
孤島から協調へ:Web3ネイティブデータパイプラインの意義

 Web3市場でデータパイプラインを構築することは、分散型の特徴を持つだけでなく、これらの機会を実際に捉えるための出発点として重要な役割を果たすことができます。
Web3市場でデータパイプラインを構築することは、分散型の特徴を持つだけでなく、これらの機会を実際に捉えるための出発点として重要な役割を果たすことができます。執筆:Jay : : FP
編纂:深潮 TechFlow
2008年のビットコインホワイトペーパーの発表は、信頼の概念についての再考を引き起こしました。その後、ブロックチェーンはその定義を拡張し、信頼を必要としないシステムの概念を含むようになり、個人の主権、金融の民主化、所有権など、さまざまな価値が既存のシステムに適用できると急速に発展しました。もちろん、ブロックチェーンが実際に適用される前には、多くの検証と議論が必要になるかもしれません。なぜなら、さまざまな既存のシステムと比較して、ブロックチェーンの特徴はやや過激に見えるかもしれないからです。しかし、これらのシナリオに対して楽観的な見方を持つなら、データパイプラインを構築し、ブロックチェーンに保存されている価値ある情報を分析することは、業界の発展におけるもう一つの重要な転換点となる可能性があります。なぜなら、私たちは以前には存在しなかったWeb3ネイティブのビジネスインテリジェンスを観察できるからです。
この記事では、既存のIT市場で一般的に使用されているデータパイプラインをWeb3環境に投影することで、Web3ネイティブデータパイプラインの可能性を探ります。記事では、これらのパイプラインの利点、解決すべき課題、そしてこれらのパイプラインが業界に与える影響について議論します。
1.奇点は情報革新から生まれる
"言語は人間と低等動物との最も重要な違いの一つです。これは単に発音の能力だけでなく、明確な音を明確な思想と結びつけ、これらの音を思想交流の記号として使用することです。"--- ダーウィン
歴史的に、人類文明の重大な進歩は情報共有の革新と共にありました。私たちの祖先は言語、口頭および書面の言語を使用して互いにコミュニケーションを取り、知識を次世代に伝えました。これにより、彼らは他の種に対して重大な優位性を持つことができました。書き言葉、紙、印刷技術の発明は、情報をより広く共有することを可能にし、科学、技術、文化の重大な進歩をもたらしました。特に、グーテンベルクの聖書の金属活字印刷技術は画期的な瞬間であり、大量生産の書籍や他の印刷物を可能にしました。これは宗教改革、民主革命、科学の進歩の出発点に深遠な影響を与えました。
2000年代のIT技術の急速な発展は、私たちが人間の行動をより深く理解することを可能にしました。これにより、生活様式が変化し、現代のほとんどの人々はデジタル情報に基づいてさまざまな決定を下すようになりました。このため、私たちは現代社会を「IT革新の時代」と呼んでいます。
インターネットが全面的に商業化されてからわずか20年後、人工知能技術は再び世界を驚かせました。人力を代替する多くのアプリケーションが登場し、多くの人々がAIが文明を変えるだろうと議論しています。中には、こうした技術がどのようにしてこれほど急速に現れ、私たちの社会の基盤を揺るがすことができるのかを疑問視する人もいます。「ムーアの法則」が半導体の性能が時間とともに指数関数的に増加することを示しているにもかかわらず、GPTの登場がもたらした変化はあまりにも突然で、すぐには受け入れられませんでした。
