
ユーザーデータプライバシー保護:Web 2.0とWeb 3.0の違いは何ですか?

 Web 2.0の背景において、ユーザーデータのプライバシーとセキュリティの仮定は、プラットフォームへの信頼と政府機関の監視への信頼に基づいていますが、ユーザーは依然として個人データに対するコントロール権を欠いています。この問題を解決するために、Web 3.0の背景で提案されたユーザーデータプライバシー保護の方案は、すべて個人データのコントロール権を中心に構想されています。
Web 2.0の背景において、ユーザーデータのプライバシーとセキュリティの仮定は、プラットフォームへの信頼と政府機関の監視への信頼に基づいていますが、ユーザーは依然として個人データに対するコントロール権を欠いています。この問題を解決するために、Web 3.0の背景で提案されたユーザーデータプライバシー保護の方案は、すべて個人データのコントロール権を中心に構想されています。著者:万向ブロックチェーンチーフエコノミストオフィス 王普玉
監修:万向ブロックチェーンチーフエコノミスト 邹伝偉
「ポータルサイト」を代表とするWeb 1.0や「ソーシャルプラットフォーム」を代表とするWeb 2.0を経て、インターネットのビジネスと技術の進化により、ユーザーは徐々にネット上でさまざまなリソースやデータを無料で取得することに慣れてきました。プラットフォームが有料製品を提供しても、ユーザーは依然として他の無料のチャネルを探す傾向があります。インターネット市場はなぜ無料の製品やサービスを提供するのでしょうか?
市場には本当に熱心な「慈善家」がいて、ユーザーに無料のネット「ランチ」を提供しているのでしょうか?プラットフォームは無料の製品やサービスでユーザーを引き付け、その後、プラットフォームとは無関係なユーザーの身分データや行動データを大量に収集し、転売、精密なユーザー画像、広告などのチャネルを通じてユーザーデータをマネタイズします(図1参照)。このマネタイズモデルは、プラットフォームにとって「リソースサブスクリプションモデル」に依存するよりもはるかに高い収益をもたらします。
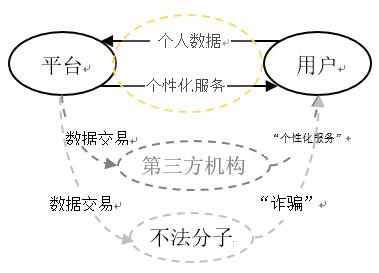
図1:ユーザーデータの流通(資料出典:著者自作)
個人データを犠牲にして無料のネットリソースを得るという背景の中で、一部の志を持つ人々がインターネットプラットフォームに対抗し始めました。万維網の父Tim Berners-Leeや、イーサリアム共同創設者Gavin Woodなどが、ユーザーのプライバシーを保護することを目指した新世代のインターネットWeb 3.0を提唱しました。
万向ブロックチェーンの研究報告書第230号「Web3アーキテクチャの雛形とミドルウェア」では、Web 3.0の3つのタイプを詳しく紹介しています。それは、プライバシー保護を重視したセマンティックWeb 3.0、プライバシーとデータの所有権および制御権を重視したパブリックチェーンWeb 3.0、そしてWeb 3.0を空間ネット(メタバース)として描写するWeb 3.0です。
一、 データプライバシー保護の紹介
データのプライバシー保護とは具体的に何を指すのでしょうか?万向ブロックチェーンの研究報告書第173号「ユーザー画像実現から見るデータプライバシー問題」では、ユーザー画像データを2つのカテゴリに分けています。一つはユーザーの身分データ、もう一つはユーザーの身分データに関連する行動データで、時間、場所、イベントなどが含まれます。
