
IOSG:GPU供給危機、AIスタートアップの打開策

 GPUクラスタはCDNのように類似の集約運命を見る可能性があります。
GPUクラスタはCDNのように類似の集約運命を見る可能性があります。著者:Mohit Pandit, IOSG Ventures
概要
GPUの不足は現実であり、供給と需要が緊張していますが、未活用のGPUの数は、今日の供給不足の需要を満たすことができます。
クラウドコンピューティングへの参加を促進するためのインセンティブ層が必要であり、最終的には推論またはトレーニングの計算タスクを調整することになります。DePINモデルはこの用途にぴったりです。
供給側のインセンティブにより、計算コストが低いため、需要側はこれを魅力的だと感じています。
すべてが素晴らしいわけではなく、Web3クラウドを選択する際にはいくつかのトレードオフを考慮する必要があります:例えば「遅延」です。従来のGPUクラウドに対して、保険、サービスレベル契約(Service Level Agreements)などのトレードオフもあります。
DePINモデルはGPUの可用性の問題を解決する可能性がありますが、断片化モデルでは状況は改善されません。需要が指数関数的に増加する場合、断片化された供給は供給がないのと同じです。
新しい市場参加者の数を考慮すると、市場の集約は避けられません。
はじめに
私たちは機械学習と人工知能の新時代の境界にいます。AIはさまざまな形でしばらく存在していましたが(AIは人間ができることを実行するように指示されるコンピュータデバイス、例えば洗濯機など)、今私たちは、知的な人間の行動を必要とするタスクを実行できる複雑な認知モデルの出現を目の当たりにしています。顕著な例には、OpenAIのGPT-4やDALL-E 2、GoogleのGeminiがあります。
急成長する人工知能(AI)分野において、私たちは発展の二重側面を認識する必要があります:モデルのトレーニングと推論。推論はAIモデルの機能と出力を含み、トレーニングはインテリジェントなモデルを構築するために必要な複雑なプロセス(機械学習アルゴリズム、データセット、計算能力を含む)を含みます。
GPT-4の例を挙げると、最終ユーザーが関心を持つのは推論だけです:テキスト入力に基づいてモデルから出力を取得します。しかし、この推論の質はモデルのトレーニングに依存します。効果的なAIモデルをトレーニングするために、開発者は包括的な基礎データセットと膨大な計算能力を得る必要があります。これらのリソースは主にOpenAI、Google、Microsoft、AWSなどの業界の巨人に集中しています。
公式はシンプルです:より良いモデルのトレーニング >> AIモデルの推論能力の向上 >> より多くのユーザーを引き付ける >> さらなるトレーニングのためのリソースが増加します。
これらの主要なプレーヤーは、大規模な基礎データセットにアクセスでき、さらに重要なのは大量の計算能力を制御しており、新興の開発者にとっては参入障壁を生み出しています。そのため、新規参入者は経済的に実行可能な規模とコストで十分なデータを取得したり、必要な計算能力を利用したりすることが難しいのです。この状況を考慮すると、ネットワークはリソースの取得を民主化する上で大きな価値を持つことがわかります。主に大規模な計算リソースの取得とコストの削減に関連しています。
GPU供給の問題
NVIDIAのCEO、Jensen Huangは2019年のCESで「ムーアの法則は終わった」と述べました。今日のGPUは極度に未活用です。深層学習/トレーニングサイクルの中でも、GPUは十分に活用されていません。
以下は、さまざまなワークロードの典型的なGPU利用率の数字です:
アイドル(Windowsオペレーティングシステムに起動したばかり):0-2%
