
AIに特化した分散型Web3の基盤プロトコルKIP Protocol #1を理解する

 KIPプロトコルは、AIに特化した分散型Web3の基盤プロトコルです。一連のKIP解説記事を通じて、皆さんがKIPプロトコルが何であるかを体系的に理解できることを願っています。
KIPプロトコルは、AIに特化した分散型Web3の基盤プロトコルです。一連のKIP解説記事を通じて、皆さんがKIPプロトコルが何であるかを体系的に理解できることを願っています。著者:KIPプロトコル
まず、KIPは単なるAIアプリではなく、大規模言語モデルでもなく、データベース/知識ベースでもありません。
KIPプロトコルは、AIアプリ開発者、モデル制作者、データ所有者のために構築された分散型の基盤プロトコルであり、Web3において安全に取引とマネタイズを行うことができます。KIPは、価値のある知識とデータを知識資産として保護し、マネタイズできるようにし、AIとのインタラクションを行いながら所有権を失わないことを保証します。
AIアプリ開発者、モデル制作者、データ所有者にとって、Web3における分散型の作業と収益化において、KIPが重要であることがわかるでしょう。
(私たちはこの3つのカテゴリを「AI価値創造者」と呼びます)
AIの分散化は非常に大きく重要なテーマであり、現在、複数の先駆的なプロジェクトが異なるアプローチでこの問題に取り組んでいます。
KIPは、AI価値創造者がWeb3でその作業を展開し、収益化しようとする際に直面する基本的な問題を解決することに焦点を当てています。
AIモデルはアプリとデータを必要とし、経済的価値を創造する

AI分野では、20以上の異なるカテゴリの企業がそのソリューションを提供していますが、過去1年間、生成AIの大部分の注目はAIモデルに集中しています(ここにはトランスフォーマーから生成対抗ネットワーク、拡散モデルまで、多くの異なるカテゴリと方法があります)。
実際、これらのモデルはこの新しい時代の計算の真の突破口を代表しており、背後には本当の知恵があります。
しかし、AIにおいて商業化エコシステムを構築するためには、モデルは少なくとも他の2つの重要な価値創造者に依存する必要があります。
1)AIアプリ:'AIの顔'
モデルの熱狂の中で、アプリの重要性を見落としがちです。
AIアプリは、ユーザーをAIの世界に導くために不可欠です。これらのアプリは、チャットボット、画像生成器、検索ボット、分析ボット、あるいは単純なプロンプトなど、さまざまな形を取ることができます。
彼らはユーザー体験を蓄積し、ユーザーを獲得し、最も重要なのはユーザーから料金を徴収することができます。
多くの人々は、ChatGPTがOpenAIのアプリであり、OpenAIのさまざまなモデル(GPT 3.5、GPT 4)によって駆動されていることを忘れています。OpenAIのチャットボットの画期的な人間化応答は、モデル側ではなくアプリプログラム側でコーディングされています。(アプリインターフェースを介してモデルに直接接続し、回答を比較することでこれがわかります。)
要するに:アプリがなければ、モデルは単なるコードの塊であり、金属の箱に入れられていて、まったく利用できません。
2) データ:'AIの根本'
データは以下の点で重要です:
- a) モデルのトレーニングと微調整、
- b) 検索強化生成(RAG)
すべてのモデルはデータを使用してトレーニングと微調整を行います。微調整がなければ、モデルはより強力または賢くなることはできません。
しかし、データを使用してモデルを微調整またはトレーニングすると、データは本質的にモデルに「同化」または「吸収」され、具体的にはモデルの重みの調整として現れます。
したがって、データを直接使用してモデルをトレーニングすることが不可能、不切実、または違法な場合、"検索強化生成"(RAG)と呼ばれる革新的な技術が機能します。
RAGは、外部データベースから情報を取得する機能と、AIモデルを介して応答を生成する能力を組み合わせます。これは、超知能アシスタントを持っているようなもので、あなたの質問を理解し、自分で答えを知らなくても、どこで答えを見つけるかを知っています。
RAGはまだ比較的新しい技術ですが、データの敏感性と保護の概念が強化されるにつれて、RAG技術は実際のアプリケーションを通じて巨大な商業的価値をもたらし、将来のほとんどの人がAIにアクセスするための主流のフレームワークになると確信しています。
どのような方法を採用しても、データがなければ持続的なAIの革新は実現できません。
活気に満ちたAIエコシステムは、異なる業界からの価値創造者を統合する必要があります。
モデルのトレーニングと微調整に優れた個人や企業は、顧客向けのアプリの設計やマーケティングが得意でないかもしれません。
同様に、貴重なデータセットや知識ベースを持つ研究者や分野の専門家も、AIモデルをトレーニングしたりアプリを設計したりするスキルを持っていないかもしれません。
しかし、活気に満ちた多様なエコシステムの中では、彼らは孤立する必要はありません。異なる業界の企業や個人が協力して、ユーザーのために使用ケースと経済的価値を創造できます。
アプリデザイナーは、製品計画に最も適したAIモデルを選択し、ユーザーに最も役立つ外部知識ベースを事前に選択できます。
しかし、もしこの3つの異なる業界の人材が徐々に閉じたエコシステムに吸収されてしまったら、どうなるのでしょうか?