現在の市場の主流な見解は、ユーザーの身分データと行動データの関連を切断できれば、ユーザーのプライバシーを効果的に保護できるというものです。この方向に沿って、市場には2種類のソリューションが登場しました。一つはWeb 2.0の発展問題に基づくユーザープライバシー保護ソリューションで、主な参加者は携帯電話メーカーとすべてのインターネットプラットフォームです。もう一つは、さまざまな分散型技術とプライバシー技術を応用したWeb 3.0ユーザーデータプライバシー保護ソリューションです。以下でこの2つのアプローチを詳しく比較します。
(一)Web 2.0ユーザーデータプライバシー保護
Web 2.0の段階では、各国政府のインターネットデータに対する規制圧力に迫られ、ユーザーデータのプライバシー管理が徐々にインターネットプラットフォームに重視されるようになりました。万向ブロックチェーンの研究報告書第215号「2021年業界回顧:規制編」では、EUや中国が発布した個人データ保護法案やその要点を詳しく列挙しました。この法案は、プラットフォームが個人情報を処理する際のルール、個人の権利、義務、責任などを詳細に規定しており、プラットフォームが個人情報を処理する前に個人の同意を得ることを明確に要求しています。
2つの参加者、すなわち携帯電話メーカーとインターネットプラットフォームは、それぞれ異なる出発点から2つの全く異なるユーザーデータプライバシーソリューションを提案しました。
1、携帯電話メーカーが提案するユーザープライバシーソリューション
IMEIコード(国際移動体装置識別番号)は、各携帯電話の身分証明書のようなもので、各IMEIコードはユニークです(図2参照)。ユーザーがアカウント名やパスワードを入力しなくても、インターネットプラットフォームはデバイスのIMEIコードを通じて特定のユーザーの身分に関連付けることができます。
インターネットプラットフォームがユーザーの行動データを過剰に収集するのを防ぐために、携帯電話メーカーはOAID(匿名デバイス識別子)技術を開発しました。インターネットプラットフォームがデバイスのIMEIコードを読み取る際、デバイスはIMEIコードの代わりに仮想IDを提供し、毎回提供されるIDはランダムであるため、インターネットプラットフォームは特定のユーザーの身分に関連付けることができません。
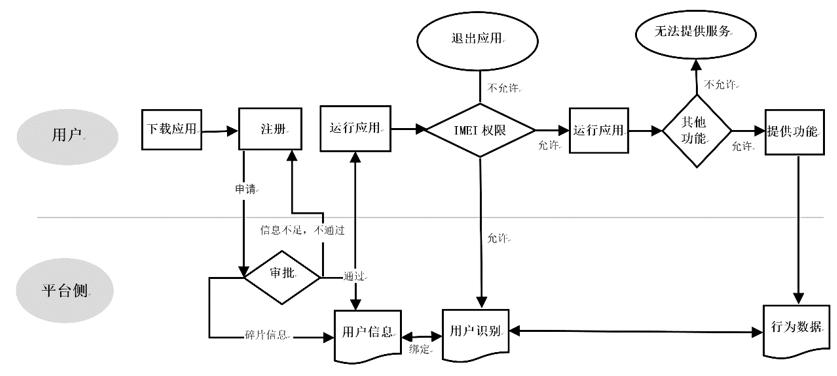
図2:アプリケーションデータ収集プロセス(資料出典:著者自作)
上記の方法は、ユーザーがアカウント名やパスワードを入力しない場合に個人データのプライバシー保護に役立ちますが、ユーザーが個人アカウントにログインすると、身分データをアプリケーションプラットフォームに通知することになり、OAID技術の機能は無効になります。
初期の携帯電話メーカーはデータ管理を十分に重視していなかったため、ユーザーがインターネットアプリをダウンロードすると、すべてのデータへのアクセス権がデフォルトで有効になっていました。これにより、インターネットプラットフォームは業務に無関係な大量のユーザーデータを無制限に収集しました。このような状況下で、携帯電話メーカーはデバイスのプライバシー安全性を確保するために、インターネットプラットフォームのデータ使用に対する強いリマインダー機能を追加し、ユーザーにデータの使用を許可させるようにしました。例えば、アルバムデータの使用に関しては、図3のように、Appleの携帯電話のアルバムデータの許可は、すべての写真、選択した写真、なしの3つのモードに分かれています。この許可により、ユーザーは写真データに対してより細かい管理能力を持つことができ、特に「選択した写真」機能により、インターネットプラットフォームはユーザーが表示したい写真のみを収集できるようになり、データ収集の範囲を制限しました。