一般的な生産タスク(執筆、簡単なブラウジング):0-15%
ビデオ再生:15 - 35%
PCゲーム:25 - 95%
グラフィックデザイン/写真編集のアクティブワークロード(Photoshop、Illustrator):15 - 55%
ビデオ編集(アクティブ):15 - 55%
ビデオ編集(レンダリング):33 - 100%
3Dレンダリング(CUDA / OptiX):33 - 100%(Winタスクマネージャーで誤って報告されることが多い - GPU-Zを使用)
GPUを搭載したほとんどの消費者デバイスは、最初の3つのカテゴリに属します。
画像GPU稼働時の利用率%。出典: Weights and Biases
上記の状況は、計算リソースの利用が不十分であることを示しています。
消費者GPUの容量をより良く活用する必要があります。たとえGPU利用率がピークに達しても、それは最適ではありません。これは、将来的に行うべき2つのことを明確にしています:
リソース(GPU)の集約
トレーニングタスクの並列化
利用可能なハードウェアの種類については、現在供給に使用される4種類があります:
· データセンターGPU(例:Nvidia A100s)
· 消費者GPU(例:Nvidia RTX3060)
· カスタムASIC(例:Coreweave IPU)
· 消費者SoCs(例:Apple M2)
ASICを除いて(特定の目的のために構築されているため)、他のハードウェアは最も効率的に利用されるように集約できます。このような多くのチップが消費者とデータセンターの手に握られているため、供給側のDePINモデルは実行可能な道かもしれません。
GPUの生産はボリュームピラミッドです。消費者向けGPUの生産量が最も多く、NVIDIA A100sやH100sのような高級GPUの生産量が最も少ない(しかし性能は高い)。これらの高級チップを生産するコストは消費者GPUの15倍ですが、時には15倍の性能を提供しないこともあります。
今日、クラウドコンピューティング市場の価値は約4830億ドルで、今後数年間で約27%の年平均成長率で成長すると予測されています。2023年には約130億時間のML計算需要があり、現在の標準料金で換算すると、2023年のML計算における約560億ドルの支出に相当します。この市場全体も急速に成長しており、3か月ごとに2倍に増加しています。
GPU需要
計算需要は主にAI開発者(研究者やエンジニア)から来ています。彼らの主なニーズは:価格(低コストの計算)、スケール(大量のGPU計算)、ユーザーエクスペリエンス(アクセスしやすさと使いやすさ)です。過去2年間、AIベースのアプリケーションの需要の増加とMLモデルの発展により、GPUの需要が急増しました。MLモデルの開発と実行には:
大量の計算(複数のGPUまたはデータセンターへのアクセスから)
モデルのトレーニング、ファインチューニング、推論を実行できる能力。各タスクは大量のGPUで並行して実行されます。
計算関連のハードウェア支出は、2021年の170億ドルから2025年には2850億ドルに増加すると予測されており(約102%の年平均成長率)、ARKは2030年までに計算関連のハードウェア支出が1.7兆ドルに達すると予測しています(43%の年平均成長率)。
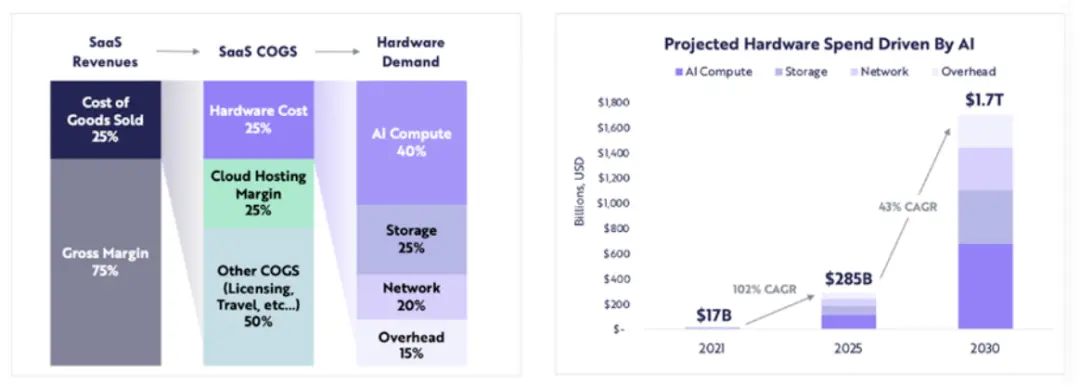
ARK Research
多くのLLMが革新の段階にあり、競争がより多くのパラメータに対する計算需要を駆動し、再トレーニングが行われる中、今後数年間にわたって高品質な計算に対する持続的な需要が期待されます。
新たなGPU供給の緊縮において、ブロックチェーンはどのように機能するのか?
