
Sora 横空出世、2024年はAI+Web3の変革元年となるか?

 AIとWeb3の融合の未来を探る:分散型コンピューティング、大データ、Dappの革新、そしてそれが産業革新に与える深遠な影響。
AIとWeb3の融合の未来を探る:分散型コンピューティング、大データ、Dappの革新、そしてそれが産業革新に与える深遠な影響。
著者:YBB Capital Zeke
前言
2月16日、OpenAIは最新のテキスト制御動画生成拡散モデル「Sora」を発表しました。多段階にわたる広範な視覚データタイプをカバーした高品質生成動画を通じて、生成的AIの新たなマイルストーンを示しました。PikaのようなAI動画生成ツールが数枚の画像を使って数秒の動画を生成する段階にあるのとは異なり、Soraは動画と画像の圧縮潜在空間で訓練を行い、時空間位置パッチに分解することで、スケーラブルな動画生成を実現しました。さらに、このモデルは物理世界とデジタル世界を模倣する能力を示し、最終的に提示された60秒のデモは「物理世界の汎用シミュレーター」と言っても過言ではありません。
構築方法に関しては、Soraは以前のGPTモデル「ソースデータ-トランスフォーマー-拡散-出現」の技術的経路を継承しており、これはその発展が計算能力をエンジンとして必要とすることを意味します。また、動画訓練に必要なデータ量はテキスト訓練のデータ量を大きく上回るため、計算能力の需要はさらに拡大するでしょう。
私たちは以前の記事「潜在的なトラックの展望:分散型計算市場」でAI時代における計算能力の重要性を探討しました。最近のAIの熱が高まる中、市場には多くの計算能力プロジェクトが登場し、受動的に利益を得る他のDepinプロジェクト(ストレージ、計算能力など)も急騰しています。では、Depinを除いて、Web3とAIの交差点ではどのような火花が生まれるのでしょうか?このトラックにはどのような機会が潜んでいるのでしょうか?この記事の主な目的は、過去の記事の更新と補完であり、AI時代におけるWeb3の可能性について考察することです。
AI発展史の三大方向
人工知能(Artificial Intelligence)は、人間の知能を模倣、拡張、強化することを目的とした新興の科学技術です。人工知能は20世紀の50年代と60年代に誕生し、半世紀以上の発展を経て、社会生活や各業界の変革を推進する重要な技術となりました。この過程で、記号主義、接続主義、行動主義の三大研究方向の相互作用が、現在のAIの急速な発展の基盤となっています。
記号主義 (Symbolism)
論理主義またはルール主義とも呼ばれ、シンボルを処理することで人間の知能を模倣することが可能であると考えます。この方法は、シンボルを用いて問題領域内のオブジェクト、概念、およびそれらの相互関係を表現し、論理推論を利用して問題を解決します。特に専門家システムや知識表現の分野で顕著な成果を上げています。記号主義の核心的な見解は、知的行動はシンボルの操作と論理推論によって実現できるというものであり、シンボルは現実世界の高度な抽象を表します。
接続主義 (Connectionism)
