MH Venturesの一般パートナーKamran Iqbal、Animoca Brandsの投資および戦略的提携責任者Mehdi Farooqが共同で0G Labsの共同創業者兼CEOのMichael Heinrichにインタビューしました。Michaelは、マイクロソフトやSAPラボでのソフトウェアエンジニアから、評価額10億ドルを超えるWeb2企業Gartenの創設、そして現在は0Gに全力投球している経歴を共有しました。議論の内容は、DAの現状とビジョン、モジュール化の利点、チーム管理、Web3とAIの相互依存関係を含んでいます。未来を見据え、彼はAIが主流となり、巨大な社会変革をもたらすことを強調し、Web3がこのトレンドに追いつく必要があると述べました。

以下はインタビューの本文です:
Web2ユニコーンのリーダーが再起業
Jonny :今日は重要なトピック、データ可用性(DA)、特に暗号AI分野におけるデータ可用性について深く掘り下げていきます。Michael、あなたの会社はこの分野で大きな発言権を持っています。詳細に入る前に、あなたの職業背景と、どのようにこのニッチな分野に入ったのかを簡単に紹介してください。
Michael :私は最初、マイクロソフトとSAPラボでソフトウェアエンジニアおよび技術プロダクトマネージャーとして働き、Visual Studioチームで最先端技術に取り組んでいました。その後、ビジネスサイドに転向し、ベイン社で数年間働いた後、コネチカット州に移り、ブリッジウォーター社でポートフォリオ構築を担当しました。毎日約600億ドルの取引をレビューし、多くのリスク指標を理解しました。例えば、取引先リスクを評価するためにCDSレートを確認するなど。この経験により、伝統的な金融について深く理解することができました。
その後、スタンフォードに戻って大学院に進学し、最初のWeb2企業Gartenを設立しました。会社のピーク時には、従業員数が650人に達し、年収は1億ドル、総資金調達額は約1.3億ドルに達し、評価額10億ドルを超えるユニコーン企業となり、Y Combinatorのスター企業となりました。
2022年末、スタンフォードの同級生Thomasが私に連絡をくれました。彼は5年前にConfluxに投資したことを話し、Ming WuとFan Longが彼が支援した中で最も優れたエンジニアだと考えており、私たち4人で集まって何か火花を散らせることができるか見てみようと言いました。6ヶ月の交流を経て、私も同じ結論に達しました。「わあ、MingとFanは私が一緒に働いた中で最も優れたエンジニアとコンピュータサイエンティストだ。私たちは一緒に起業しなければならない。」私はGartenの会長に転向し、全力で0Gに取り組むことにしました。

0G Labsの4人の共同創業者、左からFan Long、Thomas Yao、Michael Heinrich、Ming Wu
DAの現状、課題と最終目標
Jonny :これは私が聞いた中で最も素晴らしい創業者の紹介の一つです。あなたたちのVC資金調達プロセスは非常にスムーズだったと推測します。データ可用性というトピックに深く掘り下げる前に、まずDAの現状について話したいと思います。いくつかのプレイヤーはよく知られていますが、現時点であなたはDAの状況をどのように評価しますか?