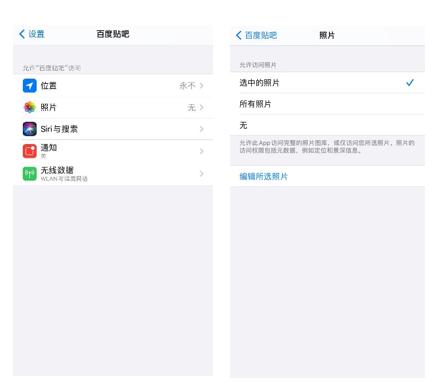
図3:Appleの個人データ管理許可(資料出典:Appleのスクリーンショット)
2、プラットフォームが提案するユーザープライバシーソリューション
携帯電話メーカーの能動的な保護に対して、インターネットプラットフォームはさまざまなデータ保護法案の圧力に迫られ、受動的にユーザープライバシー保護ソリューションを提案しました。受動的な理由は明白で、2021年の財務報告書から、広告収益が各インターネットプラットフォームの発展において非常に重要な部分であることがわかります。
図4のように、2021年のPinduoduoやWeiboの広告収益は総収入の80%以上を占め、KuaishouやBaiduは50%以上です。広告の価値の核心はデータにあります。もしインターネットプラットフォームがユーザーデータのプライバシー保護を能動的に実施し始めると、既存のビジネスモデルを放棄することを意味し、これはインターネットプラットフォームの経済モデルに反します。
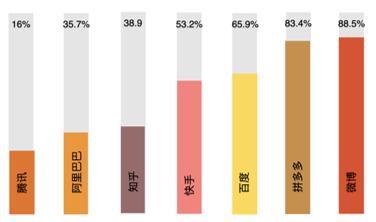
図4:2021年各インターネット企業の広告収入占比(資料出典:各企業の財務報告書)
インターネットプラットフォームが提案するユーザープライバシー保護ソリューションは、関連する法律や規制の監視要件に応えるためだけのものであり、「中華人民共和国個人情報保護法」が施行された後、図5のように、各プラットフォームは個人プライバシー設定画面を増やしたり調整したりし、ユーザーデータの収集タイプ、使用範囲、使用方法などを詳細に説明し、ユーザーに個人データの使用に対する選択権を増やしました。
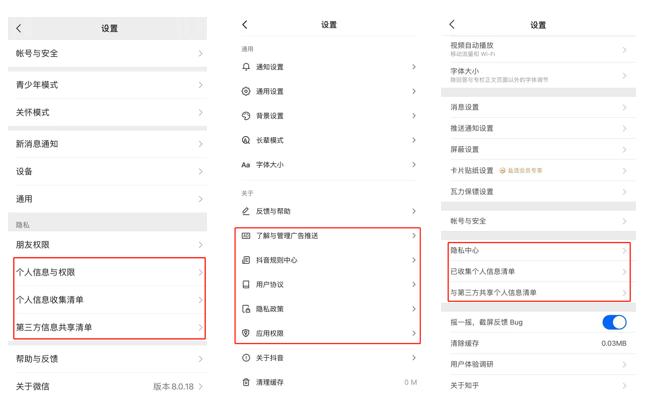
図5:WeChat、Douyin、Zhihuのアプリ設定画面
3、まとめ
携帯電話メーカーのユーザーデータのプライバシー保護は、その経済モデルに関連しており、携帯電話の販売を増やすことで収益を増やすことを目指しています。デバイスのプライバシー安全性は販売に大きな影響を与えるため、携帯電話メーカーがOAID技術やさまざまなデータ許可機能を開発してユーザーデータのプライバシー保護を強化する理由は理解できます。
携帯電話メーカーに対して、インターネットプラットフォームが提案するユーザープライバシー保護ソリューションは、規制遵守要件を満たすためだけのものであり、彼らの経済モデルとは無関係であり、むしろ反するものであるため、インターネットプラットフォームがユーザープライバシーの解決策を受動的に提案する理由も理解できます。
現在提案されているプライバシー保護は、データ使用に関するいくつかの説明に過ぎず、積極的な保護措置が欠けています。ユーザーのデータが収集された後、それが画像に使用されるか、取引されるかどうか、ユーザーは依然として知ることができません。その理由は、ユーザーデータがインターネットプラットフォームの集中型サーバーに保存されており、ユーザーが集中型サーバーに対する制御権を欠いているからです。