それが現在起こっていることです。この問題については今後の記事で詳しく議論しますが、今は「openai 著作権保護」とインターネットで検索し、AIの未来におけるデータ所有権の影響について考えてみてください。
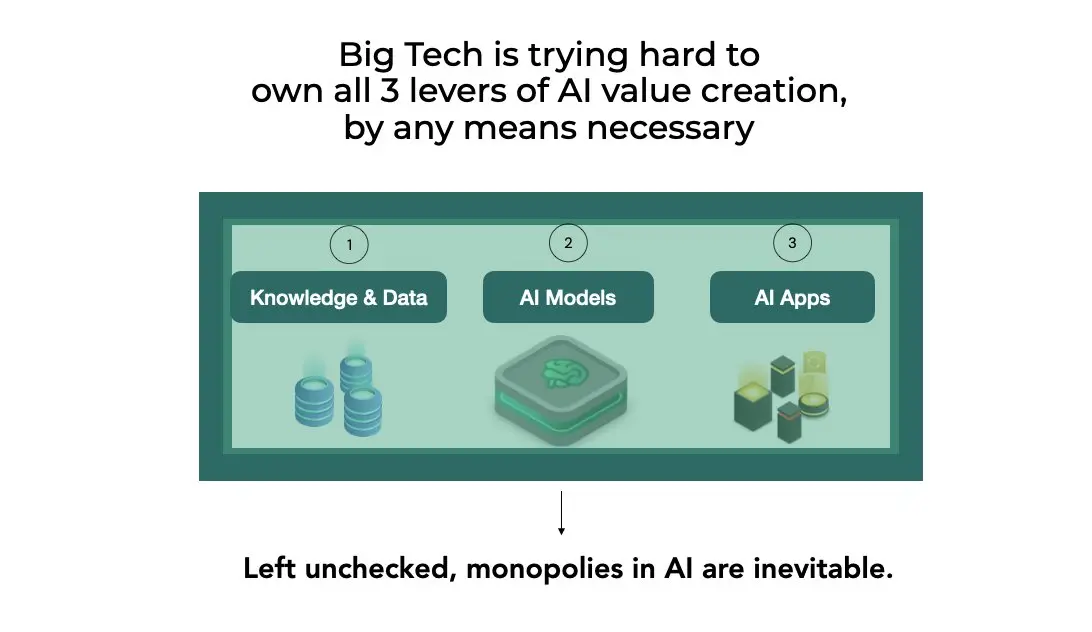
なぜKIPはAIの分散化を促進したいのか?
AI分野の独占は独特の危険性を持ち、AIの分散化は私たちの集団的利益が狭い企業利益に屈することへの緊急かつ必要な対応です。
私たちはAI加速主義(e/acc)を100%支持し、大手テクノロジー企業がAI革新を推進する上での重要な貢献を否定することはありません。
しかし、大部分の企業の行動は、株主の利益最大化を目的とした無分別なものです。これは資本主義の本質であり、彼らの本質を変えることを期待し、その動機を無視することは現実を否定することです。
私たちはAI分野において対抗的なバランス状態を確立し、多くの異なる参加者が市場に参加し競争できるようにし、革新が繁栄できる環境を作る必要があります。AIの未来は、いかなる巨大企業の企業利益にも屈するべきではありません。
私たちは、AIの分散化がこの理想的な状態を実現する唯一の方法であると考えています。
KIPはどのようにAIの分散化を促進するのか?