Michael :DAには現在、さまざまなソースがあり、具体的にはブロックチェーンによって異なります。例えば、イーサリアムのDankshardingアップグレード前、イーサリアムのDAは毎秒約0.08MBでした。その後、Celestia、EigenDA、Availが市場に登場し、これらのスループットは通常毎秒1.2MBから10MBの間です。問題は、AIアプリケーションやチェーン上のゲームアプリケーションにとって、このスループットは非常に不十分であるということです。私たちが議論すべきは、毎秒GBレベルであり、毎秒MBレベルのDAではありません。例えば、チェーン上でAIモデルをトレーニングしたい場合、実際には毎秒50GBから100GBのデータ転送量が必要です。これは桁違いの差です。この機会を見て、Web2の大規模アプリケーションが同じ性能とコストでチェーン上に構築できるようにするためのブレークスルーをどのように創出するかを考えています。これはこの分野で見られる大きな空白です。さらに、いくつかの問題が十分に考慮されていません。例えば、私たちはデータ可用性をデータの公開とデータの保存の組み合わせと考えています。私たちの核心的な洞察は、データをこの2つのチャネルに分けることで、システム内のブロードキャストボトルネックを回避し、画期的な性能改善を実現することです。
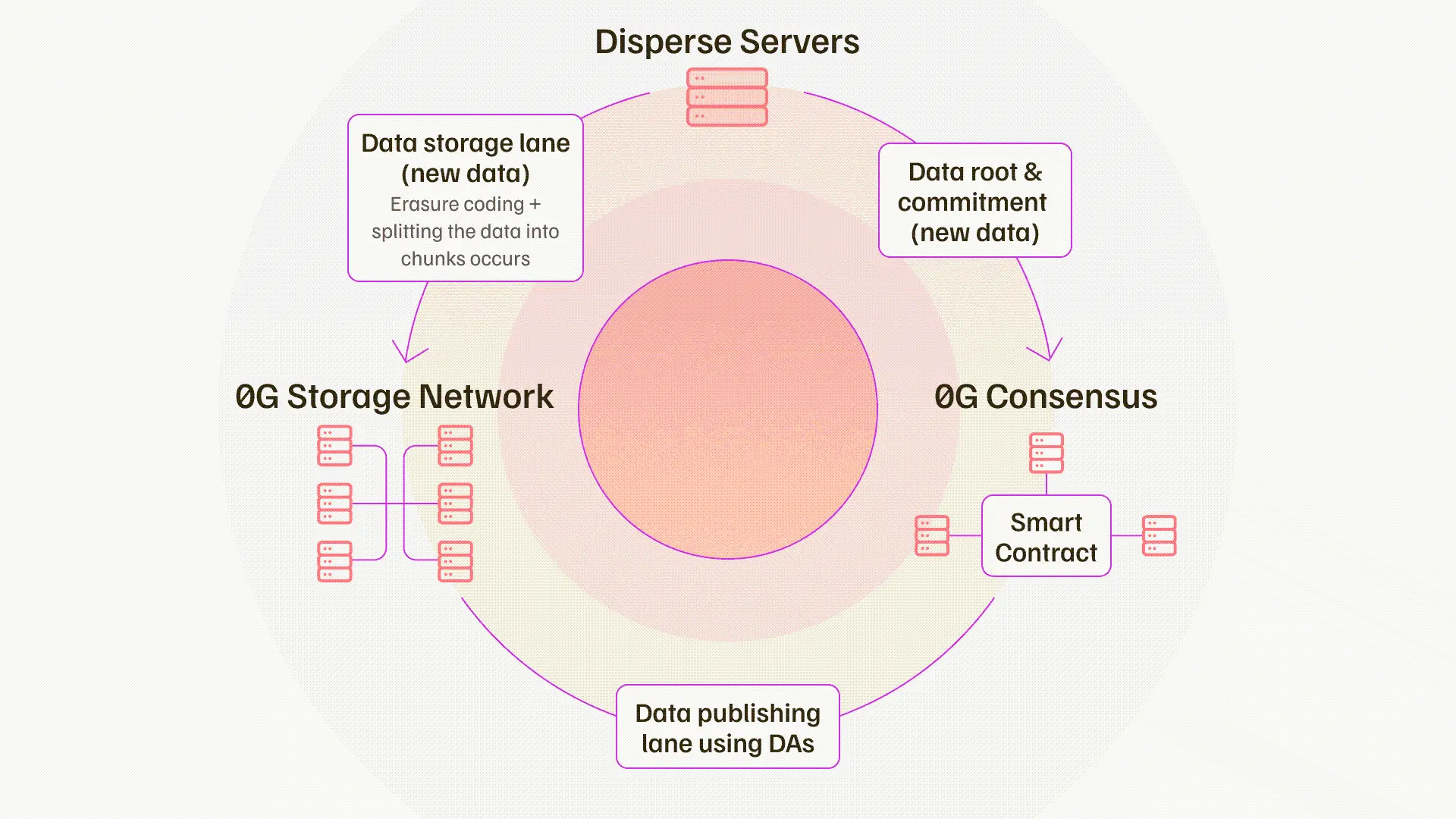
追加のストレージネットワークは、モデルのストレージ、特定のユースケースに対するトレーニングデータのストレージ、さらにはプログラム可能性など、多くのことを可能にします。完全な状態管理を行い、データをどこに保存するか、どのくらいの期間保存するか、どれだけのセキュリティが必要かを決定できます。したがって、さまざまな分野で本当に必要とされる実際のユースケースが、今や可能になっています。
現在のDAの状況は、私たちが大きな進展を遂げ、毎秒0.08MBから1.4MBに向上し、確かに取引コストを削減し、場合によっては99%も削減したことです。しかし、未来の世界の真の需要にはまだ不十分です。高性能AIアプリケーション、チェーン上のゲーム、高頻度DeFi、これらすべてのアプリケーションは、より高いスループットを必要としています。
Mehdi :私は2つの基本的な質問があります。まずはストレージについてです。あなたはL2の取引履歴やAIモデルの履歴について言及しました。ストレージに関して、データをどのくらいの期間保存する必要がありますか?これが私の最初の質問です。次の質問は、すでにArweaveやFilecoinのような分散型ストレージネットワークが存在しますが、これらがスループットの向上に役立つと思いますか?私が言いたいのは、データの公開ではなく、ストレージのことです。
Michael :データの保存期間は、その目的によって異なります。災害復旧を考慮する場合、データは状態を再構築できるように永久に保存されるべきです。楽観的ロールアップのような詐欺証明ウィンドウがある場合、少なくとも7日間は保存する必要があります。その他のタイプのロールアップでは、保存期間は短くなる可能性があります。具体的な状況は異なりますが、大体はこのようなものです。
他のストレージプラットフォームについては、私たちは内部でストレージシステムを構築することを選択しました。なぜなら、ArweaveやFilecoinは主にログタイプのストレージ、つまり長期的なコールドストレージのために設計されているからです。したがって、非常に迅速なデータの書き込みと読み取りのためには設計されておらず、これはAIアプリケーションやキー・バリュー・ストレージまたはトランザクション型データタイプの構造化データアプリケーションにとって非常に重要です。これにより、迅速な処理が可能になり、分散型のGoogleドキュメントアプリケーションを構築することもできます。