しかし、興味深いことに、GPTモデル自体は実際には非常に画期的なアーキテクチャではありません。一方で、AI業界は以下の要素をGPTモデルの主要な成功要因として挙げています:1)大規模な顧客群に対してビジネス領域を定義し、2)データパイプラインを通じてモデルを調整すること------データ収集から最終結果、結果に基づくフィードバックまで。簡単に言えば、サービス提供の目的を明確にし、データ/情報処理プロセスをアップグレードすることで、これらのアプリケーションは革新を実現しています。
2.データ駆動の意思決定は至る所に
私たちが言うほとんどの革新は、実際には蓄積されたデータの処理に基づいており、機会や直感に基づいているわけではありません。よく言われるように、「資本主義市場では、強者が生き残るのではなく、生き残った者が強いのです」。今日の企業は競争が激しく、市場は飽和しています。したがって、企業はさまざまなデータを収集し分析して、最小のニッチでさえも捉えようとしています。
私たちはシュンペーター(深潮注:熊彼特、著名な経済学者)の「創造的破壊」理論に過度に没頭し、直感に基づく意思決定を過大評価しているかもしれません。しかし、優れた直感でさえ、最終的には個人が蓄積したデータと情報の産物です。デジタル世界は今後、私たちの生活により深く浸透し、ますます多くのセンシティブな情報がデジタルデータの形で提示されるでしょう。
Web3市場は、ユーザーに自分のデータを制御する権限を与える可能性から広く注目されています。しかし、Web3の基盤技術であるブロックチェーン分野では、現在、セキュリティ、分散化、スケーラビリティの三難問題(深潮注:トリレンマ)を解決することにより多くの関心が寄せられています。新技術が現実世界で説得力を持つためには、さまざまな方法で使用できるアプリケーションとインテリジェンスを開発することが重要です。この状況はビッグデータ分野で既に見られ、2010年頃からビッグデータ処理とデータパイプラインの方法論は大きな進展を遂げています。Web3の文脈では、業界の発展を推進し、データに基づくインテリジェンスを生み出すためにデータフローシステムを構築する努力が必要です。
3.チェーン上のデータフローに基づく機会
では、Web3ネイティブデータフローシステムからどのような機会を捉え、これらの機会をつかむためにどのような課題を解決する必要があるのでしょうか?
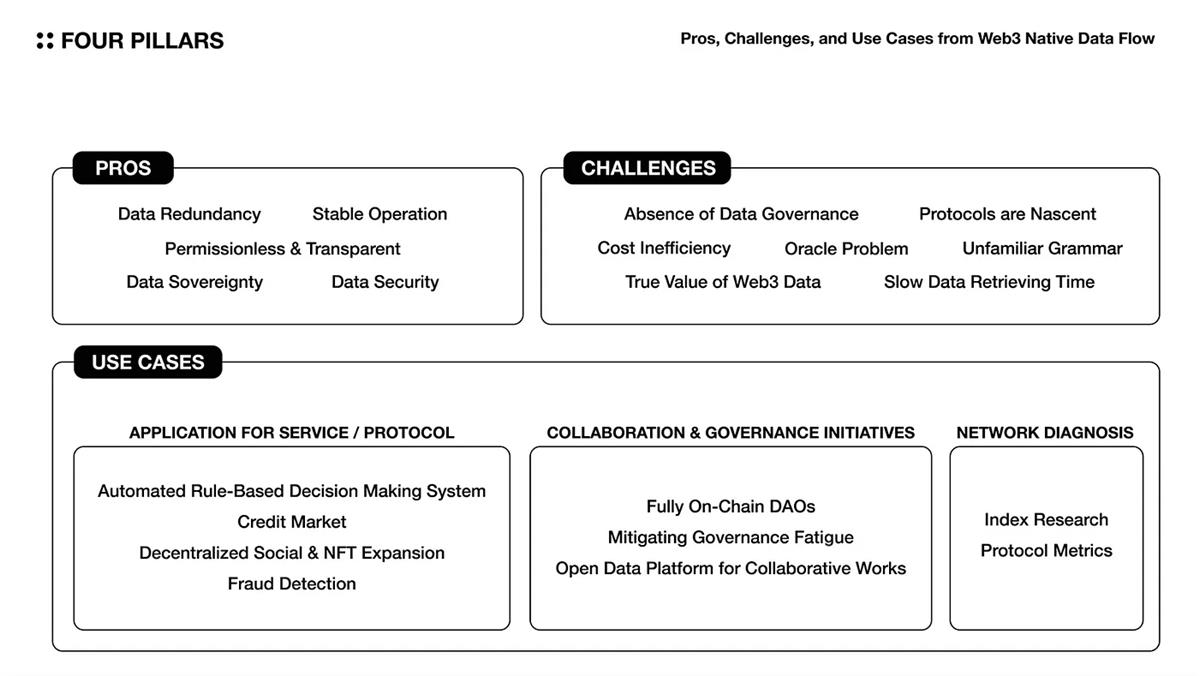
3.1 利点
簡単に言えば、Web3ネイティブデータフローを構成する価値は、信頼できるデータを安全かつ効果的に複数のエンティティに配信できることであり、そこから価値ある洞察を引き出すことができます。
- データの冗長性------チェーン上のデータは失われる可能性が低く、プロトコルネットワークがデータの断片を複数のノードに保存するため、より弾力性があります。
- データの安全性------チェーン上のデータは改ざん防止性を持ち、分散ノードからなるネットワークによって検証と合意が行われます。