二、Web 3.0ユーザー身分プライバシー保護ソリューション
Web 2.0の背景では、ユーザーデータのプライバシーとセキュリティの仮定はプラットフォームへの信頼と政府機関の監視への信頼に基づいていますが、ユーザーは依然として個人データの制御権を欠いています。この問題を解決するために、Web 3.0の背景で提案されたユーザーデータプライバシー保護ソリューションは、すべて個人データの制御権に焦点を当てています。
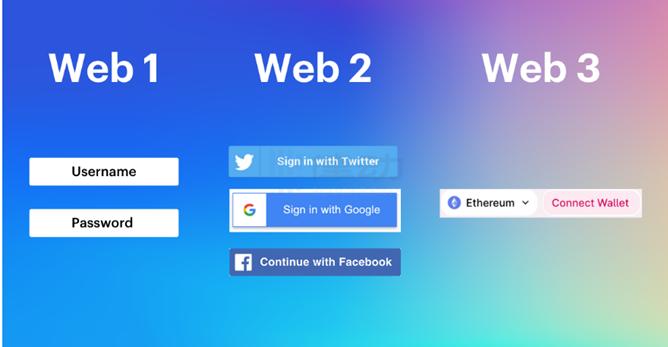
図6:ユーザーのログイン方法の比較(資料出典:James Beck)
図6のように、Web 1.0の段階では、ユーザーはユーザー名とパスワードでアカウントにログインしていました。Web 2.0の段階に入ると、ユーザーはアカウントやパスワードを記録することに悩む必要がなくなり、身分情報を繰り返し入力することに煩わされることもなくなりました。「Sign in with」や「Continue with」をクリックするだけで、Twitter、Google、Facebookなどのアプリケーションのアカウント情報を承認できます。
身分データがAPIやSDKを通じて他のアプリケーションに取得または読み取られ、アカウント名やパスワードを入力せずにユーザーの身分を確認できます。この方法はユーザー体験を向上させましたが、その代償としてTwitterやGoogleなどのインターネット巨人がより多くのユーザー行動データを収集することになりました。Web 1.0でもWeb 2.0でも、ユーザーデータは集中型サーバーに保存されており、ユーザーは制御権を欠いています。
制御権の問題を解決するために、W3Cが提案した分散型識別子DIDに基づき、明文の個人身分情報の代わりに文字列を使用し、その文字列にマッピングされた行動データはすべてユーザーが制御できるサーバーに保存されます。DIDの核心理念に基づき、現在2つの身分プライバシーソリューションがあります。第一のものはuPortを代表とする分散型アプリケーションDAppで、身分情報の識別子の代わりに一連の代理契約アドレスを使用します(図7参照)。
他のプラットフォームは代理契約アドレスを認識することで身分確認を行い、TwitterやGoogleなどの集中型アプリケーションの承認を代替し、データの制御権を掌握します。第二のものは、異なる時間、異なるプラットフォーム、異なる目的で異なる識別子を生成し(図8参照)、そのデータをそのプロトコルをサポートする身分ウォレットに保存することで、個人データの制御権を掌握します。
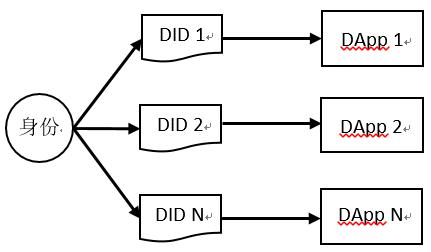
図7:身分識別子とDAppの一対一マッピング(資源出典:著者自作)
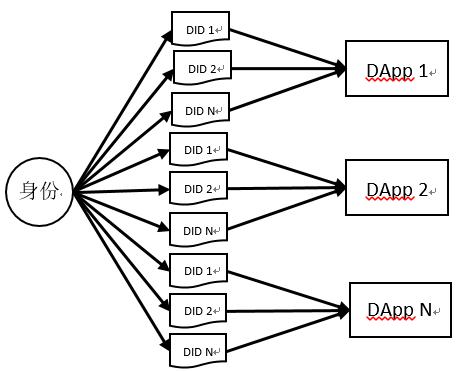
図8:身分識別子とDAppの多対一マッピング(資源出典:著者自作)
(一)身分識別子とDAppの一対一のユーザープライバシーソリューション
Consensysが2017年に発表したuPortを例にとって説明します。「Sign in with Twitter」や「Continue with Facebook」機能に似て、図9のように、uPortも「Continue with uPort」機能を提供し、ユーザーが他のプラットフォームで身分確認やパスワードなしでログインできるようにします。