Jonny :DAがなぜ必要なのか、そして既存の分散型ストレージソリューションがなぜこの特定のシナリオに適していないのかについて、あなたは非常に明確に説明しました。データ可用性の最終目標について議論できますか?
Michael :最終目標は簡単に定義できます。私たちが実現したいのは、Web2と同等の性能とコストで、チェーン上に何かを構築することが可能になること、特にAIアプリケーションにおいてです。これは非常に明白です。AWSには計算とストレージがあり、S3は重要なコンポーネントです。データ可用性には異なる特性がありますが、これも重要なコンポーネントです。私たちの最終目標は、モジュラーAI技術スタックを構築することであり、そのデータ可用性部分にはデータの公開だけでなく、ストレージコンポーネントも含まれ、コンセンサスネットワークによって統合されます。私たちはコンセンサスネットワークにデータ可用性のサンプリングを処理させ、合意が得られたら、基盤となるLayer 1(例えばイーサリアム)で証明を行います。私たちの最終目標は、あらゆる高性能アプリケーションを実行できるチェーン上システムを構築することであり、さらにはチェーン上でAIモデルをトレーニングすることをサポートすることです。
Kamran :あなたたちのターゲット市場についてもう少し詳しく説明してもらえますか?人工知能やブロックチェーン上でAIアプリケーションを構築している人々以外に、どのようなプロジェクトに0Gを使用してほしいと考えていますか?
Michael :あなたはすでに一つのアプリケーション分野に言及しました。私たちは最大の分散型AIコミュニティを構築するために努力しており、多くのプロジェクトが私たちの上に構築されることを望んでいます。Pondが大規模なグラフモデルを構築している場合でも、Fraction AIやPublicAIが分散型データのアノテーションやクレンジングを行っている場合でも、Allora、Talus Network、Ritualのような実行層プロジェクトでも、私たちはAIビルダーのために最大のコミュニティを構築するために努力しています。これは私たちにとって基本的な要件です。
しかし実際には、あらゆる高性能アプリケーションが私たちの上に構築できます。チェーン上のゲームを例に挙げると、5000人のユーザーが非圧縮状態で完全なチェーン上ゲーム状態を実現するには、毎秒16MBのデータ可用性が必要です。現在、どのDA層もこれを実現できていません。おそらくSolanaは可能ですが、それはイーサリアムエコシステムとは異なり、サポートも限られています。したがって、そのようなアプリケーションは私たちにとって非常に興味深いものであり、特にそれらがチェーン上のAIエージェント(例えばNPC)と組み合わさる場合には、多くの交差アプリケーションの潜在能力があります。
高頻度DeFiはもう一つの例です。未来の全同態暗号(FHE)、データ市場、高頻度深端アプリケーション、これらすべては非常に大きなデータスループットを必要とし、高性能を実際にサポートできるDA層が必要です。したがって、あらゆる高性能のDA ppやLayer2は私たちの上に構築できます。
モジュール化の利点:柔軟な選択
Mehdi :あなたたちはスケーラビリティ、スループットの向上、ストレージコンポーネントによる状態膨張問題の解決に取り組んでいます。なぜ完全なLayer1を直接立ち上げないのですか?もし技術的にブレークスルーを達成できる能力があるなら、なぜモジュール化のアプローチを採用するのですか?モジュール化スタックの背後にある論理は何ですか?
