
生まれた境界: 非中央集権的な計算ネットワークはどのようにクリプトとAIに力を与えるのか?

 最近、Aethirとioが相次いでトークンを発行し、分散型コンピューティングネットワークが注目を集めています。BlockchainとAIはどのように結びつくべきでしょうか? 分散型コンピューティングネットワークの分野にはどのような先進的なプロジェクトがあり、彼らの違いや共通点をどのように分析すればよいのでしょうか? この分野はどのような課題と機会に直面するのでしょうか? 本文ではこれらについて詳しく説明します。
最近、Aethirとioが相次いでトークンを発行し、分散型コンピューティングネットワークが注目を集めています。BlockchainとAIはどのように結びつくべきでしょうか? 分散型コンピューティングネットワークの分野にはどのような先進的なプロジェクトがあり、彼らの違いや共通点をどのように分析すればよいのでしょうか? この分野はどのような課題と機会に直面するのでしょうか? 本文ではこれらについて詳しく説明します。作者:Jane Doe, Chen Li
通讯作者:Youbi投資チーム
AIとCryptoの交点
5月23日、チップ大手のNVIDIAは2025会計年度第一四半期の財務報告を発表しました。財務報告によると、NVIDIAの第一四半期の収益は260億ドルでした。その中で、データセンターの収益は前年同期比で427%増加し、驚異的な226億ドルに達しました。NVIDIAが一手で米国株式市場の財務パフォーマンスを救うことができた背景には、AI分野を巡る世界のテクノロジー企業の計算能力需要の爆発があります。トップクラスのテクノロジー企業がAI分野での展開に対する野心を強めるにつれて、これらの企業の計算能力に対する需要も指数関数的に増加しています。 TrendForceの予測によれば、2024年には米国の主要な4つのクラウドサービスプロバイダー、Microsoft、Google、AWS、Metaの高性能AIサーバーに対する需要は、それぞれ世界の需要の20.2%、16.6%、16%、10.8%を占め、合計で60%を超えるとされています。

画像出典: https://investor.nvidia.com/financial-info/financial-reports/default.aspx
「チップ不足」は近年の年間の流行語となっています。一方で、大規模言語モデル(LLM)のトレーニングと推論には大量の計算能力が必要です。また、モデルの反復が進むにつれて、計算能力のコストと需要は指数関数的に増加しています。もう一方で、Metaのような大企業は大量のチップを調達し、世界の計算能力資源はこれらのテクノロジー大手に偏っているため、小規模企業は必要な計算能力資源を得ることがますます難しくなっています。小規模企業が直面する困難は、急増する需要によるチップ供給不足だけでなく、供給の構造的矛盾からも生じています。 現在、供給側には大量の未使用GPUが存在しています。例えば、一部のデータセンターでは大量の未使用の計算能力(使用率は12%から18%の範囲)があります。また、暗号通貨のマイニングでは利益の減少により大量の計算能力資源が未使用となっています。これらの計算能力はすべてがAIトレーニングなどの専門的なアプリケーションシーンに適しているわけではありませんが、消費者向けハードウェアは他の分野、例えばAI推論、クラウドゲームのレンダリング、クラウドフォンなどの分野で依然として大きな役割を果たすことができます。この部分の計算能力資源を統合し利用する機会は非常に大きいです。