図9:uPortログイン承認(資料出典:アプリケーションインターフェースのスクリーンショット)
集中型プラットフォームとの違いは、uPortがユーザーが制御できる独立した分散型身分サービスプラットフォームであり、技術的に2つの機能を実現しています。第一に、ユーザーはuPortの身分データを直接制御でき、ユーザーは第三者プラットフォームに何の情報を表示するかを自分で決定できます。第二に、身分関連データはユーザーが制御できるサーバーに保存されており、ユーザーはどのデータを保存するか、どのくらいの期間保存するか、誰がそのデータを読むことができるかを決定できます。
まずはデータの制御権です。前述のAppleの権限設定と同様に、ユーザーはuPort内で個人データを管理および制御できます。従来のアプリとは異なり、DAppはユーザーがデータ保存サーバーに接続するためのツールに過ぎません。uPortのDAppがサービスを提供しなくなっても、ユーザーのデータを持ち去ることはありません。
ユーザーは依然としてニーモニックや秘密鍵を使用して他のツール(MetamaskやImtokenなどの分散型アプリ)を通じてデータを取り戻すことができます。このプロセスで最も重要な点は、データがユーザーが制御できるアドレスに保存される必要があることです。ユーザーの身分確認プロセスでは、TwitterやFacebookなどの集中型プラットフォームがuPortをサポートすれば、uPortを通じて承認を受け、暗号化された環境で身分確認を完了できます。このプロセスでは、インターネットプラットフォームは代理契約アドレス(代理契約アドレスは分散型身分識別子に相当)しか得られず、他の具体的な確認情報を知ることはできません。
前述のように、Web 2.0ユーザーは個人データの制御権を欠いていますが、その主な理由はユーザーデータが集中型サーバーに保存されているからです。この問題に対して、Web 3.0のデータ保存方法には2つの解決策があります。創作プラットフォームMirrorを例にとると、第一の保存方法は分散型保存ソリューションで、ファイルサイズが1M以下のものはArweaveを通じて永久保存されます。
データは分割され、暗号化されて分散型サーバーに保存され、Arweaveチェーン上の秘密鍵を持つユーザーのみが完全なデータを取得でき、他の人は取得できません。コストを考慮して、1M以上(動画や画像など)のファイルは第二の方法を使用し、Mirrorが指向する集中型サーバーに保存されます。
この方法ではデータのプライバシーとセキュリティを保証することはできません。Mirrorが集中型サーバーのメンテナンスを停止すれば、すべてのユーザーデータも失われます。Mirrorがなぜ2つの保存ソリューションを提案したのかを説明する必要があります。その理由は、現在すべてのデータ保存にかかる費用がMirrorによって一時的に補填されているためです。ユーザーが1M以上のファイルもArweaveに保存したい場合は、一定のコストを自分で支払う必要があります。