KIPは、AIモデル制作者、アプリ開発者、データ所有者が分散化を試みる際に直面する3つの基本的な問題を解決します。
1) オンチェーン/オフチェーン接続
2) マネタイズと収益化
3) 所有権とセキュリティの問題
1)「オンチェーン/オフチェーン接続」問題
オープンソースモデルライブラリのHugging Faceには40万以上のモデルがあり、これはAI業界がどれほど活気に満ちているかを示していますが、まだ始まったばかりです。
現在のブロックチェーン技術は、ほとんどの一般ユーザーが受け入れられるコストや速度でモデルのコア推論機能(完全に分散化されたモデル)を提供できません(エッジコンピューティングの進歩がこの目標を早く達成する可能性があります)。
したがって、すべてのモデルがオフチェーンモデルであるわけではありませんが、オフチェーンモデルでのさらなる革新と補完が期待できます。
Web3でこれらすべてのアイデアと革新を解放するために、KIPは簡単にオンチェーンで推論を行うことができます。
KIPは、ブロックチェーンの外で機械学習推論に関連する重い計算タスクを処理しながら、分散型システムの完全性と原則を維持します。
2)「収益」問題

採用者がより多くの経済的利益を享受できない場合、世界中のどんなに優れた技術も採用されません。
AIの基本的な収入モデルフレームワークは「クエリごとの支払い」として説明できます。ユーザーの各クエリはGPUの計算能力を消費するため、誰かが支払う必要があります。ユーザーのクエリに答えるためには、複数のAI価値創造者がその問題に答える必要があります。
私たちは、分散化のために分散化を提唱しているのではなく、独占の代替手段として分散化を位置づけています。
したがって、AIの分散化を成功させるためには、AIの作業を分散化するすべての関係者が収入を得られることを確保しなければなりません。
言うは易く行うは難しですが、AI分野ではそれほど簡単ではありません。
RAGを通じてクエリを実行する例を挙げてみましょう
- ユーザーがAIチャットボットに質問します。
- AIチャットボットはそのクエリを自分の脳--AIモデルに転送します。
- モデルは知識ベースから質問に必要な関連データブロックを取得し、回答を作成してアプリに送信します。
- アプリは回答をパッケージ化してユーザーに送信します。
この簡略化された例では、すべての3つの役割がどのようにユーザーのクエリに答えるために貢献しているかがわかります。
もし中央集権的なエコシステムの中で、1つのプラットフォームが3つの役割を所有し制御している場合(上の図の2番目の図のようにOpenAIが行おうとしていること)、あなたはその中央集権的なプラットフォームに料金を支払うだけで、残りは内部での転送です。
しかし、私たちが独占ではなく分散化を望むなら、各当事者が支払われる必要があり、次の問題を解決する必要があります:
- 各当事者の貢献を記録(オンチェーン)する
- ユーザーからの収入を分配する
- 誰もが自分の収入を得られるようにする
これがKIPが解決しようとしている分散型AIの「収益」問題です。
私たちは、低コストで高効率のWeb3インフラを通じてこれを実現します。このインフラは、AI価値創造者間の接続、ユーザーからの料金徴収の方法、収益の引き出しの方法を提供します。(この点については、今後のKIPシリーズで紹介します)。
収益問題を最初に解決しなければ、AIの分散化はより困難になり、少数の真の理想主義者を除いて広く採用されることは不可能です。
3)「所有権」問題
真の所有権と結びつかない限り、マネタイズは単なる弱い特権です。
私たちは、中央集権的なプラットフォーム上のアカウントがいつでも閉鎖され、禁止される様子を見てきました。
KIPは、ブロックチェーントークン、特にERC-3525トークン(SFT)を使用して、AI価値創造者の成果を「代表」することでこの問題を解決します。
1. データ所有者にとって: SFTはベクトル化された知識ベース、またはモデルのトレーニングに使用される暗号化された生データファイルのリンクを表します。
2. モデル制作者にとって: SFTはオフチェーンモデルへのAPI、または販売可能な重みモデルのセットを表すことができます。
3. アプリ開発者にとって: SFTはフロントエンドAPIまたはプロンプトそのものを表すことができます。
これらのSFTは「マネタイズエンティティ」として、オンチェーンで相互にインタラクションし、各SFTが特定の取引から得た金額を記録します。
これらの問題を解決することで、KIPはAI価値創造者が自分の作業を簡単に分散化できるようにし、活気に満ちた、より大規模な分散型AIエコシステムの初期条件を創造します。
KIPはAI革新に必要な分散型Web3基盤プロトコルです。
KIPプロトコルについて
KIPプロトコルは、AIアプリ開発者、モデル制作者、データ所有者のためにWeb3基盤プロトコルを構築し、AI資産が簡単に展開され、マネタイズされることを可能にし、完全なデジタル所有権を保持します。
KIPは、分散型AI展開における問題と課題を解決するための新しいAIビジネスエコシステムを構築し、すべての人がAIによってもたらされる経済的利益を享受できるようにします。
KIPチームは、2019年以降AI研究に従事している経験豊富な博士や技術専門家を集めており、同時にWeb3分野で深い専門知識と豊富な経験を持ち、AIの分散化を推進し、分散型AIの波の加速剤となることを目指しています。
詳細については、私たちの公式アカウントをフォローしてください:







