
Alaya AI:Web3のゲーム化デザインを通じてAIデータのアノテーション効率を向上させる方法は?

 将来的には、Alaya AIはDePINとさらに統合され、Rabbit R1のような統合型AIスマートハードウェア製品に組み込まれ、ユーザーの日常的なインタラクションからデータを取得し、デバイスの余剰計算能力を活用することが期待されています。
将来的には、Alaya AIはDePINとさらに統合され、Rabbit R1のような統合型AIスマートハードウェア製品に組み込まれ、ユーザーの日常的なインタラクションからデータを取得し、デバイスの余剰計算能力を活用することが期待されています。著者:Alaya AI
プロジェクト概要
Alaya AIは、ブロックチェーン技術、ゼロ知識証明、共有経済モデル、そして先進的なAIデータラベリングおよび整理技術を活用してAI業界の発展を促進することを目的とした革新的なAIデータラベリングプラットフォームです。このプロジェクトは、ユーザーがデータを提供することで報酬を得ることを可能にし、ブロックチェーンとZK技術を利用してユーザーのプライバシーとデータ所有権を保護します。
Alaya AIは、ユーザーが問題に回答することでデータを収集し、内蔵されたAIシステムを使用してユーザーの貢献の正確性を判断し、それに応じてToken報酬を与えます。ユーザーのNFTレベルが上がるにつれて、問題の難易度も徐々に上昇し、常識から専門分野にわたるさまざまな問題をカバーします。最終的に、Alaya AIは収集したデータを標準化処理し、さまざまなAIモデルが認識および訓練できるようにします。

トラック分析
伝統的な経済学では、労働力、土地、資本が主要な生産要素とされていますが、人工知能の時代においては、アルゴリズム、データ、計算能力が生産の三要素となる可能性があります。現在の大規模言語モデルの探求において、アルゴリズムは依然としてTransformerに基づいて微調整が行われており、計算能力は継続的に積み上げられていますが、高品質なデータこそがモデルとアルゴリズムの突破の鍵となる指標です。各社がそれぞれのAI大モデルの訓練を開始する中で、データの需要は急増しています。