Michael :根本的に言えば、私たちの基盤はLayer1ですが、私たちはモジュール化がアプリケーションを構築する未来の方法であると確信しています。そして、私たちはモジュール化しているからといって、将来的にAIアプリケーションに最適化された実行環境を提供しないわけではありません。この分野のロードマップはまだ完全には決まっていませんが、それは可能です。
モジュール化の核心は選択です。決済層、実行環境、DA層を選択できます。異なるユースケースに応じて、開発者は最適なソリューションを選択できます。Web2において、TCP/IPが成功した理由は、それが本質的にモジュール化されており、開発者がその異なる側面を自由に選択できたからです。したがって、私たちは開発者により多くの選択肢を提供し、彼らが自分のアプリケーションタイプに基づいて最も適切な環境を構築できるようにしたいと考えています。
Mehdi :もし今、選択する必要がある仮想マシンがあるとしたら、あなたたちが考慮しているまたは実現しようとしているアプリケーションに関して、市場で最も適している仮想マシンはどれですか?
Michael :私は非常に実用的な見方をしています。もしより多くのWeb2開発者をWeb3に引き込むために必要なら、それは最も一般的なプログラミング言語(JavaScriptやPythonなど)を使用してアプリケーションを構築できる何らかのタイプのWASM仮想マシンであるべきです。これらの言語は必ずしもチェーン上開発の最適な選択肢ではありません。
Move VMはオブジェクトとスループットの設計において非常に優れています。高性能を追求する場合、これは注目に値する選択肢です。実戦で検証された仮想マシンを考慮するなら、それはEVMです。なぜなら、多くのSolidity開発者がいるからです。したがって、選択は具体的な使用シーンによって異なります。
優先順位付けとコミュニティ構築
Jonny :あなたたちが直面している最大の障害について聞きたいのですが、それともすべてが順調ですか?あなたたちの事業がこれほど大きいとは想像できませんが、常に順調であるわけではないでしょう。
Michael :はい、私はどんなスタートアップも順調ではないと思います。常にいくつかの課題があります。私の視点から見ると、最大の課題は、私たちがペースに追いつくことを確保することです。なぜなら、私たちは非常に優れた実行を行わなければならず、迅速に市場に出るためにいくつかのトレードオフをしなければならないからです。
例えば、私たちはカスタムのコンセンサスメカニズムを使用して立ち上げることを考えていましたが、それは立ち上げ時間を4〜5ヶ月延ばすことになります。したがって、私たちは第一段階で既存のコンセンサスメカニズムを使用し、強力な概念実証を行い、各コンセンサス層で毎秒50GBなどの最終目標の一部を達成することに決めました。その後、第二段階で横にスケール可能なコンセンサス層を導入し、無限のDAスループットを実現します。AWSサーバーのスイッチを入れるように、追加のコンセンサス層を追加することで、全体のDAスループットを向上させることができます。
もう一つの課題は、私たちが一流の人材を会社に引き付けることができるかどうかを確保することです。私たちのチームは強力で、情報学オリンピックの金メダリストやトップのコンピュータサイエンス博士が含まれていますので、市場のマーケティングチームや新しく入った開発者もそれに匹敵する必要があります。
Jonny :あなたたちが現在直面している最大の障害は優先順位付けであるようですね?短期間で全てを行うことができないことを受け入れ、いくつかのトレードオフをしなければならないということです。競争についてはどう考えていますか?CelestiaやEigenDAがあなたたちの具体的なユースケースに深刻な脅威をもたらすことはないと推測します。
Michael :Web3における競争は、コミュニティに大きく依存しています。私たちは高性能とAIビルダーの周りに強力なコミュニティを構築しており、CelestiaやEigenDAはより一般的なコミュニティを持っているかもしれません。EigenDAは経済的安全性をもたらし、EigenLayer上でAVSを構築することに関心があるかもしれませんが、CelestiaはどのLayer2が取引コストを削減したいかに関心があり、高スループットのアプリケーションはあまりありません。例えば、Celestia上で高頻度DeFiを構築することは非常に困難です。なぜなら、毎秒数メガバイトのスループットが必要であり、これがCelestiaネットワークを完全に詰まらせるからです。
この観点から見ると、私たちは本当に脅威を感じていません。私たちは非常に強力なコミュニティを構築しており、他の人が現れても、すでに開発者と市場シェアのネットワーク効果を持っており、さらなる資金を得ることが期待できます。したがって、最良の防御は私たちのネットワーク効果です。