AIからcryptoに目を向けると、暗号市場は3年間の静寂を経て、ついに新たなブルマーケットを迎えました。ビットコインの価格は次々と新高値を更新し、さまざまなメムコインが登場しています。AIとCryptoはここ数年のバズワードとして注目を集めていますが、人工知能とブロックチェーンという2つの重要な技術は、まるで平行線のように交点を見出せずにいます。 今年初め、Vitalikは"The promise and challenges of crypto + AI applications"というタイトルの論文を発表し、将来のAIとcryptoの統合シーンについて議論しました。Vitalikは、ブロックチェーンやMPCなどの暗号技術を利用してAIの非中央集権的なトレーニングと推論を行うことにより、機械学習のブラックボックスを開き、AIモデルをより信頼性のあるものにするなど、多くのアイデアを述べました。これらのビジョンを実現するには、まだ長い道のりがあります。しかし、Vitalikが言及したユースケースの1つ、つまりcryptoの経済的インセンティブを利用してAIを強化することは、重要であり、短期間で実現可能な方向性でもあります。非中央集権的な計算能力ネットワークは、現段階でのAI + cryptoに最も適したシーンの1つです。
非中央集権的計算能力ネットワーク
現在、非中央集権的計算能力ネットワークの分野で発展しているプロジェクトは少なくありません。これらのプロジェクトの基本的な論理は類似しており、次のように要約できます: トークンを利用して計算能力の保有者にネットワークへの参加を促し、計算能力サービスを提供させることで、これらの分散した計算能力資源を集約して一定規模の非中央集権的計算能力ネットワークを形成します。これにより、未使用の計算能力の利用率を向上させ、より低コストで顧客の計算能力の需要を満たし、売り手と買い手の双方にウィンウィンを実現します。
読者が短期間でこの分野の全体像を把握できるように、この記事ではミクロとマクロの2つの視点から具体的なプロジェクトと全体の分野を解体し、各プロジェクトのコア競争優位性や非中央集権的計算能力分野全体の発展状況を理解するための分析視点を提供することを目的としています。筆者は5つのプロジェクト、Aethir、io.net、Render Network、Akash Network、Gensynを紹介し、プロジェクトの状況と分野の発展をまとめて評価します。
分析フレームワークの観点から、特定の非中央集権的計算能力ネットワークに焦点を当てると、それを4つのコア構成要素に分解できます:
ハードウェアネットワーク:分散した計算能力資源を統合し、世界中に分散したノードを通じて計算能力資源の共有と負荷分散を実現する、非中央集権的計算能力ネットワークの基盤層です。
双方向市場:合理的な価格設定メカニズムと発見メカニズムを通じて計算能力提供者と需要者をマッチングし、安全な取引プラットフォームを提供して、供給と需要の取引が透明で公平かつ信頼できることを保証します。
コンセンサスメカニズム:ネットワーク内のノードが正しく機能し、作業を完了することを保証するために使用されます。コンセンサスメカニズムは主に2つのレベルを監視します:1)ノードがオンラインで動作しており、いつでもタスクを受け入れることができるアクティブな状態にあるかどうかを監視します;2)ノードの作業証明:そのノードがタスクを受け取った後、効果的かつ正確にタスクを完了し、計算能力が他の目的に使用されず、プロセスやスレッドを占有していないことを確認します。
トークンインセンティブ:トークンモデルは、より多くの参加者がサービスを提供/利用するように促し、トークンを使用してこのネットワーク効果を捕獲し、コミュニティの利益を共有します。
非中央集権的計算能力分野全体を俯瞰すると、Blockworks Researchの研究報告は非常に良い分析フレームワークを提供しており、この分野のプロジェクトのポジションを3つの異なるレイヤーに分けることができます。
ベアメタルレイヤー:非中央集権的計算スタックの基盤層を構成し、主なタスクは原始的な計算能力資源を収集し、それらをAPIで呼び出せるようにすることです。
オーケストレーションレイヤー:非中央集権的計算スタックの中間層を構成し、主なタスクは調整と抽象化であり、計算能力のスケジューリング、拡張、操作、負荷分散、フォールトトレランスなどを担当します。主な役割は、底層ハードウェア管理の複雑さを「抽象化」し、エンドユーザーにより高度なユーザーインターフェースを提供し、特定の顧客群にサービスを提供することです。
アグリゲーションレイヤー:非中央集権的計算スタックの最上層を構成し、主なタスクは統合であり、ユーザーが一か所でAIトレーニング、レンダリング、zkMLなどのさまざまな計算タスクを実行できる統一されたインターフェースを提供します。これは、複数の非中央集権的計算サービスの編成と配信層に相当します。

