
Arweave 第 17 版白皮書解讀(2):數據索引, 唯一副本與 VDF

 “為什麼 Arweave 有比傳統區塊鏈更高效的驗證機制❓數據是如何被存儲在Arweave中的❓什麼是簡潔的訪問證明SPoA❓如何降低副本唯一性的風險❓什麼是可驗證的延遲函數(VDF)❓”硬核內容需要你細嚼慢嚥😂
“為什麼 Arweave 有比傳統區塊鏈更高效的驗證機制❓數據是如何被存儲在Arweave中的❓什麼是簡潔的訪問證明SPoA❓如何降低副本唯一性的風險❓什麼是可驗證的延遲函數(VDF)❓”硬核內容需要你細嚼慢嚥😂
本文將介紹 Arweave 最新白皮書的第三節。這一部分主要是對一些基礎性概念作一些解釋,為此後機制的介紹作好鋪墊。本來這部分還包括了 SPoRes 的機制論證,由於全是公式與數學推導過程,筆者覺得也許單獨拎出來解讀會更加合理一些。
Arweave 的挖礦機制將許多不同的算法和數據結構組合成一個非交互式且簡潔的數據複製存儲證明。在本文中,我們先抽象地理解機制概念,然後再對它們在 Arweave 挖礦過程中的使用進行描述。
區塊索引
Arweave 中最高的數據結構被稱為區塊索引(Block Index)。它是一個由三元組(3-tuples)組成的默克爾化列表,每個元組包含三個維度的信息,即區塊哈希(A Block Hash)、編織網絡大小(A Weave Size)和交易根(A Transaction Root)。這個列表以一個哈希默克爾樹的形式來表示,頂層的默克爾根代表了網絡中當前的最新狀態。這個根是由兩個元素的哈希組成------最新的元組(代表最新區塊)和前一個區塊索引的默克爾根。在創建區塊時,礦工將前一個區塊索引的默克爾根嵌入在新區塊中。
通過在每個區塊中構建並嵌入一個區塊索引的默克爾根,一個已對最新區塊執行了 SPV 證明的 Arweave 網絡節點能夠完全驗證任何之前的區塊。這與傳統的區塊鏈形成對比,在傳統區塊鏈中,驗證舊區塊中的交易需要回溯整個鏈進行完整驗證。而在 Arweave 中,在對網絡頂端進行 SPV 驗證之後,區塊索引驗證機制能夠讓用戶在對網絡頂端進行 SPV 驗證之後就可驗證編織網絡中的舊區塊,而不再需要用戶下載或驗證中間的區塊頭。
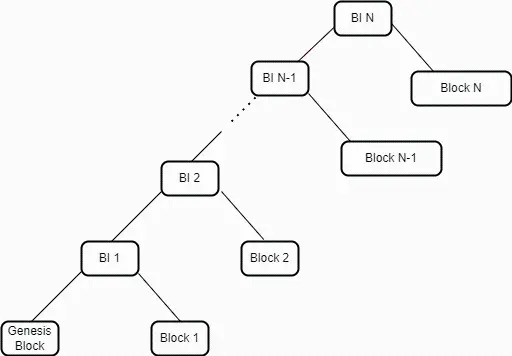
圖 1:區塊索引代表了 Arweave 網絡中區塊的一個默克爾樹
默克爾化數據
那數據是如何被存儲在網絡中的呢?
當信息需要被存儲到 Arweave 時,數據會根據規範被切分成 256 KB 的一個個數據塊(Chunk)。這些數據塊在準備好之後,就會構建一個默克爾樹,並將其根(稱為數據根 Data Root)提交到交易中。該交易被簽名並由上傳者發送到網絡。每個這樣構建的交易都被記錄在其所屬區塊的交易根(Transaction Root)裡。因此,一個區塊的交易根實際上是交易數據根的默克爾根。
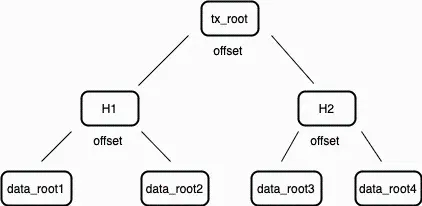
圖 2:交易根是區塊內每個交易中存在的數據根的默克爾根。
礦工將這樣的交易組合成一個區塊,使用交易內的數據根計算交易根,並將這個交易根包含在新區塊中。這個交易根最終會出現在頂層的區塊索引中。該過程創建了一個不斷擴展的默克爾樹,其中所有數據都按順序被分成了數據塊。
簡潔的訪問證明 SPoA
在 Arweave 網絡裡,默克爾樹中的節點通過標記數據在節點"左側"或"右側"的偏移位置來對數據塊進行標記。這種對節點的標記方法可以生成非常簡潔的默克爾證明,用來驗證數據集在特定位置上的數據塊的存在性。這類默克爾樹被稱作"不平衡樹",因為節點一邊的葉節點數可能不等於另一邊。這種結構可以用來構建一個簡潔的非交互式證明遊戲,用以驗證礦工硬盤中確實有相應的數據。