- データの主権------データの主権は、ユーザーが自分のデータを所有し、制御する権利です。チェーン上のデータフローを通じて、ユーザーは自分のデータがどのように使用されているかを確認し、正当なアクセスが必要な人とだけ共有することを選択できます。
- 許可不要で透明性------チェーン上のデータは透明であり、改ざん防止性があります。これにより、処理されているデータが信頼できる情報源であることが保証されます。
- 安定した運用------データフローが分散環境でプロトコルによって編成されると、単一障害点がないため、各レベルがダウンタイムにさらされる確率が大幅に低下します。
3.2 アプリケーションケース
信頼は異なるエンティティが相互に交流し、意思決定を行う基盤です。したがって、信頼できるデータが安全に配信されると、多くの相互作用や意思決定がさまざまなエンティティが参加するWeb3サービスを通じて行われることを意味します。これは社会資本を最大化するのに役立ち、以下のようなアプリケーションケースを想像できます。
3.2.1 サービス/プロトコルアプリケーション
ルールに基づく自動化された意思決定システム------プロトコルは、サービスを運営するために重要なパラメータを使用します。これらのパラメータは、サービスの状態を安定させ、ユーザーに最適な体験を提供するために定期的に調整されます。しかし、プロトコルは常にサービスの状態を監視し、パラメータをタイムリーに動的に変更することはできません。これがチェーン上のデータフローの役割です。チェーン上のデータフローは、サービスの状態をリアルタイムで分析し、サービス要求に一致する最適なパラメータセットを提案するために使用できます(例:貸出プロトコルアプリケーションの自動浮動金利メカニズム)。
- 信用市場の成長------従来、信用は金融市場で個人の返済能力を測るために使用されてきました。これは市場の効率を向上させるのに役立ちました。しかし、Web3市場では信用の定義がまだ明確ではありません。これは、個人データが不足しており、業界間でデータガバナンスが欠如しているためです。したがって、情報の統合と収集が困難になります。チェーン上の断片化データを収集し処理するプロセスを構築することで、Web3市場における信用市場を再定義することができます(例:SpectralのMACRO(多資産信用リスク予言機)スコア)。
- 分散型ソーシャル/NFT拡張------分散型社会は、ユーザーの制御、プライバシー保護、検閲耐性、コミュニティガバナンスを優先します。これは代替的な社会のパラダイムを提供します。したがって、さまざまなメタデータをよりスムーズに制御および更新し、プラットフォーム間の移行を促進するためのパイプラインを構築できます。
- 詐欺検出------スマートコントラクトを使用したWeb3サービスは、資金を盗む、システムに侵入する、デカップリングや流動性攻撃を引き起こす悪意のある攻撃に対して脆弱です。これらの攻撃を事前に検出できるシステムを作成することで、Web3サービスは迅速な対応計画を策定し、ユーザーを保護できます。
3.2.2 協力とガバナンスの取り組み
- 完全にチェーン上のDAO------分散型自治組織(DAO)は、効果的なガバナンスと公共資金の実行において、オフチェーンツールに大きく依存しています。チェーン上のデータ処理プロセスを構築することで、DAO運営の透明なプロセスを作成し、Web3ネイティブDAOの価値をさらに高めることができます。
