
Web3 + AI :主権AIを構築し、Cryptoコミュニティの利益と要求に応える

 ほとんどのWeb3 + AIプロジェクトは、ブロックチェーン技術を利用してAI業界のインフラプロジェクトの構築問題を解決することに焦点を当てており、ごく少数のプロジェクトはAIを利用してWeb3アプリケーションの特定の問題を解決しています。
ほとんどのWeb3 + AIプロジェクトは、ブロックチェーン技術を利用してAI業界のインフラプロジェクトの構築問題を解決することに焦点を当てており、ごく少数のプロジェクトはAIを利用してWeb3アプリケーションの特定の問題を解決しています。著者: IOBC Capital
黄仁勋がドバイのWGSで講演した際、「主権AI」という言葉を提唱しました。では、どの主権のAIがCryptoコミュニティの利益と要求に応えることができるのでしょうか?
おそらく、Web3 + AIの形で構築する必要があります。Vitalikは「Crypto + AIアプリケーションの約束と課題」という記事で、AIとCryptoの相乗効果について語りました:Cryptoの非中央集権はAIの中央集権をバランスさせることができ、AIは不透明であり、Cryptoは透明性をもたらします;AIはデータを必要とし、ブロックチェーンはデータの保存と追跡に有利です。この相乗効果は、Web3 + AIの全体的な産業の景観に貫かれています。
ほとんどのWeb3 + AIプロジェクトは、ブロックチェーン技術を利用してAI業界のインフラプロジェクトの構築問題を解決していますが、一部のプロジェクトはAIを利用してWeb3アプリケーションの特定の問題を解決しています。 Web3 + AIの産業の景観は大体以下の通りです:
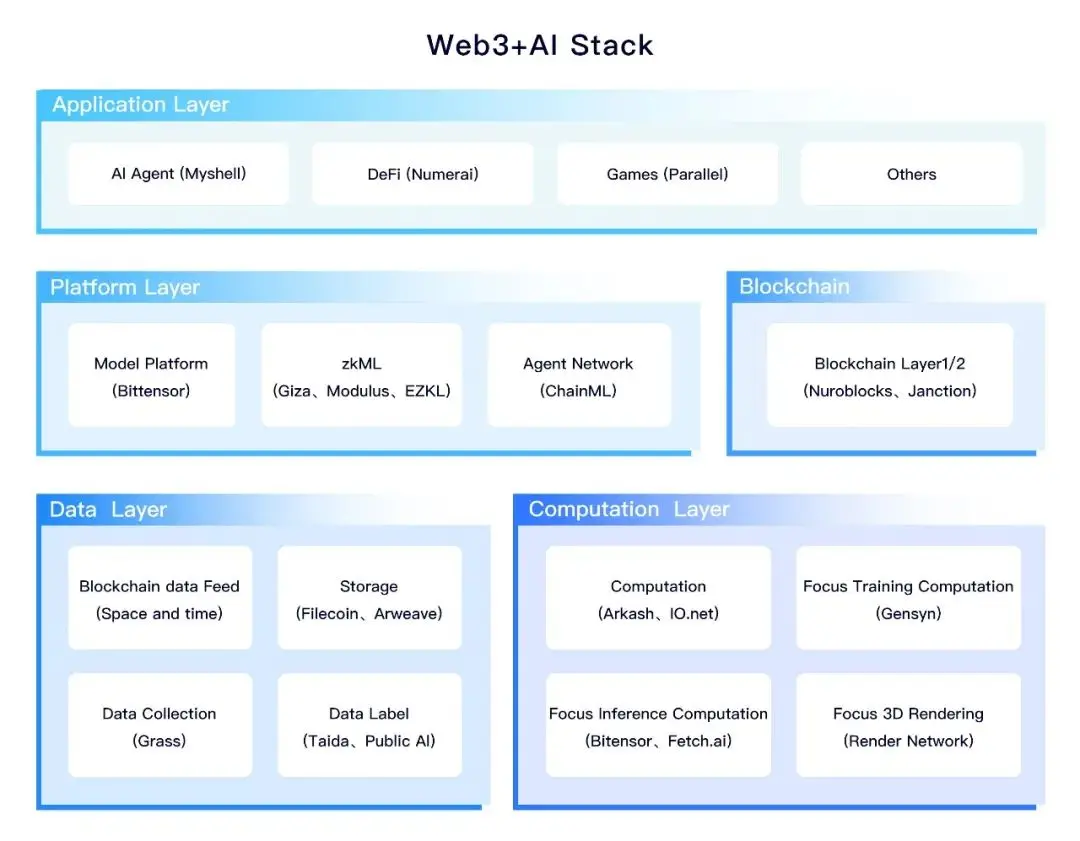 AIの生産と作業フローは大体以下の通りです:
AIの生産と作業フローは大体以下の通りです:
 これらのプロセスにおいて、Web3とAIの結合は主に4つの側面に現れます:
これらのプロセスにおいて、Web3とAIの結合は主に4つの側面に現れます:
1、計算力層:計算力の資産化
ここ2年間、AIの大規模モデルを訓練するための計算力は指数関数的に増加しており、基本的に毎四半期ごとに倍増し、ムーアの法則をはるかに超える速度で急成長しています。この状況は、AI計算力の供給と需要の長期的な不均衡を引き起こし、GPUなどのハードウェアの価格が急速に上昇し、計算力コストを押し上げています。
しかし同時に、市場には多くの中低端の計算力ハードウェアが遊休状態にあります。この中低端ハードウェアの単体計算力は高性能の要求を満たすことができないかもしれません。しかし、Web3の方法で分散型計算ネットワークを構築し、計算力のレンタルや共有の方法を通じて、非中央集権の計算リソースネットワークを構築すれば、多くのAIアプリケーションの要求を満たすことができます。分散型の遊休計算力を利用することで、AI計算力のコストを大幅に削減できます。
計算力層の細分化には以下が含まれます:
- 一般的な非中央集権計算力(例:Arkash、Io.netなど);
- AI訓練用の非中央集権計算力(例:Gensyn、Flock.ioなど);