画像出典:Youbi Capital
以上の2つの分析フレームワークに基づいて、選択した5つのプロジェクトを横断的に比較し、4つのレベル------コアビジネス、市場ポジショニング、ハードウェア施設、財務パフォーマンスに基づいて評価します。
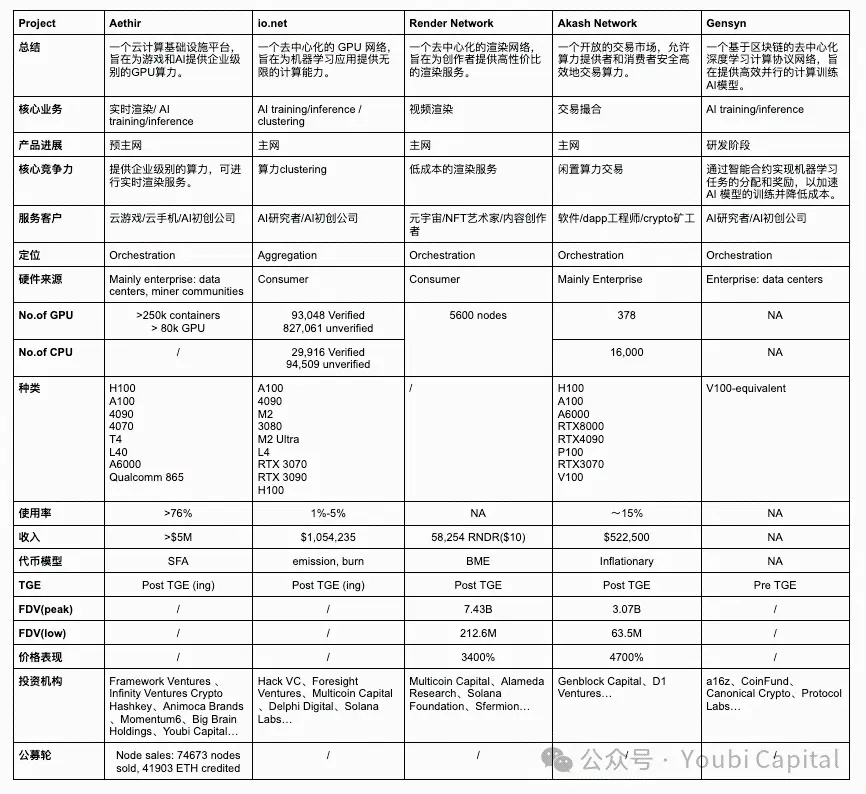
2.1 コアビジネス
底層論理から見ると、非中央集権的計算能力ネットワークは高度に同質化されています。つまり、トークンを利用して未使用の計算能力保有者に計算サービスを提供させることです。この底層論理に基づいて、プロジェクトのコアビジネスの違いを3つの側面から理解できます:
未使用計算能力の出所:
市場における未使用計算能力には主に2つの出所があります:1)データセンター、マイナーなどの企業が保有する未使用計算能力;2)個人が保有する未使用計算能力。データセンターの計算能力は通常、プロフェッショナルレベルのハードウェアですが、個人は通常、コンシューマーレベルのチップを購入します。
Aethir、Akash Network、Gensynの計算能力は主に企業から収集されています。企業から計算能力を収集する利点は、1)企業やデータセンターは通常、より高品質のハードウェアと専門のメンテナンスチームを持っており、計算能力資源の性能と信頼性が高いこと;2)企業やデータセンターの計算能力資源は同質化されており、集中管理と監視により資源のスケジューリングとメンテナンスがより効率的に行えることです。しかし、相応に、この方法はプロジェクト側に高い要求を課し、計算能力を持つ企業との商業的な関係を必要とします。また、スケーラビリティと非中央集権の程度は一定の影響を受けます。
Render Networkとio.netは主に個人から手元の未使用計算能力を提供するように促しています。個人から計算能力を収集する利点は、1)個人の未使用計算能力は顕在的コストが低く、より経済的な計算能力資源を提供できること;2)ネットワークのスケーラビリティと非中央集権の程度が高くなり、システムの弾力性と堅牢性が向上することです。しかし、欠点は、個人の資源が広範囲に分布しており、統一性がないため、管理とスケジューリングが複雑になり、運用管理の難易度が増すことです。また、個人の計算能力に依存して初期のネットワーク効果を形成するのはより困難です(キックスタートが難しい)。最後に、個人のデバイスにはより多くのセキュリティリスクが存在し、データ漏洩や計算能力の悪用のリスクをもたらす可能性があります。
計算能力の消費者
計算能力の消費者に関して、Aethir、io.net、Gensynのターゲット顧客は主に企業です。B2B顧客にとって、AIやゲームのリアルタイムレンダリングには高性能な計算需要があります。この種のワークロードは計算能力資源に対する要求が非常に高く、通常は高端GPUまたはプロフェッショナルレベルのハードウェアが必要です。さらに、B2B顧客は計算能力資源の安定性と信頼性に非常に高い要求を持っているため、高品質なサービスレベル契約を提供し、プロジェクトが正常に運営され、タイムリーな技術サポートを提供する必要があります。また、B2B顧客の移行コストは非常に高いため、非中央集権的ネットワークに成熟したSDKがなければ、顧客が迅速にデプロイすることは難しいです(例えば、Akash Networkではユーザーがリモートポートに基づいて開発する必要があります)。顧客の移行意欲は非常に低いです。
Render NetworkとAkash Networkは主に個人に計算サービスを提供しています。C2Cユーザーにサービスを提供するために、プロジェクトはシンプルで使いやすいインターフェースとツールを設計し、消費者に良好な消費体験を提供する必要があります。また、消費者は価格に敏感であるため、プロジェクトは競争力のある価格設定を提供する必要があります。
ハードウェアの種類