- ガバナンス疲れの緩和------Web3プロトコルの意思決定は通常、コミュニティガバナンスを通じて行われます。しかし、地理的障壁、監視の圧力、ガバナンスに必要な専門知識の欠如、ランダムに発表されるガバナンス議題、使いにくいユーザー体験など、参加者がガバナンスに参加するのを難しくする要因が多くあります。参加者が個々のガバナンス議題を理解から実際の実施までの処理プロセスを簡素化するツールを作成できれば、プロトコルガバナンスフレームワークはより効率的かつ効果的に機能することができます。
- 協力作品のオープンデータプラットフォーム------既存の学術界や産業界では、多くのデータや研究資料が公開されておらず、市場全体の発展を非常に非効率的にする可能性があります。一方で、チェーン上のデータプールは、既存の市場よりも多くの協力的な取り組みを促進できます。なぜなら、それらは誰にでも透明でアクセス可能だからです。多くのトークン標準やDeFiソリューションの発展はその良い例です。さらに、さまざまな目的のために公共データプールを運営することもできます。
3.2.3 ネットワーク診断
- 指数研究------Web3ユーザーは、プロトコルの状態を分析し比較するためにさまざまな指標を作成します。複数の客観的指標(例:Nakaflowの中本聡係数)を研究し、リアルタイムで表示できます。
- プロトコル指標------アクティブアドレスの数、取引の数、資産の流入/流出、ネットワークが生成する手数料などのデータを処理することで、プロトコルのパフォーマンスを分析できます。これらの情報は、特定のプロトコル更新の影響、MEVの状態、ネットワークの健康状態を評価するために使用できます。
3.3 課題
チェーン上のデータは、業界の価値を増加させる独自の利点を持っています。しかし、これらの利点を十分に実現するためには、業界内外の多くの課題を解決する必要があります。
- データガバナンスの欠如------データガバナンスは、一貫性と共有のデータポリシーと標準を確立し、各データ要素の統合を促進するプロセスです。現在、各チェーン上のプロトコルは独自の標準を確立し、自分のデータタイプを取得しています。しかし、問題は、これらのプロトコルデータを集約し、ユーザーにAPIサービスを提供するエンティティ間でデータガバナンスが欠如していることです。これにより、サービス間の統合が難しくなり、結果としてユーザーが信頼できる包括的な洞察を得ることが困難になります。
- コスト効率の低下------冷データをプロトコルに保存することで、ユーザーはデータの安全性とサーバーコストを節約できます。しかし、分析のためにデータに頻繁にアクセスする必要がある場合や、大量の計算リソースが必要な場合、ブロックチェーンに保存することは経済的ではないかもしれません。
- オラクル問題------スマートコントラクトは、現実世界からのデータにアクセスできる場合にのみ十分に機能します。しかし、これらのデータは常に信頼できるわけではなく、一貫性もありません。合意アルゴリズムによって整合性が維持されるブロックチェーンとは異なり、外部データは決定的ではありません。オラクルソリューションは、特定のアプリケーション層に依存せず、外部データの整合性、品質、スケーラビリティを確保するために常に進化する必要があります。