- AI推論用の非中央集権計算力(例:Fetch.ai、Hyperbolicなど);
- 3Dレンダリング用の非中央集権計算力(例:The Render Networkなど)。
Web3 + AIの計算力の資産化の核心的な利点は、非中央集権計算力のプロジェクトがトークンインセンティブと結びつくことでネットワーク規模を容易に拡大でき、計算リソースコストが低く、高コストパフォーマンスを持ち、一部の中低端の計算力の要求を満たすことができる点です。
2、データ層:データの資産化
データはAIの石油であり、血液です。Web3に依存しなければ、一般的には巨大企業の手の中にしか大量のユーザーデータは存在せず、普通のスタートアップ企業が広範なデータを取得するのは難しいです。ユーザーデータのAI業界における価値もユーザーに還元されていません。Web3 + AIを通じて、データ収集、データラベリング、データの分散ストレージなどのプロセスをより低コストで、より透明で、よりユーザーに有利にすることができます。
高品質のデータを収集することはAIモデル訓練の前提条件です。Web3の方法を利用することで、分散型ネットワークを活用し、適切なトークンインセンティブメカニズムを組み合わせ、クラウドソーシングによる収集方法を採用することで、低コストで高品質かつ広範なデータを取得できます。
プロジェクトの用途に応じて、データ関連のプロジェクトは主に以下の種類に分類されます:
- データ収集プロジェクト(例:Grassなど);
- データ取引プロジェクト(例:Ocean Protocolなど);
- データラベリングプロジェクト(例:Taida、Alayaなど);
- ブロックチェーンデータソースプロジェクト(例:Spice AI、Space and timeなど);
- 非中央集権ストレージプロジェクト(例:Filecoin、Arweaveなど)。
データ関連のWeb3 + AIプロジェクトは、トークン経済モデルの設計過程でより挑戦的です。なぜなら、データは計算力よりも標準化が難しいからです。
3、プラットフォーム層:プラットフォーム価値の資産化
プラットフォーム関連のプロジェクトはほとんどがHugging Faceを基準にしており、AI業界のさまざまなリソースを統合することを核心としています。プラットフォームを構築し、データ、計算力、モデル、AI開発者、ブロックチェーンなどのさまざまなリソースと役割をリンクさせ、プラットフォームを中心にしてさまざまな要求をより便利に解決します。例えばGizaは、包括的なzkML運営プラットフォームの構築に注力しており、機械学習の推論を信頼できる透明なものにすることを目指しています。データとモデルのブラックボックスは現在のAIにおいて一般的な問題であり、Web3の方法でZK、FHEなどの暗号技術を用いてモデルの推論が正しく実行されていることを検証することは、業界内で早晩求められるでしょう。
Focus AIのlayer1/layer2を構築しているプロジェクトもあります。例えばNuroblocks、Janctionなどです。核心的なストーリーは、さまざまな計算力、データ、モデル、AI開発者、ノードなどのリソースを接続し、汎用コンポーネントや汎用SDKをパッケージ化することで、Web3 + AI関連のアプリケーションが迅速に構築・発展できるように支援することです。