一般的な計算ハードウェア資源にはCPU、FPGA、GPU、ASIC、SoCなどがあります。これらのハードウェアは設計目標、性能特性、アプリケーション分野において顕著な違いがあります。要約すると、CPUは一般的な計算タスクに優れ、FPGAは高い並列処理とプログラマビリティに強みを持ち、GPUは並列計算において優れた性能を発揮し、ASICは特定のタスクにおいて最高の効率を持ち、SoCは多機能を統合したもので、高度に統合されたアプリケーションに適しています。どのハードウェアを選択するかは、具体的なアプリケーションの要求、性能要件、コストの考慮によります。私たちが議論している非中央集権的計算プロジェクトは多くがGPU計算能力を収集しており、これはプロジェクトのビジネスタイプとGPUの特性によって決まっています。GPUはAIトレーニング、並列計算、マルチメディアレンダリングなどの分野で独自の利点を持っています。
これらのプロジェクトはほとんどがGPUの統合に関与していますが、異なるアプリケーションはハードウェア仕様に対する要求が異なるため、これらのハードウェアには異質化された最適化コアとパラメータがあります。これらのパラメータには並列性/直列依存性、メモリ、遅延などが含まれます。例えば、レンダリングワークロードは実際にはコンシューマーレベルのGPUにより適しており、性能が高いデータセンターGPUには適していません。なぜなら、レンダリングは光線追跡などの高い要求があるため、コンシューマーレベルのチップ(例えば4090など)はRTコアを強化し、光線追跡タスクの計算最適化を行っています。AIトレーニングと推論にはプロフェッショナルレベルのGPUが必要です。したがって、Render Networkは個人からRTX 3090や4090などのコンシューマーレベルのGPUを集めることができ、IO.NETはAIスタートアップの要求を満たすためにH100やA100などのプロフェッショナルレベルのGPUをより多く必要とします。
2.2 市場ポジショニング
プロジェクトのポジショニングに関して、ベアメタルレイヤー、オーケストレーションレイヤー、アグリゲーションレイヤーが解決すべきコア問題、最適化の重点、価値捕獲能力は異なります。
ベアメタルレイヤーは物理資源の収集と利用に焦点を当て、オーケストレーションレイヤーは計算能力のスケジューリングと最適化に焦点を当て、物理ハードウェアを顧客群のニーズに応じて最適化設計します。アグリゲーションレイヤーは一般的な目的であり、異なる資源の統合と抽象化に焦点を当てています。価値連鎖の観点から、各プロジェクトはベアメタル層から始まり、上昇を目指すべきです。
価値捕獲の観点から見ると、ベアメタルレイヤー、オーケストレーションレイヤーからアグリゲーションレイヤーにかけて、価値捕獲能力は層ごとに増加します。アグリゲーションレイヤーは最も多くの価値を捕獲できる理由は、アグリゲーションプラットフォームが最大のネットワーク効果を得られ、最も多くのユーザーに直接触れることができるためであり、非中央集権的ネットワークのトラフィックの入り口として、計算資源管理スタック全体で最高の価値捕獲位置を占めることになります。
それに応じて、アグリゲーションプラットフォームを構築する難易度も最も高く、プロジェクトは技術的複雑性、異質資源管理、システムの信頼性とスケーラビリティ、ネットワーク効果の実現、安全性とプライバシー保護、複雑な運用管理などの多方面の問題を総合的に解決する必要があります。これらの課題はプロジェクトのコールドスタートに不利であり、分野の発展状況やタイミングに依存します。オーケストレーションレイヤーがまだ成熟していない段階で一定の市場シェアを獲得することは、アグリゲーションレイヤーを構築することは現実的ではありません。
現在、Aethir、Render Network、Akash Network、Gensynはすべてオーケストレーションレイヤーに属し、特定のターゲットと顧客群にサービスを提供することを目指しています。Aethirの現在の主なビジネスはクラウドゲームのリアルタイムレンダリングであり、B2B顧客に一定の開発およびデプロイ環境とツールを提供しています。Render Networkの主なビジネスはビデオレンダリングであり、Akash Networkの任務は淘宝のような取引プラットフォームを提供することです。一方、GensynはAIトレーニング分野に特化しています。io.netのポジショニングはアグリゲーションレイヤーですが、現在のioが実現している機能はアグリゲーションレイヤーの完全な機能からはまだ距離があり、Render NetworkやFilecoinのハードウェアを収集していますが、ハードウェア資源の抽象化と統合はまだ完了していません。