- プロトコルはまだ初期段階------プロトコルは独自のトークンを使用してユーザーにサービスを維持し、サービス料金を支払うように促します。しかし、プロトコルを運営するために必要なパラメータ(例:サービスユーザーの正確な定義やインセンティブプラン)は、通常、非常に幼稚に管理されています。これは、プロトコルの経済的持続可能性を検証するのが難しいことを意味します。多くのプロトコルが有機的に接続され、データパイプラインを作成する場合、そのパイプラインがうまく機能するかどうかの不確実性はさらに大きくなります。
- データ取得時間が遅い------プロトコルは通常、多くのノードの合意を通じて取引を処理しますが、これは従来のITビジネスロジックと比較して情報処理の速度と量を制限します。このボトルネックは、パイプラインを構成するすべてのプロトコルのパフォーマンスが大幅に向上しない限り、解決が難しいです。
- Web3データの真の価値------ブロックチェーンは孤立したシステムであり、現実世界と接続されていません。Web3データを収集する際には、収集されたデータが意味のある洞察を提供できるかどうか、データパイプラインを構築するコストを支払うのに十分かを考慮する必要があります。
- 異なる文法------既存のITデータインフラストラクチャとブロックチェーンインフラストラクチャの運用方法は非常に異なります。使用されるプログラミング言語も異なり、ブロックチェーンインフラストラクチャは通常、低レベルの言語やブロックチェーンのニーズに特化した新しい言語を使用します。これにより、新しい開発者やサービスユーザーが各データ要素を処理する方法を学ぶのが難しくなります。なぜなら、彼らは新しいプログラミング言語やブロックチェーンデータを処理するための新しい思考方法を学ぶ必要があるからです。
4.パイプライン化されたWeb3データレゴ
現在のWeb3データ要素間には接続がなく、それぞれが独立してデータを抽出し処理しています。これにより、情報処理の協同効果が難しくなります。この問題を解決するために、この記事ではIT市場で一般的に使用されているデータパイプラインを紹介し、既存のWeb3データ要素をそのパイプラインにマッピングします。これにより、ユースケースがより具体化されます。
4.1 一般的なデータパイプライン
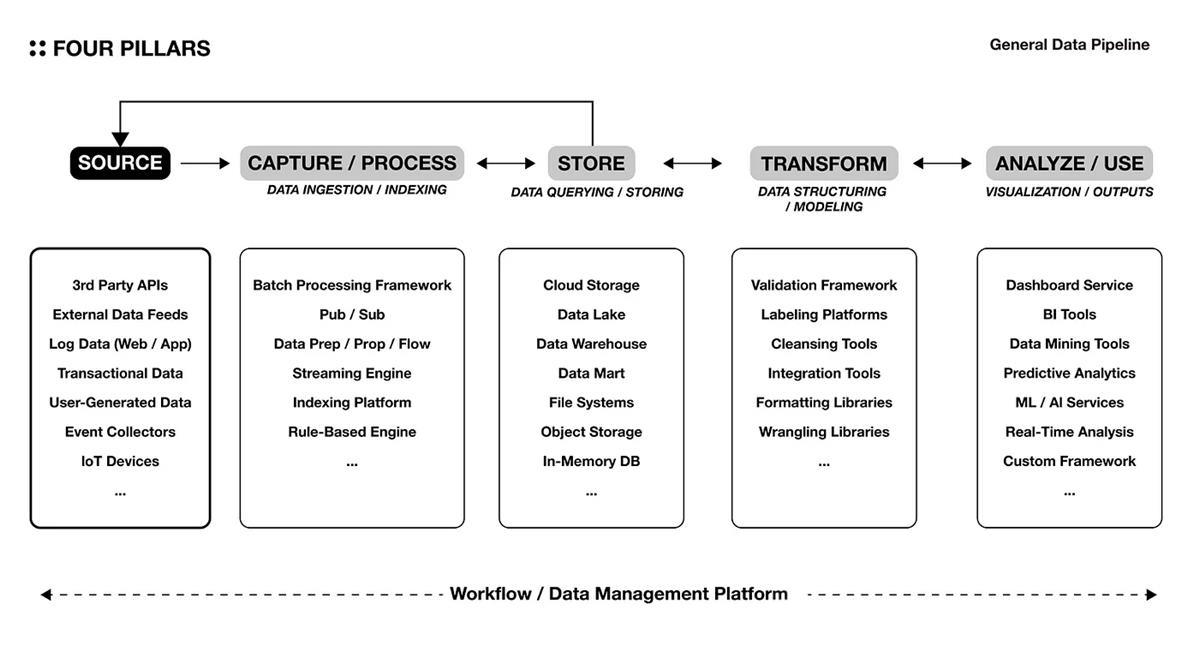
データパイプラインの構築は、日常生活の中で繰り返しの意思決定プロセスを概念化し、自動化するプロセスのようなものです。これにより、人々は必要な特定の質の情報をいつでも取得し、意思決定に利用できます。処理する非構造化データが多いほど、情報を使用する頻度が高く、リアルタイム分析が必要な程度が高いほど、この一連のプロセスを自動化することで、将来の意思決定に必要な能動性の時間とコストを節約できます。