伝統的な世界では、データラベリングビジネスは千億ドルの市場価値を支えており、著名な企業にはScale AI、Appen、海天瑞声、云测数据などがあります。しかし、従来のデータラベリングビジネスは、世界中のユーザーにうまくアクセスできず、地域間の不平等を悪化させています。報告によれば、OpenAIが使用しているケニアのアウトソーシングデータラベラーの時給は1.5ドル未満で、1日に約20万単語をラベリングしています。
Web3では、ブロックチェーン技術を利用してデータの所有権がデータ提供者に帰属することができます。分散型のデータストレージと取引メカニズムにより、個人は自分のデータ資産をより良く管理し、必要に応じて取引や権限を与えることで、相応のインセンティブと報酬を得ることができます。このモデルは、データラベラーの権利をより良く保護します。ブロックチェーンの改ざん不可能で追跡可能な特性に基づき、Web3データサービスはより高い透明性と信頼性を提供できます。すべてのデータ取引、ラベリングタスクの割り当てと完了状況はチェーン上に記録され、誰でも検証できるため、偽造や悪用の可能性が減少します。データ使用者は、追加の信頼の裏付けなしにチェーン上のデータのみを信頼できます。
製品設計
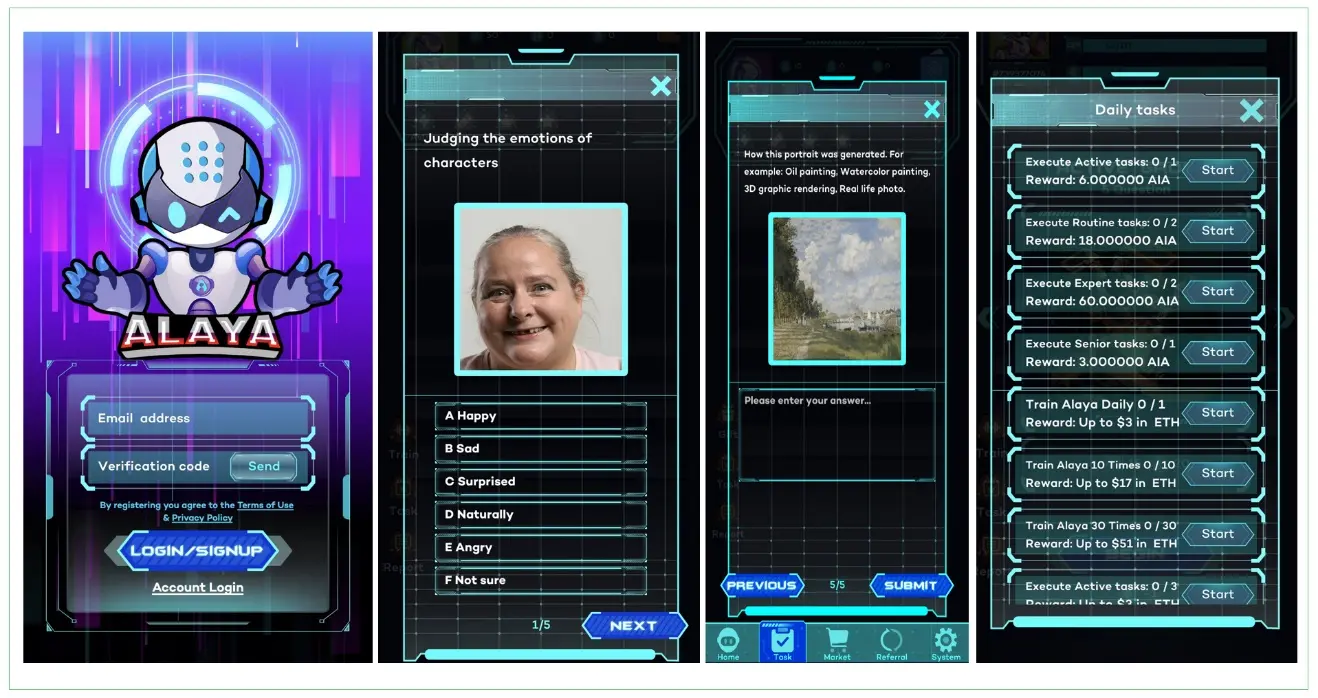
ユーザーの参加のハードルを下げるために、Alaya AIはゲーム化された製品を設計し、ユーザーが製品内で問題に回答することでデータを収集し、暗号学的アルゴリズムを使用してユーザーのプライバシーが漏洩しないように保護します。
For AI, By AI。強化学習の考え方に似て、Alaya AI製品にはデータの質を識別するためのAIが内蔵されており、ユーザーのAIデータ判断の正確性と貢献度を判断し、それに基づいてインセンティブを付与します。さらに、Alaya AIは評判メカニズムと品質検証ノードを導入し、ラベリング結果を分散型で検証します。品質検証ノードによるランダムサンプリングと交差検証を通じて、エラーや悪意のあるラベリングをより効率的に識別し、ラベリング結果の高品質を維持します。タスクの割り当てにおいて、Alaya AIはAIアルゴリズムを活用したタスク割り当て方法を使用し、タスクとユーザーを効率的にマッチングします。ユーザーが提供する高品質なデータが多ければ多いほど、保有するNFTレベルが高くなり、問題の難易度も上がります。一般的な常識問題から、特定の分野(運転、ゲーム、映画など)の細分化された問題、そして進化した分野の問題(医療、技術、アルゴリズムなど)へと進みます。
実現可能性分析