Web3とAIの相互依存
Jonny :あなたたちは人工知能を主要な焦点として選択しましたが、なぜWeb3がそのエコシステム内で人工知能をホストする必要があるのでしょうか?逆に、人工知能はなぜWeb3を必要とするのでしょうか?これは双方向の問題であり、2つの質問の答えが必ずしも肯定的であるとは限りません。
Michael :もちろん、AIのないWeb3は可能です。しかし、私は今後5〜10年の間に、すべての企業がAI企業になると考えています。なぜなら、AIはインターネットのように巨大な変革をもたらすからです。私たちは本当にWeb3でこの機会を逃したいのでしょうか?私はそうは思いません。マッキンゼーによれば、AIは数兆ドルの経済価値を解放し、70%の仕事がAIによって自動化される可能性があります。それなら、なぜそれを利用しないのでしょうか?AIのないWeb3は存在するかもしれませんが、AIがあれば未来はもっと素晴らしいものになるでしょう。私たちは、今後5〜10年の間に、ブロックチェーン上の大多数の参加者がAIエージェントとなり、彼らがあなたのためにタスクや取引を実行することになると信じています。これは非常にエキサイティングな世界であり、ユーザーに合わせた自動化サービスが大量に存在することになります。
逆に、AIも確実にWeb3を必要としています。私たちの使命は、AIを公共財にすることです。これは根本的にはインセンティブメカニズムの問題です。あなたはどのようにしてAIモデルが不正を行わないようにし、彼らが人類に最も有利な決定を下すことを確保するのでしょうか?整合性はインセンティブ、検証、安全性のコンポーネントに分解でき、それぞれのコンポーネントはブロックチェーン環境で実現するのに非常に適しています。ブロックチェーンはトークンを通じて金融化とインセンティブを実現し、AIが経済的に不正を行わない環境を作り出すのに役立ちます。すべての取引履歴もブロックチェーン上にあります。ここで大胆な声明をしますが、根本的には、トレーニングデータからデータクレンジングコンポーネント、データの取り込みと収集コンポーネントまで、すべてがチェーン上にあるべきであり、誰がデータを提供したのか、AIモデルがどのような決定を下したのかを完全に追跡できるようにすべきです。
今後5〜10年、AIシステムが物流、行政、製造システムを管理する場合、私はモデルのバージョン、彼らの決定を知り、人間の知能を超えたモデルを監視し、人間の利益と整合することを確保したいと思います。AIを不正を行う可能性のあるブラックボックスに入れることができるのか、または人類の最大の利益のために決定を下すことができるのか、私は確信が持てません。特に、AIモデルが今後5〜10年で持つ可能性のあるスーパー能力を考慮すると。
Kamran :私たちは皆、暗号分野がさまざまな物語に満ちていることを知っていますが、あなたたちがAI分野に非常に集中していることは、長期的には障害になると思いますか?あなたが言ったように、あなたたちの技術スタックは現在見られるものをはるかに上回るでしょう。AIに関する物語や命名自体が、将来的にあなたたちの発展を妨げると思いますか?
Michael :私たちはそうは考えていません。私たちは将来的にすべての企業がAI企業になると確信しています。ほとんどの企業は、そのアプリケーションやプラットフォームの中で何らかの形でAIを使用しないことはないでしょう。この観点から見ると、GPTが新しいバージョンをリリースするたびに、例えば万億パラメータを持つ新機能が開放され、より高い性能レベルに達することができます。私はその熱が持続し続けると考えています。なぜなら、これは私たちが初めて人間の言語を使ってコンピュータに何をすべきかを伝えることができる新しいパラダイムだからです。ある場合には、普通の人を超える能力を得て、以前は実現できなかったプロセスの自動化を実現することができます。例えば、一部の企業は営業開発や顧客サポートをほぼ完全に自動化しました。GPT-5、GPT-6などのリリースに伴い、AIモデルはますます賢くなります。私たちはWeb3でこのトレンドに追いつき、自分たちのオープンソースバージョンを構築する必要があります。
AIエージェントは将来的に社会の一部を運営することになります。彼らが適切な方法でブロックチェーンによってガバナンスされることを確保することが非常に重要です。10年から20年の間に、AIは確実に主流となり、巨大な社会変革をもたらすでしょう。テスラの完全自動運転モードを見れば、未来が日々現実になっていることがわかります。ロボットも私たちの生活に入り込み、大量のサポートを提供してくれるでしょう。私たちは基本的にSF映画の中に生きているのです。