上の図は、既存のITインフラストラクチャ市場でデータパイプラインを構築するために使用される一般的なアーキテクチャを示しています。分析目的に適したデータは、正しいデータソースから収集され、データの性質や分析要件に応じて適切なストレージソリューションに保存されます。たとえば、データレイクはスケーラブルで柔軟な分析のための生データストレージソリューションを提供し、データウェアハウスは構造化データの保存に焦点を当て、特定のビジネスロジックに最適化されたクエリと分析を行います。その後、データはさまざまな方法で洞察や実用的な情報に処理されます。
各ソリューションレイヤーも、パッケージサービスの形で提供できます。データの抽出からロードまでの一連のプロセスを接続するETL(抽出、変換、ロード)SaaS製品群もますます注目されています(例:FiveTran、Panoply、Hivo、Rivery)。順序は常に一方向ではなく、組織の具体的なニーズに応じて各レイヤーはさまざまな方法で相互接続できます。データパイプラインを構築する際に最も重要なのは、データが各サーバーレイヤーに送信され、受信される際に発生する可能性のあるデータ損失リスクを最小限に抑えることです。これは、サーバーのデカップリングの程度を最適化し、信頼できるデータストレージおよび処理ソリューションを使用することで実現できます。
4.2 チェーン上環境のパイプライン
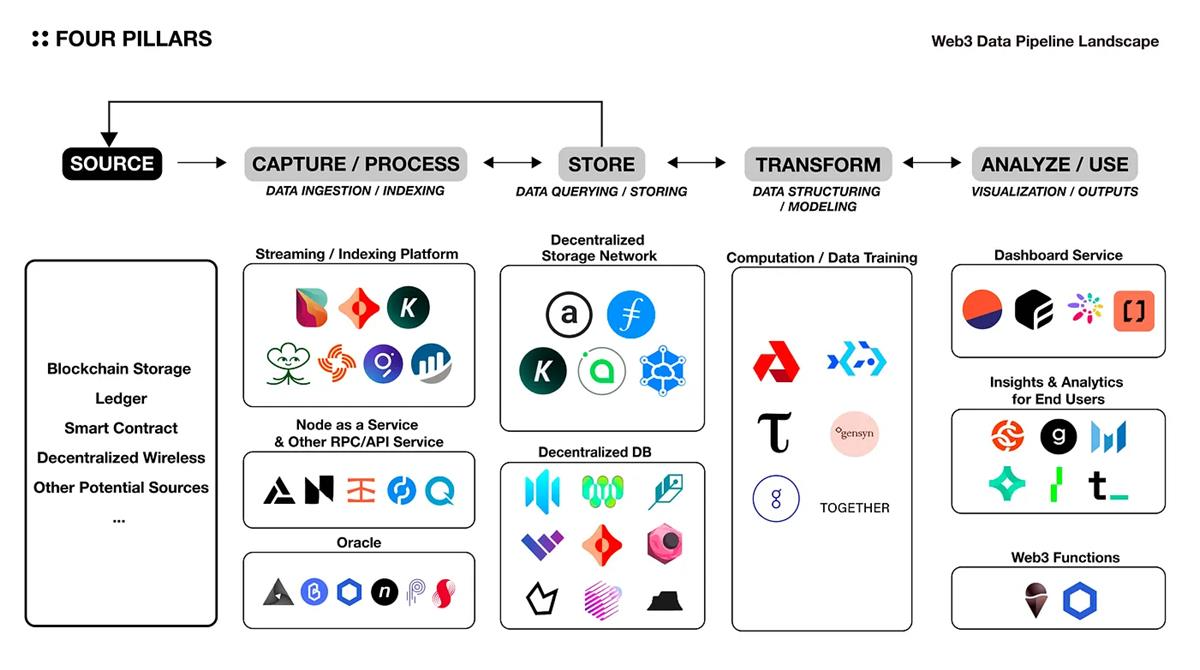
前述のデータパイプラインの概念図は、上図のようにチェーン上環境に適用できますが、完全に分散化されたパイプラインは形成できないことに注意が必要です。なぜなら、各基本コンポーネントはある程度、集中化されたオフチェーンソリューションに依存しているからです。さらに、上図には現在すべてのWeb3ソリューションが含まれておらず、分類の境界が曖昧な場合があります。たとえば、KYVEはストリーミングプラットフォームとしてだけでなく、データレイクの機能も持ち、データパイプライン自体と見なすことができます。また、Space and Timeは分散型データベースとして分類されていますが、Rest APIやストリーミングなどのAPIゲートウェイサービス、ETLサービスも提供しています。
4.2.1 キャプチャ/処理
一般ユーザーやdAppがサービスを効率的に使用/操作できるようにするためには、取引、状態、ログイベントなど、主にプロトコル内で生成されたデータソースを簡単に識別しアクセスできる必要があります。このレイヤーは、オラクル、メッセージング、認証、API管理を含むプロセスを支援するミドルウェアの役割を果たします。主要なソリューションは以下の通りです。
ストリーミング/インデックスプラットフォーム
Bitquery、Ceramic、KYVE、Lens、Streamr Network、The Graph、各プロトコルのブロックエクスプローラーなど。
ノードサービスおよびその他のRPC/APIサービス
Alchemy、All that Node、Infura、Pocket Network、Quicknodeなど。
オラクル
API3、Band Protocol、Chainlink、Nest Protocol、Pyth、Supraオラクルなど。
4.2.2 ストレージ
Web2ストレージソリューションと比較して、Web3ストレージソリューションは持続性や分散化などのいくつかの利点があります。しかし、高コスト、データの更新やクエリの困難などの欠点もあります。したがって、これらの欠点を解決し、Web3上の構造化された動的データを効率的に処理するためのさまざまなソリューションが登場しました------各ソリューションの特徴は、処理するデータタイプ、構造化されているかどうか、埋め込みクエリ機能があるかどうかなど、さまざまです。