従来のデータラベリング会社は従業員を搾取している疑いがありますが、これは会社の利益に大きく寄与しています。Web3のデータラベリングは、より平等な方法で人間の福祉を向上させることができますが、経済的に見てプラットフォームの収益を減少させる可能性はあるのでしょうか?実際、Alaya AIは多様性を増やすことで全体的な効用を高めています。
従来のデータラベリング方法は、個々の作業量の要求が高く、サンプルの質も保証しにくいです。ラベリング報酬がわずかであるため、プラットフォームは主に発展途上地域のユーザーを募集することができ、これらの地域は一般的に教育水準が低く、ユーザーが提出するサンプルの多様性が欠けています。専門知識を必要とする高階AIモデルに対して、プラットフォームは適切なラベリング担当者を募集するのが難しいです。
トークン/NFT報酬や招待リベートなどの方法を利用して、Alayaは一般的なデータラベリングにソーシャルおよびゲーム要素を融合させ、コミュニティの規模を効果的に拡大し、日々のサインインなどの方法で保持率を向上させています。個々のユーザーがタスクを通じて得られる報酬の額を制御しつつ、Alayaのバイラル推薦システムは、質の高いユーザーの収益がソーシャルネットワークの規模の拡大に伴って無限に増加することを可能にします。
本質的に、Web2時代の中央集権的データプラットフォームは少数のユーザーが大量のサンプルを継続的に提供することに高度に依存していましたが、Alayaは個々のユーザーが提供するデータの量を減らし、参加ユーザーの数を増やしました。個々のユーザーの作業量が少ない前提のもとで、データの質が明らかに向上し、データの代表性が著しく強化されます。接触するユーザーの数が増えることで、サンプリングバイアスを排除した分散型データラベリングプラットフォームが収集するデータは、人類全体の集団知性をよりよく代表することができます。
特定のユーザーが問題領域に不慣れであったり、悪意を持って誤った回答を提出することがデータの質に影響を与えないようにするために、Alaya AIプラットフォームは正規分布モデルを採用してデータを検証し、極端な値を自動的に除外または標準化します。さらに、Alayaは自社開発の最適化アルゴリズムを活用し、ユーザーの回答と重みの交差参照を通じて検証を実現し、手動でのチェック修正を不要にし、データコストをさらに削減します。この際、データの有効性の閾値は各タスクのサンプル量に応じて動的に調整され、過度な修正を避け、データによる歪みを最小限に抑えます。