神経ネットワークアプローチとも呼ばれ、人間の脳の構造と機能を模倣することで知能を実現しようとします。この方法は、多くの単純な処理ユニット(神経細胞に似たもの)で構成されるネットワークを構築し、これらのユニット間の接続強度(シナプスに似たもの)を調整することで学習を実現します。接続主義は特にデータから学習し、一般化する能力を強調し、パターン認識、分類、連続入力出力マッピング問題に特に適しています。深層学習は接続主義の発展として、画像認識、音声認識、自然言語処理などの分野で突破口を開いています。
行動主義 (Behaviorism)
行動主義は、生物模倣ロボティクスや自律的知能システムの研究と密接に関連しており、知的エージェントが環境との相互作用を通じて学習できることを強調します。前の二つとは異なり、行動主義は内部表現や思考過程の模倣に焦点を当てず、感知と行動のサイクルを通じて適応的行動を実現します。行動主義は、知能は環境との動的相互作用を通じて学習によって示されると考え、複雑で予測不可能な環境で行動する移動ロボットや適応制御システムに特に効果的です。
これら三つの研究方向には本質的な違いがありますが、実際のAI研究や応用においては、相互作用し融合しながらAI分野の発展を共に推進することができます。
AIGC原理概説
現在、爆発的に発展している生成的AI(Artificial Intelligence Generated Content、略称AIGC)は、接続主義の一種の進化と応用です。AIGCは人間の創造性を模倣して新しいコンテンツを生成することができます。これらのモデルは、大規模データセットと深層学習アルゴリズムを使用して訓練され、データに存在する基層構造、関係、パターンを学習します。ユーザーの入力プロンプトに基づいて、新しい独自の出力結果を生成します。これには画像、動画、コード、音楽、デザイン、翻訳、質問応答、テキストが含まれます。現在のAIGCは基本的に三つの要素から構成されています:深層学習(Deep Learning、略称DL)、ビッグデータ、大規模計算能力。
深層学習
深層学習は機械学習(ML)の一分野であり、深層学習アルゴリズムは人間の脳を模倣した神経ネットワークです。例えば、人間の脳は数百万の相互に関連する神経細胞を含み、これらが協力して情報を学習し処理します。同様に、深層学習神経ネットワーク(または人工神経ネットワーク)は、コンピュータ内部で協力して動作する多層の人工神経細胞で構成されています。人工神経細胞はノードと呼ばれるソフトウェアモジュールで、数学的計算を使用してデータを処理します。人工神経ネットワークは、これらのノードを使用して複雑な問題を解決する深層学習アルゴリズムです。
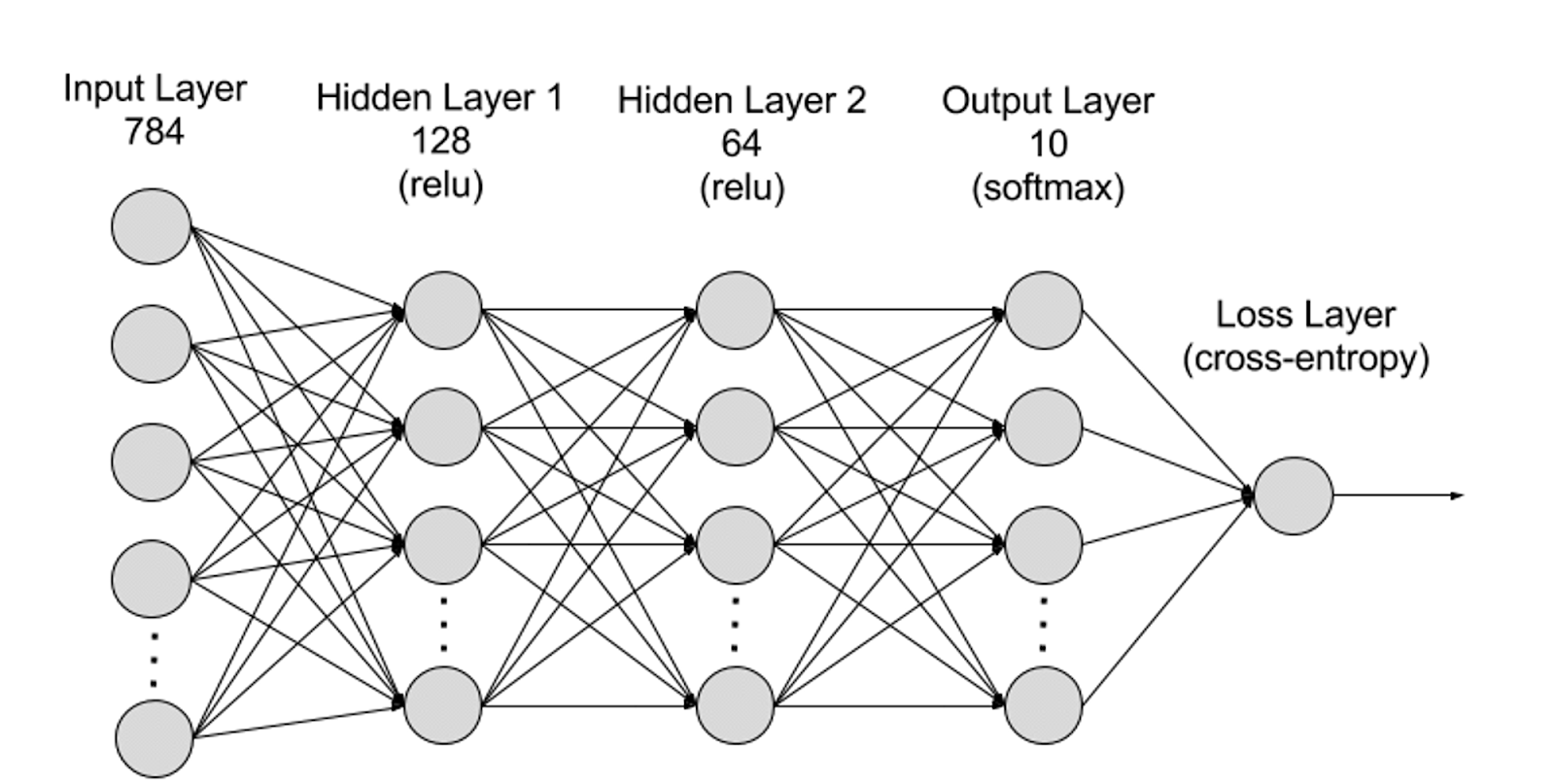
神経ネットワークは、入力層、隠れ層、出力層に階層的に分けられ、異なる層間の接続はパラメータによって表されます。
- 入力層(Input Layer):入力層は神経ネットワークの最初の層で、外部からの入力データを受け取ります。入力層の各神経細胞は入力データの一つの特徴に対応します。例えば、画像データを処理する場合、各神経細胞は画像の一つのピクセル値に対応するかもしれません;