上記の内容は、ユーザーがデータの制御権を取り戻すことでデータプライバシーの問題を解決することを目的としていますが、それは絶対的ではありません。uPortはユーザーにデータの制御権を与えますが、一定の程度でデータのプライバシーを保護できない可能性があります。通常、uPortに対応する各身分識別子(代理契約アドレス)はユニークであり、チェーン上の大量のデータがその代理アドレスに関連付けられると、いくつかの第三者ツール(例えば、Whale Analysisなど)を通じてユーザーの身分を判断することができ、ユーザーの身分と行動データの関連を完全に切断することはできません。この問題を解決するために、パブリックチェーン上でAztecのzk.moneyはイーサリアムアカウントシステムを放棄し、UTXOシステムに移行し、ゼロ知識証明を使用して、票記帳形式で所有権の変更を完了します。
これにより、第三者は具体的なアドレスを追跡できなくなります。ゼロ知識証明以外にも、イーサリアムのミキサーであるtornado.cashは、取引プロセス中にスマートコントラクトをブラックボックスとして利用し、送信者と受信者の関係を断ち切り、第三者が具体的なアドレスを追跡できないようにします。ゼロ知識証明でもミキサーでも、チェーン上のアドレスが公開されることによる資産取引データの公開問題を効果的に解決できます。
しかし、実体経済のアプリケーションにおいて、膨大で多様な個人身分および行動データに直面すると、単純なゼロ知識証明やミキサーの方法ではユーザープライバシー保護の実現可能性は高くなく、より完全な身分管理ソリューションが必要です。
(二)身分識別子とDAppの多対一のユーザープライバシーソリューション
万向ブロックチェーンの業界研究報告書「DID:新しい身分識別技術」では、DIDの技術原理を詳しく紹介しており、その核心的な方法は、異なる主体が異なる時間、異なるアプリケーションプラットフォーム、異なる目的に基づいて異なるDID識別子を使用して身分確認を行い、各DID識別子に関連する行動データはすべてユーザーが制御できるアドレスに保存されるというものです。
Web 2.0の用語で説明すると、毎回異なるユーザー名とパスワードでプラットフォームにログインし、プラットフォームが特定のユーザーの身分に関連付けることができないようにし、すべてのデータが顧客が制御できるアドレスサーバーに保存されます。この方法は、身分識別子とDAppの一対一のユーザープライバシーソリューションで発生するすべての問題を解決できます。
特定のユニークアドレスのユーザー画像を大量のデータを通じて作成したり、単一の身分識別子の漏洩によってすべてのデータが漏洩する問題などを含みます。身分識別子とDAppの多対一を通じて、異なる身分識別子が行動データを隔離し、データプライバシーの問題を別の次元から解決します。
これは市場の努力の方向ですが、解決すべき多くのボトルネックが残っています。法律面、ビジネス面、技術面など、現在市場に存在するさまざまな分散型身分識別子ソリューションの中で、多対一のユーザープライバシーソリューションが本当に開発されたものはなく、大多数はまだ概念段階に留まっています。
三、考察とまとめ
上記の内容の比較から、Web 2.0とWeb 3.0のユーザープライバシー保護の最大の違いは、ユーザーが個人データに対して絶対的な制御権を持っているかどうかです。倫理的な観点から見ると、Web 3.0が推進するデータの絶対的な制御権は非常に魅力的であり、個人データ管理において画期的な意義を持ち、自分のデータを自分で管理できることを実現します。しかし、経済やビジネスの観点から見ると、このデータの絶対的な制御権は本当に価値があるのでしょうか?