技術的特徴
Alaya AIはデータ生産者(個人ユーザー)とデータ消費者(AIモデル)の間の中間層として、ユーザーがラベリングしたデータを収集し、処理した後にAIモデルに提供します。
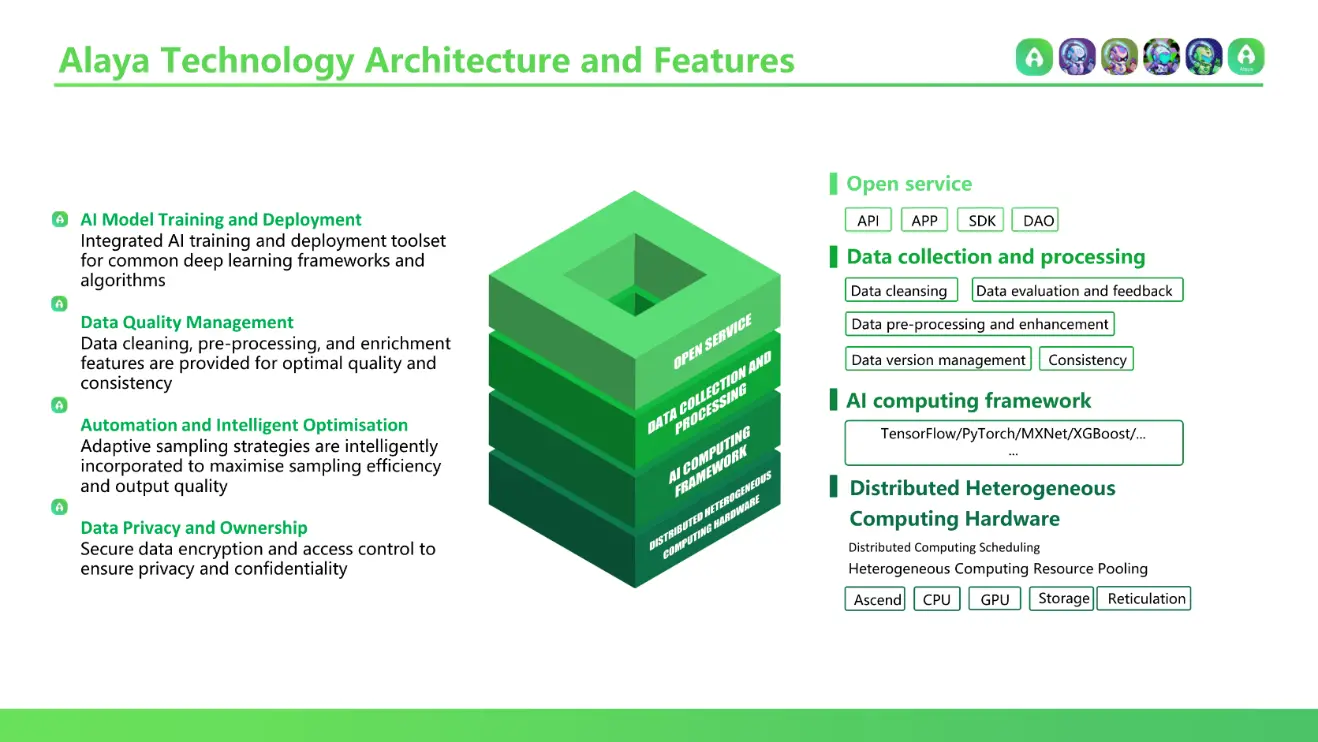
Alaya AIは革新的なマイクロデータモデル(Tiny Data)を採用し、従来のビッグデータに基づいて最適化と反復を行い、深層学習の訓練効果を複数の側面から向上させています:
- データ品質の最適化
マイクロデータモデルは高品質の小規模データセットに焦点を当て、データクリーニングやラベリングの最適化などの手段を通じて、データの正確性と一貫性を向上させます。高品質の訓練データはモデルの一般化能力とロバスト性を効果的に向上させ、ノイズデータがモデルの性能に与える負の影響を減少させます。 - データ特徴の濃縮
マイクロデータモデルは特徴エンジニアリングとデータ濃縮技術を採用し、データの重要な特徴を抽出し、冗長および無関係な情報を除去します。濃縮されたデータセットはより高密度の有効情報を含み、モデルの収束速度を加速し、計算リソースの消費を削減します。 - サンプル均衡の最適化
深層学習モデルの性能は、データ分布の不均衡の影響を受けることがよくあります。マイクロデータモデルはインテリジェントなデータサンプリング戦略を採用し、異なるカテゴリのサンプルを均衡化処理し、モデルが各カテゴリに対して十分な訓練データを持つことを保証し、モデルの分類精度を向上させます。 - アクティブラーニング戦略
マイクロデータモデルはアクティブラーニング戦略を導入し、モデルのフィードバックを通じてデータの選択とラベリングプロセスを動的に調整します。アクティブラーニングは、モデルの効果を最大化するサンプルを優先的に選択してラベリングすることで、非効率的な重複作業を避け、データ利用効率を向上させます。 - 増分学習メカニズム
マイクロデータモデルは増分学習をサポートし、既存のモデルに基づいて新しいデータを継続的に追加して訓練を行い、モデル性能の反復最適化を実現します。増分学習により、モデルは継続的に学習し進化し、変化するアプリケーションシーンの要求に適応します。 - 転移学習能力