2.3 ハードウェア施設
現在、すべてのプロジェクトがネットワークの詳細データを公開しているわけではなく、相対的にio.net explorerのUIが最も優れています。そこではGPU/CPUの数量、種類、価格、分布、ネットワーク使用量、ノード収入などのパラメータを見ることができます。しかし、4月末にio.netのフロントエンドが攻撃を受け、ioがPUT/POSTのインターフェースに認証を行っていなかったため、ハッカーがフロントエンドデータを改ざんしました。これは他のプロジェクトのプライバシーやネットワークデータの信頼性にも警鐘を鳴らすものです。
GPUの数量とモデルに関して、アグリゲーションレイヤーとしてのio.netが収集したハードウェアの数量は理論的には最も多いはずです。Aethirがそれに続き、他のプロジェクトのハードウェア状況はそれほど透明ではありません。GPUモデルを見ると、ioにはA100のようなプロフェッショナルレベルのGPUもあれば、4090のようなコンシューマーレベルのGPUもあり、多様性があります。これはio.netのアグリゲーションのポジショニングに合致しています。ioは具体的なタスクの要求に応じて最も適切なGPUを選択できます。しかし、異なるモデルやブランドのGPUは異なるドライバーや設定を必要とし、ソフトウェアも複雑な最適化が必要で、管理とメンテナンスの複雑さが増します。現在、ioの各種タスクの割り当ては主にユーザーの自主選択に依存しています。
Aethirは自社のマイニングマシンを発表し、5月にはQualcommが支援したAethir Edgeが正式に発売されました。これは、ユーザーから遠く離れた単一の集中型GPUクラスターのデプロイ方法を打破し、計算能力をエッジにデプロイします。Aethir EdgeはH100のクラスター計算能力と組み合わせて、AIシーンにサービスを提供します。これは、トレーニング済みのモデルをデプロイし、最適なコストでユーザーに推論計算サービスを提供します。このソリューションはユーザーに近く、サービスが迅速で、コストパフォーマンスも高いです。
供給と需要の観点から、Akash Networkの例を挙げると、その統計データによれば、CPUの総量は約16k、GPUの数量は378個で、ネットワークのレンタル需要に応じて、CPUとGPUの利用率はそれぞれ11.1%と19.3%です。その中で、プロフェッショナルレベルのGPU H100のレンタル率が比較的高く、他のモデルはほとんど未使用の状態です。他のネットワークもAkashと同様の状況に直面しており、ネットワーク全体の需要量は高くなく、A100やH100などの人気チップを除いて、他の計算能力はほとんど未使用の状態です。
価格の優位性に関して、クラウドコンピューティング市場の巨頭を除けば、他の伝統的サービスプロバイダーと比較してコスト優位性は際立っていません。

2.4 財務パフォーマンス
トークンモデルがどのように設計されていても、健全なトークノミクスは以下の基本条件を満たす必要があります:1)ユーザーのネットワークに対する需要はトークン価格に反映される必要があり、つまりトークンは価値捕獲を実現できるものでなければなりません;2)すべての参加者、開発者、ノード、ユーザーは長期的に公平なインセンティブを得る必要があります;3)非中央集権的なガバナンスを保証し、内部者の過剰保有を避ける必要があります;4)合理的なインフレとデフレメカニズム、トークンのリリースサイクルを持ち、大幅な価格変動がネットワークの安定性と持続性に影響を与えないようにします。