また、Agent Network関連のプラットフォームもあり、このようなプラットフォームを基にさまざまなアプリケーションシーンのためにAIエージェントを構築できます。例えばOlas、ChainMLなどです。
プラットフォーム関連のWeb3 + AIプロジェクトは、主にトークンを通じてプラットフォームの価値を捕捉する方法で、プラットフォームの各参加者を共に構築することを奨励します。スタートアッププロジェクトが0から1のプロセスを進める際に特に役立ち、プロジェクト側が計算力、データ、AI開発者コミュニティ、ノードなどの協力者を探す難易度を減少させることができます。
4、アプリケーション層:AIの価値の資産化
前述のインフラ関連のプロジェクトは、ほとんどがブロックチェーン技術を利用してAI業界のインフラプロジェクトの構築問題を解決しています。アプリケーション層のプロジェクトは、より多くAIを利用してWeb3アプリケーションの存在する問題を解決しています。
例えばVitalikは記事の中で2つの方向性を挙げており、私はそれが非常に意義深いと感じています。
1つ目は、AIがWeb3の参加者として機能することです。例えば:Web3ゲームでは、AIはゲームプレイヤーとして機能し、ゲームのルールを迅速に理解し、最も効率的にゲームタスクを完了できます;DEXでは、AIはアービトラージ取引で何年も役立っています;予測市場では、AIエージェントは大量のデータ、知識ベース、情報を広く受け入れ、モデルの分析予測能力を訓練し、製品化してユーザーに提供し、特定のイベント(例えばスポーツイベント、大統領選挙など)に対する予測をモデル推論の方法で行うことができます。
2つ目は、拡張可能な非中央集権のプライベートAIを作成することです。多くのユーザーはAIのブラックボックス問題を心配し、システムに偏見が存在することを懸念しています;また、特定のdAppsがAI技術を通じてユーザーを欺いて利益を得ることを心配しています。本質的には、ユーザーがAIのモデル訓練と推論プロセスに対する審査権とガバナンス権を持っていないからです。しかし、Web3のAIを作成すれば、Web3プロジェクトのようにコミュニティがこのAIに対して分散型のガバナンス権を持つことになり、受け入れられやすくなるかもしれません。
現在のところ、Web3 + AIのアプリケーション層には、非常に高い天井を持つホワイトホースプロジェクトはまだ現れていません。
まとめ
Web3 + AIはまだ初期段階であり、業界内でこの分野の発展の見通しについては意見が分かれています。私たちはこの分野に引き続き注目していきます。Web3とAIの結合が、中央集権的なAIよりも価値のある製品を生み出すことを期待しています。AIが「巨大企業の支配」や「独占」といったラベルから解放され、よりコミュニティ的な方法で「AIを共治」できることを願っています。もしかしたら、より近い距離で参加し、ガバナンスする過程で、人類はAIに対して「畏敬」の念を持ち、「恐怖」を少なくすることができるかもしれません。