マイクロデータモデルは転移学習能力を備えており、既に訓練されたモデルを類似の新しいタスクに適用することで、新しいタスクのデータ要求と訓練時間を大幅に削減します。知識の転移と再利用を通じて、マイクロデータモデルは小サンプルシーンで良好な訓練効果を得ることができます。
同時に、Alaya AIはAI訓練とデプロイメントツールを統合し、一般的な深層学習フレームワークをサポートしており、さまざまなAIモデルが直接認識し使用できるようにし、上流モデル訓練の使用コストを削減します。さらに、ゼロ知識証明などの暗号学的アルゴリズムとアクセス制御技術を利用して、Alaya AIはユーザーのプライバシーを完全に保護します。
エコシステム構築
現在、Alaya AIはArbitrumとopBnBの二大メインネットをサポートし、メール登録をサポートしており、モバイルアプリはすでにGoogle Playにログインしています。
B端から見ると、Alaya AIは10社以上のAIテクノロジー企業と安定した協力関係を築いており、協力の数は引き続き増加しています。これにより、Alayaは安定したキャッシュフローを実現し、ユーザーに安定して現金とTokenの報酬を提供できます。
C端から見ると、Alaya AIは現在40万人以上の登録ユーザーを持ち、日々のアクティブユーザーは2万人を超え、毎日のチェーン上の取引数は1500を超えています。さらに、Alayaは分散型の自治コミュニティを構築し、製品の方向性を公開、透明、民主的な方法で決定します。
将来的には、Alaya AIはDePINとさらに統合し、統合されたAIスマートハードウェア製品(例:Rabbit R1)に組み込まれ、ユーザーの日常的なインタラクションからデータを取得し、デバイスの未使用計算能力を利用することが期待されています。さらに、分散型計算プラットフォーム(例:Akash、Golem)との協力を通じて、Alaya AIはAIデータと計算能力の統一市場を構築し、AI開発者がアルゴリズムの最適化に専念できるようにします。データの保存に関しては、Alaya AIは完了したラベリングデータをIPFS、Arweaveなどの分散型ストレージプロトコルに保存し、分散型AIモデル市場(例:Bittensor)との積極的な協力を展開し、分散型データで分散型モデルを訓練します。

トークンインセンティブ
Alaya AIのトークンシステムは主に二つの部分に分かれています。一つはユーザーインセンティブ用、もう一つはエコシステムインセンティブ用です。