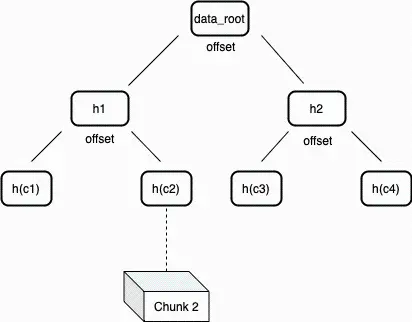
圖 3:數據根(data root)是單個交易中所有數據塊經過哈希處理的的默克爾根。
我們通過 Bob 與 Alice 的遊戲來理解什麼是簡潔的訪問證明(Succint Proof of Access SPoA)。Bob 想要驗證 Alice 是否在一個默克爾化數據集的特定位置存儲了數據。為了開始遊戲,Bob 和 Alice 應該擁有相同的數據集的默克爾根。遊戲分為三個階段:挑戰、證明構建和驗證。
- 挑戰:Bob 向 Alice 發送了一個數據塊的偏移量(也許理解成數據塊位置坐標會更清晰一點)來發起挑戰 ------ Alice 需要證明她能夠訪問這個位置索引的數據。
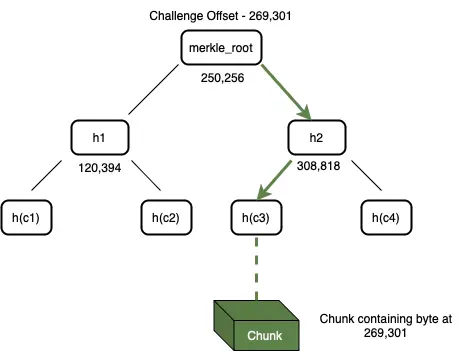
圖 4:Alice 可以通過遍歷帶有偏移量標籤的默克爾樹來搜索挑戰的數據塊(Chunk)
- 構建證明:收到這個挑戰後,Alice 開始構建證明。她搜索自己的默克爾樹,找到與偏移量對應的數據塊,如圖 4 所示。在構建證明的第一階段,Alice 從存儲中檢索到整個數據塊。然後,她使用該數據塊和默克爾樹構造一個默克爾證明路徑。她對整個數據塊進行哈希處理,以獲得一個 32 字節的字符串,並在樹中找到這個葉節點的父節點。父節點是一個包含其偏移量和兩個子節點的哈希值的節點,每個哈希值都是 32 字節長度。這個父節點被添加到證明中。然後遞歸地將每個上層的父節點添加到證明中,直到達到默克爾根。這一系列節點形成了默克爾路徑證明,Alice 將這個證明連同數據塊一起發送給 Bob。
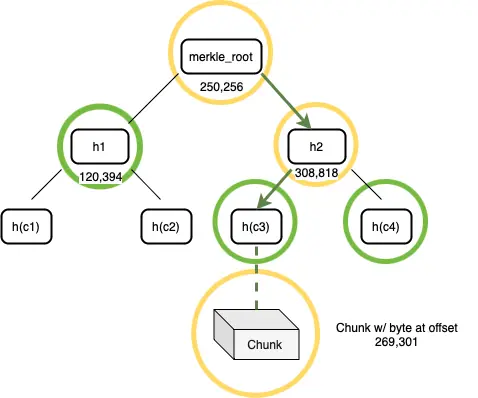
圖 5:一個挑戰偏移量的證明包括了存儲在偏移量處的數據塊及其默克爾路徑
- 驗證:Bob 接收到了來自 Alice 的默克爾證明以及數據塊。他通過一步步檢查從樹頂端到底部葉子的哈希值來核實默克爾證明的正確性。接著,他會對 Alice 提供的證明中的數據塊進行哈希運算,確認這個數據塊是否正是位於正確位置的那個數據塊。如果這些哈希值都對得上,就說明證明是有效的。但是,如果在驗證過程中發現任何哈希值不符,Bob 就會立即停止檢查,並斷定 Alice 的證明是無效的。這個檢驗的結果是一個簡單的是或否的過程,表明證明是否通過。
構造、傳輸和驗證這個簡潔訪問證明(SPoA)的複雜度是 O(logn),其中 n 代表數據集的大小,以字節計。實際上,這意味著在一個大小為 2 的 256 次方字節的數據集中,一個單字節的位置和正確性的證明可以僅通過 256 * 96B(最大路徑大小)+ 256 KB(最大數據塊大小)≈ 280 KB 來傳輸。
副本的唯一性
Arweave 網絡將挖礦能力設計為與礦工(或一組合作的礦工)可以訪問的編織網絡副本數量成正比。在沒有副本唯一性方案的情況下,一份數據的備份在內容上彼此完全相同。為了激勵並衡量單個數據的多個唯一副本,Arweave 使用了一種打包(Packing)系統來解決這個問題。
打包 Packing
打包機制確保了礦工無法用同一個數據塊來偽造多個 SPoA 證明。Arweave 引用了 RandomX 打包方案,將原始數據塊轉換為「打包」的數據塊,這個過程會為礦工帶來一定的計算成本。
打包的流程如下:
- 數據塊偏移量、交易根和挖礦地址被用於一個 SHA-256 哈希中,來生成一個打包密鑰 Packing Key。