この価値は2つのレベルで考えることができます。第一のレベルはユーザーにとっての価値です。第二のレベルは、個人が保有するデータと経済発展の価値が一致しているかどうかです。まず、ユーザーにとっての価値について議論します。ユーザープライバシー保護は主に倫理的な価値ですが、ビジネスの観点から見ると、Web 3.0には「慈善家」が存在しません。
すべてのデータプライバシー保護のソリューションには、誰かが費用を負担する必要があります。どれだけのユーザーがデータプライバシープラットフォームの開発コストを負担する意欲があるでしょうか?また、どれだけの人が個人データの維持コスト(時間コストや資金コストを含む)を長期間にわたって負担できるでしょうか?例えば、銀行や通信会社で業務を行う際に契約書に署名する必要がありますが、どれだけの顧客が契約内容を注意深く読むために時間をかけるでしょうか?
したがって、Web 3.0はユーザーに個人データを維持するために時間コストや資金コストをかけさせることになりますが、これには疑問を呈する必要があります。さらに、無料のネットリソースを使用することに慣れたユーザーは、Web 3.0でリソースを取得するために支払う意欲があるのでしょうか?
上記の問題に基づき、Web 3.0の一部のプロジェクトは個人データ取引市場などの解決策を提案しています。例えば、ユーザーが個人データの制御権を取り戻し、データを広告主、研究機関、金融機関などに使用を許可することで、Web 2.0の段階では得られなかった収益を得ることができます。
ユーザーはこの収益を使用してツールの開発やデータの維持コストを支払うことができ、このような提案は理想的に聞こえますが、ビジネスロジックが市場の試練に耐えられるかどうかには疑問があります。根本的な理由は、個人データが市場でどれだけの価値を持つかということです。これは非常に複雑な問題であり、本文では議論しません。
上記の提案とは異なり、データプライバシープラットフォームはパブリックチェーンのさまざまなプロジェクトで非常に人気があり、経済モデルも非常に明確です。プロジェクトはデータプライバシープラットフォームを開発し、ICO方式で資金を調達し、デジタル資産の価値が上昇するにつれて、プロジェクトは収益を得て、より多くの人々をプロジェクトの維持と管理に引き込むことができます。
しかし、このモデルは多くの国や地域で規制遵守の問題があり、このモデルから離れると、経済モデルをどのように考えるか、つまり誰がプライバシープラットフォームの開発費用を負担するのかという問題が生じます。さらに、デジタル経済社会において、どのように集中型プラットフォームの抵抗を突破するかという問題も、さらなる解決策が必要です。これらの問題に加えて、Web 3.0のプライバシー保護には以下の問題が残されています。
(一)ハッカーがプライバシー技術を悪用するのをどう防ぐか?
2022年2月20日、ハッカーはOpenSeaの1週間のスマートコントラクトのアップグレードの隙間を利用して、多くの高価値システムのNFTを盗み、イーサリアムのプライバシー取引プラットフォームTornado.cashを通じて1100ETHをミキシングし、OpenSeaはハッカーの取引アドレスを追跡できなくなりました。
主流の資産の底値を基に計算すると、ハッカーは少なくとも416.6万ドルの利益を得たことになります。この事件から、プライバシー技術は個人のプライバシーを保護できる一方で、悪意のある者に保護を提供することができることがわかります。安全事件が発生した場合、ユーザーはWeb 2.0の段階での安全保障を通じて権利を主張することが難しくなります。
(二)規制遵守要件をどう満たすか?
上記のハッカー攻撃事件が発生した場合、ユーザーの合法的な権利と資産の安全をどう保護するか?KYC(顧客を知ること、Know Your Customer)は不可欠です。KYCをどのように行うか?誰がKYCを担当するか?どのような方法でKYCを行うか?分散型ソリューションの下では、これらは新しい解決策が必要です。しかし、KYCによって個人データが漏洩することを防ぐ必要があります。これは他のプライバシー保護技術の努力をすべて無駄にすることになります。