- 隠れ層(Hidden Layer):入力層はデータを処理し、それを神経ネットワークのさらに遠い層に渡します。これらの隠れ層は異なるレベルで情報を処理し、新しい情報を受け取る際にその行動を調整します。深層学習ネットワークには数百の隠れ層があり、複数の異なる角度から問題を分析するために使用されます。例えば、分類しなければならない未知の動物の画像を得た場合、それを既に知っている動物と比較することができます。耳の形、脚の数、瞳孔の大きさを通じて、これは何の動物かを判断します。深層神経ネットワークの隠れ層も同様に機能します。深層学習アルゴリズムが動物画像を分類しようとする場合、その各隠れ層は動物の異なる特徴を処理し、正確に分類しようとします;
- 出力層(Output Layer):出力層は神経ネットワークの最後の層で、ネットワークの出力を生成します。出力層の各神経細胞は、可能な出力カテゴリまたは値を表します。例えば、分類問題では、各出力層神経細胞が一つのカテゴリに対応し、回帰問題では、出力層が一つの神経細胞のみを持ち、その値が予測結果を表すかもしれません;
- パラメータ:神経ネットワーク内で、異なる層間の接続は重み(Weights)とバイアス(Biases)パラメータによって表され、これらのパラメータは訓練中に最適化され、ネットワークがデータ内のパターンを正確に認識し、予測できるようにします。パラメータの増加は神経ネットワークのモデル容量を向上させ、すなわちモデルがデータ内の複雑なパターンを学習し表現する能力を高めます。しかし、パラメータの増加は計算能力の需要を高めることにもなります。
ビッグデータ
効果的な訓練のために、神経ネットワークは通常、大量で多様かつ高品質のデータを必要とします。これは機械学習モデルの訓練と検証の基盤です。ビッグデータを分析することで、機械学習モデルはデータ内のパターンや関係を学習し、予測や分類を行うことができます。
大規模計算能力
神経ネットワークの多層の複雑な構造、大量のパラメータ、ビッグデータ処理の需要、反復訓練方式(訓練段階では、モデルは繰り返し反復し、訓練中に各層の計算を前方伝播と後方伝播を行い、活性化関数の計算、損失関数の計算、勾配の計算、重みの更新を含みます)、高精度計算の需要、並列計算能力、最適化と正則化技術、モデル評価と検証プロセスが相まって、高い計算能力の需要を引き起こしています。

Sora
OpenAIが最新に発表した動画生成AIモデルSoraは、多様な視覚データを処理し理解する能力において大きな進歩を示しています。動画圧縮ネットワークと空間時間パッチ技術を採用することで、Soraは世界中の異なるデバイスで撮影された膨大な視覚データを統一された表現形式に変換し、複雑な視覚コンテンツの効率的な処理と理解を実現しました。テキスト条件付きのDiffusionモデルに基づき、Soraはテキストプロンプトに基づいて高度に一致する動画や画像を生成し、非常に高い創造性と適応性を示します。
しかし、Soraは動画生成と現実世界の相互作用のシミュレーションにおいて突破口を開いたものの、物理世界のシミュレーションの正確性、長い動画生成の一貫性、複雑なテキスト指示の理解、訓練と生成の効率など、いくつかの限界に直面しています。また、Soraは本質的にOpenAIの独占的な計算能力と先発優位性を通じて「ビッグデータ-トランスフォーマー-拡散-出現」という古い技術経路を継続し、暴力的美学を達成しています。他のAI企業は依然として技術的なカーブを超える可能性を持っています。