リソースが不足しているとき、DePINモデルは次のように助けを提供します:
供給側を立ち上げ、大量の供給を創出する
タスクを調整し、完了させる
タスクが正しく完了することを保証する
作業を完了した提供者に正しく報酬を与える
消費者、企業、高性能など、あらゆるタイプのGPUを集約することは、利用に関して問題が発生する可能性があります。計算タスクが分割されると、A100チップは単純な計算を実行すべきではありません。GPUネットワークは、ネットワークに含めるべきGPUのタイプを決定する必要があります。これは彼らの市場参入戦略に基づいています。
計算リソース自体が分散している(時にはグローバルに)場合、ユーザーまたはプロトコル自体が選択を行い、どのタイプの計算フレームワークを使用するかを決定する必要があります。提供者であるio.netは、ユーザーが3つの計算フレームワークから選択できるようにしています:Ray、Mega-Ray、またはKubernetesクラスターをデプロイしてコンテナ内で計算タスクを実行します。Apache Sparkのような他の分散計算フレームワークもありますが、Rayが最も一般的に使用されています。一度選択されたGPUが計算タスクを完了すると、出力が再構成されてトレーニングされたモデルが得られます。
適切に設計されたトークンモデルは、GPU提供者に計算コストを補助し、多くの開発者(需要側)がそのようなソリューションをより魅力的だと感じるでしょう。分散計算システムは本質的に遅延を伴います。計算の分解と出力の再構成が存在します。そのため、開発者はモデルのトレーニングのコスト効率と必要な時間の間でトレードオフを行う必要があります。
分散計算システムは独自のチェーンを持つべきか?
ネットワークには2つの運用方法があります:
タスク(または計算サイクル)ごとに料金を請求するか、時間単位で料金を請求する
時間単位で料金を請求する
最初の方法では、Gensynが試みているような作業証明チェーンを構築することができ、異なるGPUが「作業」を分担し、その結果報酬を得ます。より信頼性のないモデルのために、彼らは検証者と告発者の概念を持ち、システムの整合性を維持することで報酬を得ます。これは解決者が生成した証明に基づいています。
別の作業証明システムはExabitsであり、これはタスクの分割ではなく、全体のGPUネットワークを単一のスーパーコンピュータとして扱います。このモデルは、大規模なLLMにより適しているようです。
Akash NetworkはGPUサポートを追加し、この分野にGPUを集約し始めました。彼らは、状態(GPU提供者が完了した作業を表示)について合意に達するための基盤となるL1、マーケット層、ユーザーアプリケーションのデプロイとスケーリングを管理するためのKubernetesやDocker Swarmのようなコンテナオーケストレーションシステムを持っています。