トークンモデルを大まかにBME(burn and mint equilibrium)とSFA(stake for access)に分けると、これら2つのモデルのトークンのデフレ圧力の源は異なります:BMEモデルでは、ユーザーがサービスを購入した後にトークンが燃焼されるため、システムのデフレ圧力は需要によって決まります。一方、SFAはサービス提供者/ノードがトークンをステークしてサービス提供の資格を得る必要があるため、デフレ圧力は供給から生じます。BMEの利点は、非標準化商品により適していることです。しかし、ネットワークの需要が不足している場合、持続的なインフレ圧力に直面する可能性があります。各プロジェクトのトークンモデルには詳細な違いがありますが、全体的に見て、AethirはSFAに偏り、io.net、Render Network、Akash NetworkはBMEに偏っています。Gensynはまだ不明です。
収入の観点から見ると、ネットワークの需要量はネットワーク全体の収入に直接反映されます(ここではマイナーの収入については議論しません。なぜなら、マイナーはタスクを完了することで得られる報酬に加えて、プロジェクトからの補助金も受け取るからです)。公開データによると、io.netの数値が最も高いです。Aethirの収入はまだ公開されていませんが、公開情報によれば、彼らは多くのB2B顧客との契約を締結したと発表しています。
トークン価格に関しては、現在Render NetworkとAkash NetworkのみがICOを実施しています。Aethirとio.netも最近トークンを発行しましたが、価格の動向は今後観察する必要があります。Gensynの計画はまだ不明です。トークンを発行した2つのプロジェクトと、同じ分野でありながらこの記事で議論されていないトークンを発行したプロジェクトを総合的に見ると、非中央集権的計算能力ネットワークは非常に目覚ましい価格パフォーマンスを示しており、一定程度において巨大な市場潜在能力とコミュニティの高い期待を反映しています。
2.5 まとめ
非中央集権的計算能力ネットワークの分野は全体的に急速に発展しており、多くのプロジェクトが製品を通じて顧客にサービスを提供し、一定の収入を生み出しています。この分野は純粋な物語から脱却し、初歩的なサービスを提供できる発展段階に入っています。
需要の疲弊は非中央集権的計算能力ネットワークが直面する共通の問題であり、長期的な顧客需要は十分に検証されておらず、掘り起こされていません。しかし、需要側はトークン価格にあまり影響を与えておらず、すでにトークンを発行したいくつかのプロジェクトは目覚ましいパフォーマンスを示しています。
AIは非中央集権的計算能力ネットワークの主要な物語ですが、唯一のビジネスではありません。AIトレーニングや推論に利用されるだけでなく、計算能力はクラウドゲームのリアルタイムレンダリング、クラウドフォンサービスなどにも利用できます。
計算能力ネットワークのハードウェアの異質化程度は高く、計算能力ネットワークの質と規模はさらに向上する必要があります。
C2Cユーザーにとって、コスト優位性はそれほど明確ではありません。一方、B2Bユーザーにとっては、コスト削減に加えて、サービスの安定性、信頼性、技術サポート、コンプライアンスや法的サポートなどの側面も考慮する必要がありますが、Web3プロジェクトは一般的にこれらの側面で十分な成果を上げていません。
結論
AIの爆発的な成長がもたらす計算能力に対する巨大な需要は疑いの余地がありません。2012年以降、人工知能のトレーニングタスクに使用される計算能力は指数関数的に増加しており、その速度は3.5ヶ月ごとに倍増しています(対照的に、ムーアの法則は18ヶ月ごとに倍増します)。2012年以降、人々の計算能力に対する需要は30万倍以上増加しており、ムーアの法則の12倍の成長をはるかに超えています。予測によれば、GPU市場は今後5年間で32%の年平均成長率で成長し、2000億ドルを超えるとされています。AMDの見積もりはさらに高いで、同社は2027年までにGPUチップ市場が4000億ドルに達すると予測しています。
画像出典: https://www.stateof.ai/