Soraとブロックチェーンの関係はあまり大きくありませんが、個人的には今後1、2年の間にSoraの影響が他の高品質AI生成ツールの出現と急成長を促し、Web3内のGameFi、ソーシャル、創作プラットフォーム、Depinなどの複数のトラックに波及すると思います。したがって、Soraについての大まかな理解は必要であり、今後のAIがWeb3とどのように効果的に結びつくかは、私たちが考えるべき重要なポイントかもしれません。
AI x Web3の四大パス
上記のように、生成的AIに必要な基盤は実際には三つだけです:アルゴリズム、データ、計算能力。一方、汎用性と生成効果の観点から見ると、AIは生産方式を覆すツールです。ブロックチェーンの最大の役割は二つあります:生産関係の再構築と分散化です。したがって、両者の衝突が生み出すパスは、私個人の見解では以下の四つです:
分散型計算能力
過去に関連する記事を書いたことがあるため、この段落の主な目的は計算能力トラックの近況を更新することです。AIについて話すとき、計算能力は常に避けられない要素です。Soraの誕生以降、AIの計算能力の需要は想像を絶するものとなっています。最近、スイスのダボスで開催された2024年世界経済フォーラムの際、OpenAIのCEOサム・アルトマンは、計算能力とエネルギーが現段階で最大の足かせであり、将来的にはその重要性が通貨と同等になると明言しました。そして、2月10日には、サム・アルトマンがTwitterで驚くべき計画を発表し、7兆ドル(中国の23年の全国GDPの40%に相当)を調達して現在の世界の半導体産業の構図を変え、チップ帝国を創設しようとしています。計算能力に関する記事を書く際、私の想像力は国家の封鎖や巨大企業の独占に限られていましたが、今や一つの会社が世界の半導体産業を支配しようとするのは本当に狂気の沙汰です。
したがって、分散型計算能力の重要性は言うまでもなく、ブロックチェーンの特性は現在の計算能力の極度な独占問題や専用GPUの高額な購入問題を解決することができます。AIの観点から見ると、計算能力の使用は推論と訓練の二つの方向に分けられます。訓練を主にするプロジェクトは現在ほとんど存在せず、分散型ネットワークは神経ネットワーク設計と組み合わせる必要があり、ハードウェアに対する超高い需要があるため、非常に高いハードルであり、実現が極めて難しい方向です。一方、推論は相対的に簡単で、分散型ネットワーク設計がそれほど複雑ではなく、ハードウェアと帯域幅の需要が低いため、現在の主流の方向といえます。
中央集権的な計算能力市場の想像空間は巨大で、「万億級」というキーワードとしばしば結びつき、AI時代において最も頻繁に取り上げられる話題でもあります。しかし、最近登場した多くのプロジェクトを見ると、ほとんどが急いで立ち上げたもので、熱に便乗しています。常に分散化の正しい旗を掲げながら、分散型ネットワークの非効率性については口を閉ざしています。また、設計上の高度な同質化があり、多くのプロジェクトが非常に似通っており(一鍵L2加挖掘設計)、最終的には混乱を招く可能性があります。このような状況で、従来のAIトラックから一杯のスープを分け合うことは本当に難しいです。
アルゴリズム、モデル協力システム