無信頼なシステムである場合、作業証明チェーンモデルが最も効果的です。これにより、プロトコルの調整と整合性が保証されます。
一方で、io.netのようなシステムは自らをチェーンとして構築していません。彼らはGPUの可用性の核心的な問題を解決することを選び、時間単位(毎時)で顧客に料金を請求しています。彼らは検証可能性の層を必要としません。なぜなら、彼らは本質的にGPUを「レンタル」し、特定のレンタル期間内に自由に使用するからです。プロトコル自体はタスクの分割を行わず、開発者がRay、Mega-Ray、Kubernetesのようなオープンソースフレームワークを使用して完了します。
Web2とWeb3のGPUクラウド
Web2にはGPUクラウドまたはGPU as a Serviceの分野に多くの参加者がいます。この分野の主要なプレーヤーには、AWS、CoreWeave、PaperSpace、Jarvis Labs、Lambda Labs、Google Cloud、Microsoft Azure、OVH Cloudがあります。
これは伝統的なクラウドビジネスモデルであり、顧客は計算が必要なときに時間単位(通常は1時間)でGPU(または複数のGPU)をレンタルできます。さまざまなユースケースに適した多くの異なるソリューションがあります。
Web2とWeb3のGPUクラウドの主な違いは、以下のいくつかのパラメータにあります:
- クラウド設定コスト
トークンインセンティブにより、GPUクラウドを構築するコストが大幅に削減されます。OpenAIは計算チップの生産に1兆ドルを調達しています。トークンインセンティブがない場合、市場のリーダーを打ち負かすには少なくとも1兆ドルが必要なようです。
- 計算時間
非Web3のGPUクラウドは、レンタルされたGPUクラスターが地理的に近い場所にあるため、より速くなります。一方、Web3モデルはより広範に分散したシステムを持ち、遅延は非効率なタスク分割、負荷分散、そして最も重要なのは帯域幅から生じる可能性があります。
- 計算コスト
トークンインセンティブにより、Web3の計算コストは既存のWeb2モデルよりも大幅に低くなります。
計算コストの比較:
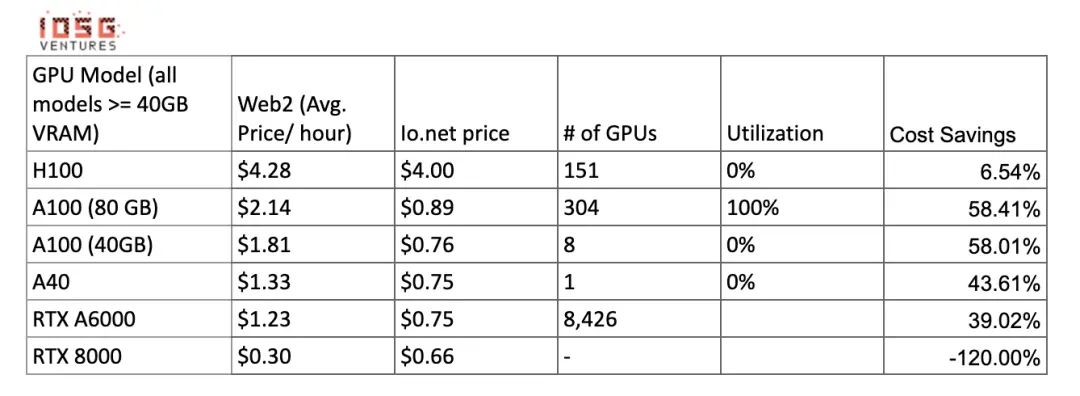
画像供給が増え、クラスターがこれらのGPUを提供する際に、これらの数字は変わる可能性があります。Gensynは、A100s(およびその同等物)を時給0.55ドルで提供すると主張しており、Exabitsも同様のコスト削減構造を約束しています。
4. コンプライアンス
無許可システムでは、コンプライアンスは容易ではありません。しかし、io.netやGensynのようなWeb3システムは、無許可システムとして自らを位置づけていません。GPUの立ち上げ、データのロード、データの共有、結果の共有の段階でGDPRやHIPAAなどのコンプライアンス問題に対処しています。