分散型ストレージネットワーク
Arweave、Filecoin、KYVE、Sia、Storjなど。
分散型データベース
Arweaveベースのデータベース(Glacier、HollowDB、Kwil、WeaveDB)、ComposeDB、OrbitDB、Polybase、Space and Time、Tablel andなど。
* 各プロトコルには異なる永続ストレージメカニズムがあります。たとえば、Arweaveはブロックチェーンベースのモデルで、Ethereumストレージのようにデータを永続的にチェーン上に保存しますが、Filecoin、Sia、Storjは契約ベースのモデルで、データをオフチェーンに保存します。
4.2.3 変換
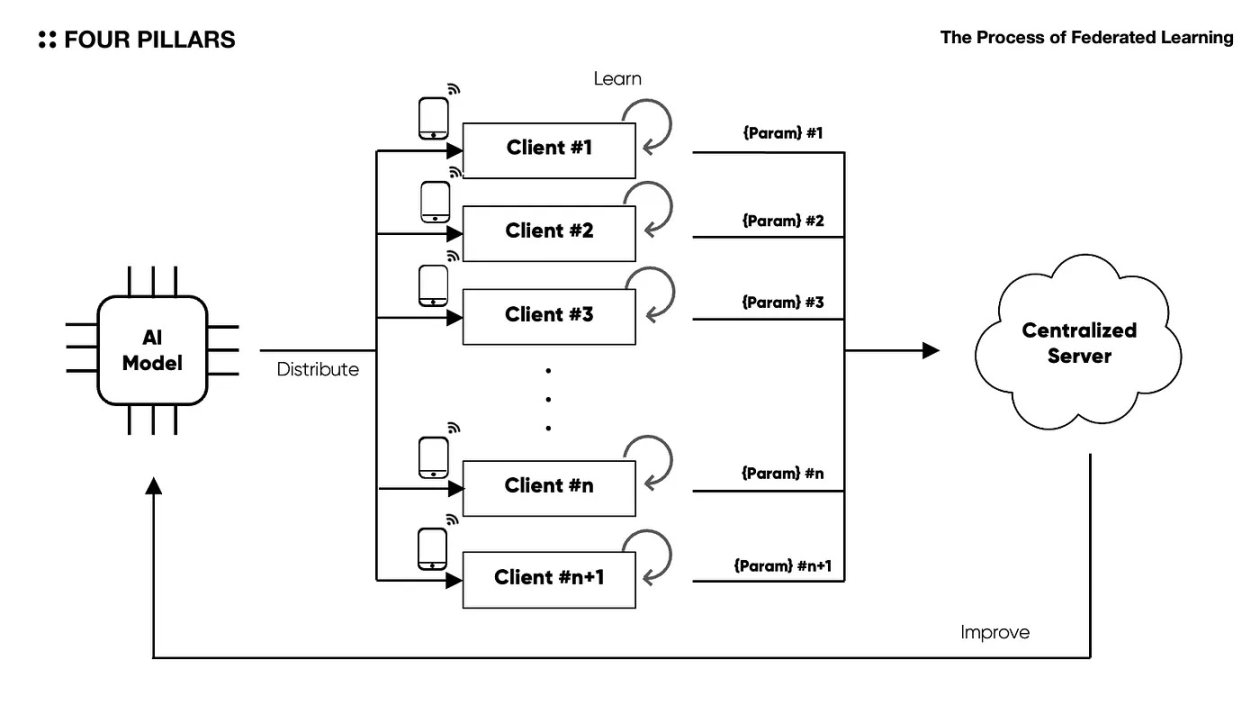
Web3の文脈では、変換レイヤーはストレージレイヤーと同様に重要です。これは、ブロックチェーンの構造が基本的に分散ノードの集合で構成されているため、拡張性のあるバックエンドロジックを使用することが容易になるからです。人工知能業界では、これらの利点を活用して連邦学習の分野での研究が積極的に探求され、機械学習や人工知能操作のためのプロトコルが登場しています。
データトレーニング/モデリング/計算
Akash、Bacalhau、Bittensor、Gensyn、Golem、Togetherなど。
* 連邦学習は、原始モデルを複数のネイティブクライアントに分散させ、保存されたデータを使用してトレーニングし、中央サーバーで学習したパラメータを収集して人工知能モデルをトレーニングする方法です。
4.2.4 分析/使用
以下に示すダッシュボードサービスと最終ユーザーの洞察および分析ソリューションは、ユーザーが特定のプロトコルからさまざまな洞察を観察し発見することを可能にするプラットフォームです。これらのソリューションのいくつかは、最終製品にAPIサービスを提供しています。ただし、これらのソリューションのデータは常に正確であるとは限らず、ほとんどが個別のオフチェーンツールを使用してデータを保存および処理しているため、ソリューション間のエラーも観察されることがあります。
同時に、「Web3 Functions」と呼ばれるプラットフォームがあり、これはGoogle Cloudなどの集中型プラットフォームが特定のビジネスロジックをトリガー/実行するのと同様に、スマートコントラクトの実行を自動化/トリガーします。このプラットフォームを使用することで、ユーザーはWeb3ネイティブな方法でビジネスロジックを実現でき、単にチェーン上のデータを処理することで洞察を得るだけではありません。
ダッシュボードサービス
Dune Analytics、Flipside Crypto、Footprint、Transposeなど。
最終ユーザーの洞察と分析
Chainalaysis、Glassnode、Messari、Nansen、The Tie、Token Terminalなど。
Web3 Functions