人工知能と他の計算集約型ワークロード(AR/VRレンダリングなど)の爆発的な成長は、従来のクラウドコンピューティングと先進的な計算市場における構造的な非効率性の問題を浮き彫りにしています。理論的には、非中央集権的計算能力ネットワークは分散された未使用の計算資源を活用することで、より柔軟で低コストかつ効率的なソリューションを提供し、市場の計算資源に対する巨大な需要を満たすことができます。したがって、cryptoとAIの結合には巨大な市場潜在能力がありますが、同時に従来企業との激しい競争、高い参入障壁、複雑な市場環境にも直面しています。全体的に見ると、すべてのcrypto分野の中で、非中央集権的計算能力ネットワークは暗号分野で真の需要を得る最も有望な垂直分野の1つです。

画像出典:https://vitalik.eth.limo/general/2024/01/30/cryptoai.html
前途は明るいが、道は曲がりくねっている。上記のビジョンを達成するためには、まだ多くの問題や課題を解決する必要があります。要約すると、現段階で単純に従来のクラウドサービスを提供するだけでは、プロジェクトの利益率は非常に小さいです。需要側の分析から見ると、大企業は一般的に自社で計算能力を構築し、純粋なC2C開発者はほとんどクラウドサービスを選択します。非中央集権的計算能力ネットワーク資源を実際に使用する中小企業が安定した需要を持つかどうかは、さらに掘り起こしと検証が必要です。一方、AIは非常に高い上限と想像の余地を持つ広大な市場であり、より広い市場のために、今後非中央集権的計算サービスプロバイダーもモデル/AIサービスへの転換を図り、crypto + AIの使用シーンを探求し、プロジェクトが創出できる価値を拡大する必要があります。しかし、現時点ではAI分野にさらに発展するためには多くの問題と課題が存在します:
価格優位性が際立っていない:以前のデータ比較から、非中央集権的計算能力ネットワークのコスト優位性は明確に示されていません。考えられる理由は、需要が高いプロフェッショナルチップH100、A100などに対して、市場メカニズムがこの部分のハードウェアの価格を安くしないことです。また、非中央集権的ネットワークは未使用の計算資源を収集できるものの、非中央集権化による規模の経済効果の欠如、高いネットワークおよび帯域幅コスト、運用管理の複雑さなどの隠れたコストが計算能力コストをさらに増加させる可能性があります。
AIトレーニングの特殊性:非中央集権的な方法でAIトレーニングを行うことには、現段階で巨大な技術的ボトルネックがあります。このボトルネックはGPUの作業フローから直感的に示されます。大規模言語モデルのトレーニングでは、GPUはまず前処理されたデータバッチを受け取り、前向き伝播と逆伝播計算を行って勾配を生成します。次に、各GPUは勾配を集約し、モデルパラメータを更新して、すべてのGPUが同期することを確認します。このプロセスは、すべてのバッチがトレーニングされるか、所定のエポック数に達するまで繰り返されます。このプロセスでは、大量のデータ転送と同期が関与します。どのような並列および同期戦略を使用するか、ネットワーク帯域幅と遅延を最適化し、通信コストを削減する方法などの問題は、現在まだ良い答えが得られていません。現段階で非中央集権的計算能力ネットワークを利用してAIをトレーニングするのは現実的ではありません。
データの安全性とプライバシー:大規模言語モデルのトレーニングプロセスでは、データの配分、モデルのトレーニング、パラメータと勾配の集約など、データ処理と転送に関与する各段階がデータの安全性とプライバシーに影響を与える可能性があります。また、データプライバシーコインモデルにおいてはプライバシーがさらに重要です。データプライバシーの問題が解決できなければ、需要側で真にスケールすることはできません。
最も現実的な観点から考えると、非中央集権的計算能力ネットワークは、現在の需要発掘と未来の市場空間の両方を同時に考慮する必要があります。製品のポジショニングとターゲット顧客群を明確にし、例えば非AIまたはWeb3ネイティブプロジェクトを最初に狙い、比較的周辺の需要から始めて初期のユーザーベースを構築する必要があります。同時に、AIとcryptoの結合のさまざまなシーンを探求し、技術の最前線を探求し、サービスの転換とアップグレードを実現する必要があります。
参考文献
https://vitalik.eth.limo/general/2024/01/30/cryptoai.html