- 打包密鑰被用作算法的熵,該算法在幾輪 RandomX 執行後生成一個 2 MB 的暫存器。這個打包機制的組成部分對於不遵守規則的礦工來說帶來了重大成本。
- 這個熵的前 256 KB 被用來通過費斯妥密碼(Feistel cypher)對塊進行對稱加密。通過運算產生出一個打包數據塊。
如果在連續讀取的時間周期內,打包數據塊的總成本超過了存儲已打包數據塊的成本,那麼礦工將被激勵去存儲唯一的數據塊,而不是按需打包數據塊。所以為了激勵這種正確的行為,就必須滿足以下條件:
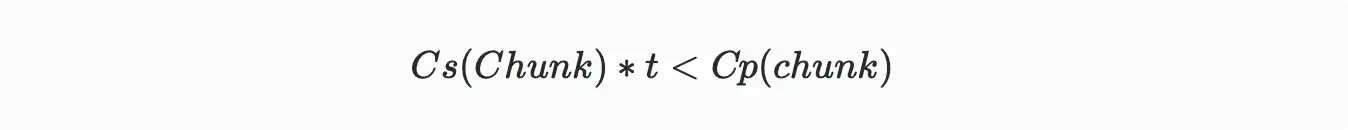
其中:
Cs= 存儲一個數據塊的單位時間成本
Cp= 打包一個數據塊的成本
t= 數據塊讀取之間的平均時間
其中打包總成本包括了計算所需的電力成本、專用硬件成本及其平均使用壽命。存儲成本同樣可以從硬盤成本、硬盤平均故障時間、運行硬盤的電力成本以及與運行存儲硬件相關的其他成本中計算得出。我們可以計算「按需」投機挖礦者與存儲打包數據塊的誠實挖礦者的成本比率,以估算激勵打包數據塊的安全邊際。實踐中,Arweave 使用一個安全比率------即按需投機挖礦的成本與存儲數據誠實挖礦的成本比率------在撰寫本文時,大約為 19:1。
RandomX
為了抵抗硬件加速策略,Arweave 採用了哈希算法 RandomX 對打包密鑰進行處理。RandomX 針對通用 CPU 進行了優化,通過在哈希過程中實行隨機代碼執行和多種內存密集型技術,極大限制了專用硬件如 GPU 與 ASIC 的計算效率。
RandomX 利用隨機生成的程序,與通用型 CPU 的硬件特性進行高度匹配,這便意味著要想提高 RandomX 哈希速度的唯一方法就是開發出更快的通用 CPU。這也許在理論上會是促進更快 CPU 的開發動機,但實際上相對於已有的提升 CPU 速度的動機,這點激勵帶來的影響幾乎可以忽略不計。
可驗證延遲函數 VDF
可驗證的延遲函數(Verifiable Delay Function VDF)就像一個具有可驗證性的加密數字時鐘,它允許對事件之間的時間流逝進行計算驗證。VDF 需要執行指定數量且按順序非並行的哈希計算來產生一個獨特又能高效驗證的輸出。Arweave 協議使用了一種叫鏈式哈希(Hash Chain)的技術來生成 VDF,其遞歸定義為:
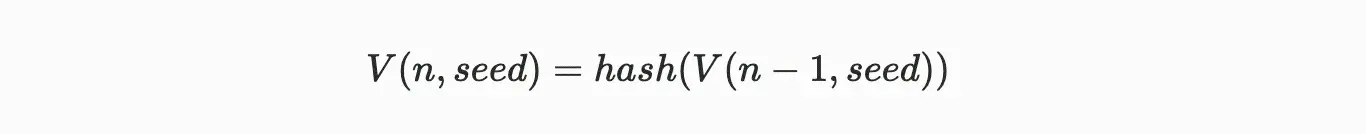
公式註解:第 n 個 VDF 哈希是對其前一個 VDF 哈希的再哈希處理
對於 n = 1 時:

公式註解:如果 n=1,也就是第一個 VDF 哈希是對種子的哈希計算
Arweave VDF 使用的哈希函數是 SHA2-256。通過這種結構,如果市面上最快的 CPU 處理器每秒能連續計算 k 個 SHA2-256 哈希值,那麼對一個種子(seed)進行 V(k,seed) 計算就至少需要 1 秒時間。這是一個連續哈希的過程,如上述公式所示,當 n=1 時,對 Seed 進行哈希計算,當 n=2 時,V(2,seed)是對 V(1,seed)的哈希計算,以此類推。一個正確生成的 V(k,seed),稱為檢查點(Checkpoint),意味著證明者接收種子和生成這個檢查點之間至少經過了 1 秒時間。
如果 VDF 結構需要 O(n) 時間來完成 n 步的計算,那驗證者可以使用 p 個並行線程在 O(n/p) 時間內完成對 VDF 輸出的驗證。這裡需要注意的是,VDF 的生成不準使用並行線程計算,但驗證可以,這能夠讓驗證過程變得更加快速且高效。我們之所以使用鏈式哈希 VDF,是因為它簡單的結構,以及完全依賴於哈希函數的穩健性的特性。