ChainlinkのFunctions、Gelato Networkなど。
5.まとめの考察

カントが言ったように、私たちは物事の現象を見ることしかできず、その本質に触れることはできません。それにもかかわらず、私たちは「データ」と呼ばれる観察記録を利用して情報と知識を処理し、情報技術の革新が文明の発展をどのように推進しているかを見ています。したがって、Web3市場にデータパイプラインを構築することは、分散化の特徴を持つだけでなく、これらの機会を実際に捉えるための出発点として重要な役割を果たすことができます。この記事をまとめるために、いくつかの考察を述べたいと思います。
5.1 ストレージソリューションの役割がますます重要になる
データパイプラインを持つための最も重要な前提は、データとAPIのガバナンスを確立することです。ますます多様化するエコシステムの中で、各プロトコルが作成する規範は再び作成され続け、多チェーンエコシステムの断片化された取引記録は、個人が包括的な洞察を導き出すことをより困難にします。したがって、「ストレージソリューション」は、断片化された情報を収集し、各プロトコルの規範を更新して統一フォーマットで統合データを提供できるエンティティです。私たちは、既存市場のストレージソリューション(SnowflakeやDatabricksなど)が急速に発展し、巨大な顧客基盤を持ち、パイプライン内の各レイヤーを運営することで垂直統合を行い、業界の発展をリードしていることを観察しています。
5.2 データソース市場における機会
データがより入手しやすくなり、処理プロセスが改善されると、成功したユースケースが現れ始めます。これにより、データソースと収集ツールが爆発的に増加する正の循環効果が生まれます------2010年以降、データパイプラインを構築する技術が大きな進展を遂げ、毎年収集されるデジタルデータの種類と量は指数的に増加しています。この背景をWeb3市場に適用すると、将来的にはチェーン上で多くのデータソースが再帰的に生成される可能性があります。これは、ブロックチェーンがさまざまなビジネス領域に拡張されることを意味します。この点において、Ocean Protocolなどのデータ市場や、HeliumやXNETなどのDeWi(分散型無線)ソリューション、ストレージソリューションを通じてデータ収集が進むことが期待されます。
5.3 意義のあるデータと分析が重要
しかし、最も重要なのは、真に必要な洞察を引き出すためにどのデータを準備すべきかを常に問い続けることです。データパイプラインを構築するために明確な仮説を検証せずに構築することほど無駄なことはありません。既存市場はデータパイプラインを構築することで多くの革新を実現しましたが、無意味な失敗を繰り返すことで無数の代償を払ってきました。技術スタックの発展について建設的な議論を行うことも良いことですが、業界は、どのデータをブロック空間に保存すべきか、データはどのような目的で使用されるべきかといったより基本的な問題について考え、議論する時間が必要です。「目標」は、実用的なインテリジェンスとユースケースを通じてWeb3の価値を実現することであり、その過程で複数の基本コンポーネントを開発し、パイプラインを完成させることがこの目標を達成するための「手段」となります。






