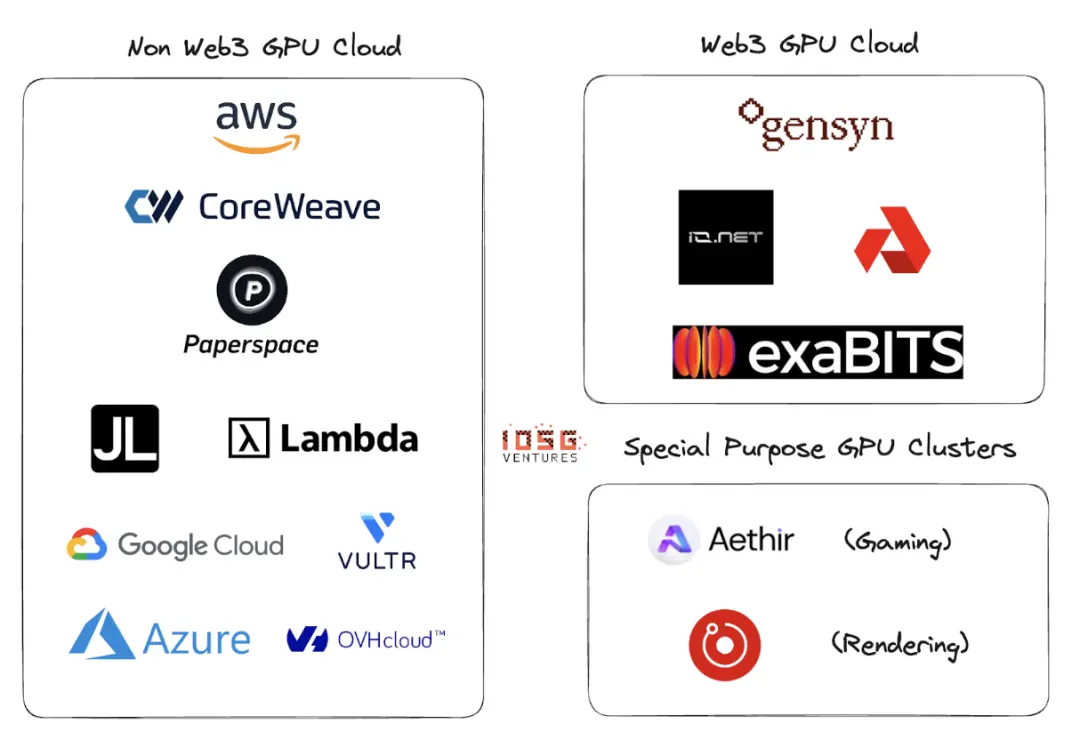
エコシステム
Gensyn、io.net、Exabits、Akash
リスク
- 需要リスク
私は、トップLLMプレーヤーがGPUを蓄積し続けるか、NVIDIAのSeleneスーパーコンピュータのようなGPUクラスターを使用するだろうと考えています。彼らは消費者やロングテールクラウドプロバイダーにGPUを集約することには依存しません。現在、トップAI組織はコストよりも質で競争しています。
非重いMLモデルに対しては、彼らはより安価な計算リソースを求め、ブロックチェーンベースのトークンインセンティブGPUクラスターは、既存のGPUを最適化しながらサービスを提供することができます(これは仮定です:これらの組織は自分のモデルをトレーニングすることを好むと仮定しています)。
- 供給リスク
ASIC研究に大量の資本が投入され、テンソル処理ユニット(TPU)のような発明が進む中、このGPU供給の問題は自動的に解決されるかもしれません。これらのASICが良好な性能とコストのトレードオフを提供できれば、大規模AI組織が蓄積した既存のGPUが市場に戻る可能性があります。
ブロックチェーンベースのGPUクラスターは、長期的な問題を解決するのでしょうか?ブロックチェーンはGPU以外の任意のチップをサポートできますが、需要側の行動がこの分野のプロジェクトの発展方向を完全に決定します。
結論
小型GPUクラスターの断片化ネットワークは問題を解決しません。「ロングテール」GPUクラスターの位置はありません。GPU提供者(小売または小規模なクラウドプレーヤー)は、ネットワークのインセンティブがより良いため、より大きなネットワークを好むでしょう。良好なトークンモデルの機能と、供給側がさまざまな計算タイプをサポートする能力が求められます。
GPUクラスターはCDNのように類似の集約運命を迎える可能性があります。大規模なプレーヤーがAWSなどの既存のリーダーと競争するためには、リソースを共有し、ネットワークの遅延とノードの地理的近接性を減らすことが始まるかもしれません。
需要側がさらに成長し(トレーニングが必要なモデルが増え、トレーニングが必要なパラメータの数も増える)、Web3プレーヤーは供給側のビジネスの発展に非常に積極的でなければなりません。もし同じ顧客群から競争するクラスターが多すぎると、供給の断片化が発生し(これが全体の概念を無効にします)、需要(TFLOPsで計測)は指数関数的に増加します。
Io.netは多くの競合から抜きん出て、集約者モデルでスタートしました。彼らはRender NetworkとFilecoinマイナーのGPUを集約し、容量を提供しながら、自らのプラットフォーム上でも供給を誘導しています。これはDePIN GPUクラスターの勝者の方向性かもしれません。