第一部分はAIAトークンで、AIAはAlayaの基本プラットフォームインセンティブトークンであり、ユーザーがタスクを完了し、マイルストーンを達成し、製品内の他の活動に参加することでAIAトークンの報酬を得ることができます。AIAトークンはユーザーのNFTのアップグレード、活動参加のハードル、独自の成果の取得にも使用でき、これらはすべてプレイヤーの基本的な産出を増加させることができます。AIAトークンは基本的な産出と消費のシナリオを持ち、両者は相互に促進し合います。
第二部分はAGTトークンで、AGTはAlayaのガバナンストークンで、最大発行量は50億です。AGTはエコシステムの開発、高度なNFTのアップグレード、コミュニティガバナンスへの参加などに使用されます。ユーザーはコミュニティガバナンス、データレビュー、リクエストの発行などに参加するためにAGTを保有する必要があります。
Alaya AIの二重トークンモデルは、経済的インセンティブとガバナンスを分離し、ガバナンストークンの大幅な変動がシステムの経済的インセンティブの安定性に影響を与えるのを避け、システム全体の拡張性を強化し、システムの長期的な健全な発展を促進します。
競合分析
現在の分散型データラベリングプロジェクトの比較リストは以下の通りです:
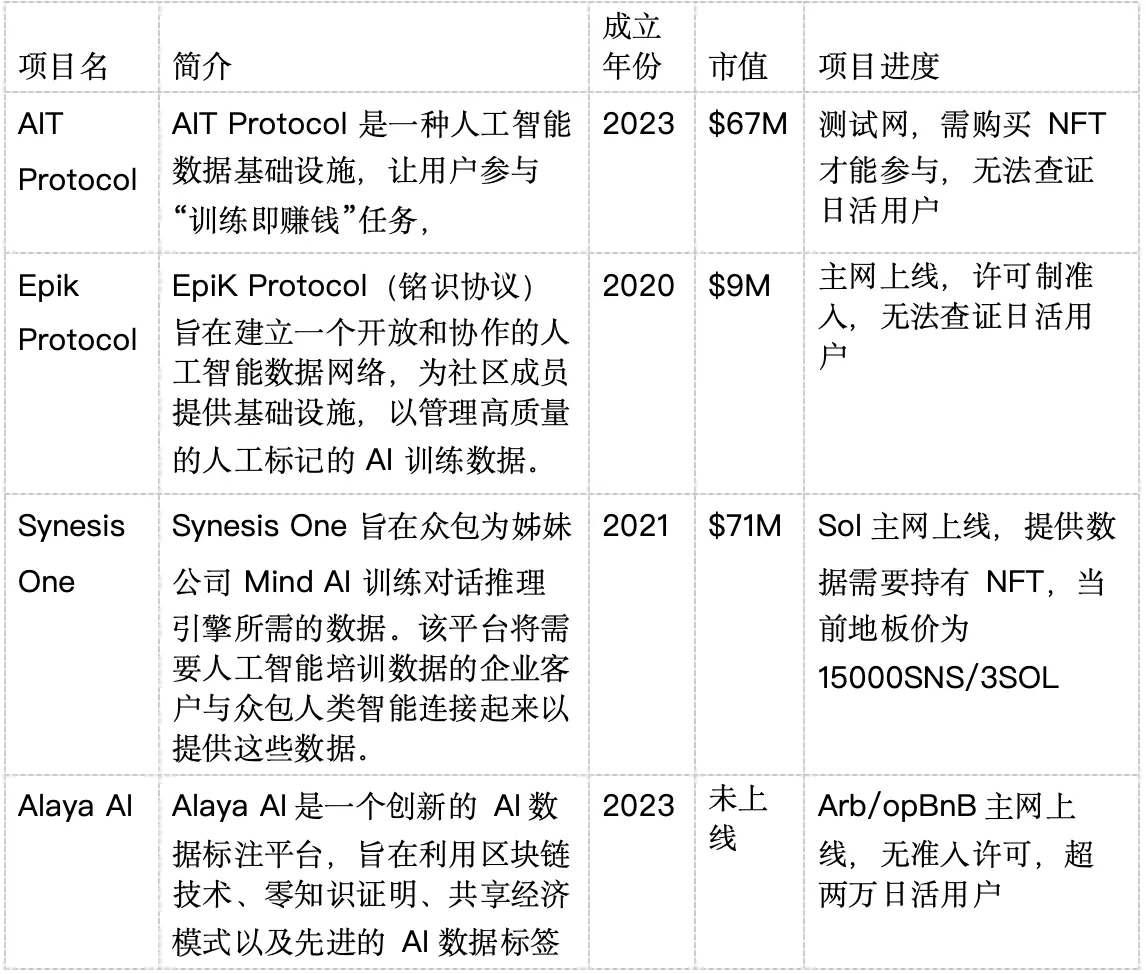

競合分析から見ると、新しいプロジェクトは古いプロジェクトと比較して、トークンのパフォーマンスがより良いです。また、実際のユーザーデータに支えられたプロジェクトは、ユーザーが不足しているプロジェクトよりも明らかに優れています。Alaya AIは40万人以上の登録ユーザー、2万人以上のアクティブユーザー、毎日のチェーン上の取引数が1500を超える新興プロジェクトとして、トークン発行後により良い価値の支えを得る可能性が高いです。
参考
ウェブサイト: https://www.aialaya.io/
Twitter: https://twitter.com/Alaya_AI
Telegram: https://t.me/Alaya_AI
Medium: https://medium.com/@alaya-ai
Deck: https://docsend.com/view/tvrctaq5hyen5max
連絡先: ALAYA AI
メールアドレス:Alaya-AI@aialaya.io
都市:ニュージーランド・オークランド