機械学習アルゴリズムは、これらのアルゴリズムがデータから規則やパターンを学び、それに基づいて予測や決定を行うことを指します。アルゴリズムは技術集約型であり、その設計と最適化には深い専門知識と技術革新が必要です。アルゴリズムはAIモデルの訓練の核心であり、データが有用な洞察や決定に変換される方法を定義します。一般的な生成的AIアルゴリズムには、生成対抗ネットワーク(GAN)、変分オートエンコーダ(VAE)、トランスフォーマー(Transformer)などがあり、各アルゴリズムは特定の領域(例えば、絵画、言語認識、翻訳、動画生成)または目的のために生まれ、アルゴリズムを通じて専用のAIモデルを訓練します。
このように多くのアルゴリズムとモデルがそれぞれの特性を持っていますが、私たちはそれらを統合して文武両道のモデルを作ることができるのでしょうか?最近注目を集めているBittensorはこの方向の先駆者であり、マイニングのインセンティブを通じて異なるAIモデルとアルゴリズムが相互に協力し学習することを促進し、より効率的で全能なAIモデルを創出します。同様にこの方向に特化したCommune AI(コード協力)などもありますが、アルゴリズムとモデルは現在のAI企業にとって自社の看門法宝であり、簡単には外部に貸し出されることはありません。
したがって、AI協力エコシステムという物語は非常に新鮮で興味深いものであり、協力エコシステムはブロックチェーンの利点を利用してAIアルゴリズムの孤島の欠点を統合しようとしていますが、対応する価値を創造できるかどうかはまだ不明です。結局のところ、主要なAI企業のクローズドソースアルゴリズムとモデルは、更新と統合の能力が非常に強力です。例えば、OpenAIは発展してから2年も経たずに、初期のテキスト生成モデルから多領域生成モデルに進化しました。Bittensorなどのプロジェクトは、モデルとアルゴリズムが対象とする領域で新たな道を切り開く必要があるかもしれません。
分散型ビッグデータ
単純な観点から見ると、プライベートデータをAIに供給し、データにラベルを付けることはブロックチェーンと非常に適合する方向であり、ゴミデータや悪用を防ぐ方法に注意すれば、データストレージにおいてFIL、ARなどのDepinプロジェクトが利益を得ることができます。複雑な観点から見ると、ブロックチェーンデータを機械学習(ML)に利用し、ブロックチェーンデータの可アクセス性を解決することも興味深い方向です(Gizaの模索方向の一つ)。
理論的には、ブロックチェーンデータはいつでもアクセス可能であり、ブロックチェーン全体の状態を反映しています。しかし、ブロックチェーンエコシステムの外部にいる人々にとって、これらの膨大なデータ量を取得することは容易ではありません。ブロックチェーンを完全に保存するには、豊富な専門知識と大量の専用ハードウェアリソースが必要です。ブロックチェーンデータへのアクセスの課題を克服するために、業界内ではいくつかの解決策が登場しています。例えば、RPCプロバイダーはAPIを通じてノードにアクセスし、インデックスサービスはSQLやGraphQLを通じてデータ抽出を可能にします。この二つの方法は問題解決において重要な役割を果たしています。しかし、これらの方法には限界があります。RPCサービスは大量のデータクエリを必要とする高密度使用シーンには適しておらず、しばしばニーズを満たすことができません。同時に、インデックスサービスはより構造化されたデータ検索方法を提供しますが、Web3プロトコルの複雑さが効率的なクエリの構築を極めて困難にし、時には数百行、あるいは数千行の複雑なコードを書く必要があります。この複雑さは、一般的なデータ業界の専門家やWeb3の詳細をあまり理解していない人々にとって大きな障害となります。これらの制限の累積効果は、ブロックチェーンデータをより簡単に取得し利用できる方法の必要性を浮き彫りにし、この分野でのより広範な応用と革新を促進することができます。
したがって、ZKML(ゼロ知識証明機械学習、機械学習のブロックチェーンへの負担を軽減)と高品質のブロックチェーンデータを組み合わせることで、ブロックチェーンの可アクセス性を解決するデータセットを創出できるかもしれません。AIはブロックチェーンデータの可アクセス性のハードルを大幅に下げることができるため、時間が経つにつれて、開発者、研究者、ML分野の愛好者は、効果的で革新的な解決策を構築するために、より多くの高品質で関連性のあるデータセットにアクセスできるようになるでしょう。
AIによるDappの強化
2023年、ChatGPT3が爆発的に人気を博して以来、AIによるDappの強化は非常に一般的な方向となっています。汎用性の高い生成的AIは、APIを通じて接続することで、データプラットフォーム、取引ボット、ブロックチェーン百科などのアプリケーションを簡素化し、インテリジェントに分析することができます。一方で、チャットボット(例えばMyshell)やAIパートナー(Sleepless AI)としての役割を果たしたり、生成的AIを通じてチェーンゲーム内のNPCを創造したりすることもできます。しかし、技術的な壁が非常に低いため、大部分はAPIを接続した後に微調整を行うだけで、プロジェクト自体との結びつきも不十分であるため、あまり注目されることはありません。
しかし、Soraの登場以降、私はAIによるGameFi(メタバースを含む)や創作プラットフォームの強化が今後の注目すべき重点になると考えています。Web3分野の下から上への特性から、伝統的なゲームやクリエイティブ企業と競争できる製品が生まれるのは難しいでしょうが、Soraの登場はこの窮地を打破する可能性があります(おそらく2、3年以内に)。Soraのデモを見る限り、すでに短編劇会社と競争する潜在能力を持っており、Web3の活発なコミュニティ文化は多くの興味深いアイデアを生み出すことができるでしょう。制約条件が想像力だけであるとき、下から上の業界と上から下の伝統的業界の間の壁は打破されるでしょう。
結語
生成的AIツールの進歩に伴い、私たちは今後さらに多くの画期的な「iPhoneの瞬間」を経験するでしょう。多くの人々がAIとWeb3の結びつきに懐疑的である一方で、実際には現在の方向性には大きな問題はなく、解決すべき痛点は実際には三つだけです:必要性、効率、適合度。両者の融合は探索段階にありますが、このトラックが次のブルマーケットの主流になることを妨げるものではありません。
新しい事物に対して常に十分な好奇心と受容性を持つことは、私たちが必要とする心構えです。歴史的に見ても、自動車が馬車に取って代わる変化は瞬時に決定的なものとなりました。過去のNFTと同様に、あまりにも多くの偏見を持つことは、機会を逃すことにつながります。






