AIxDePIN:熱いトレンドの衝突がどのような新しい機会を生み出すのか?

 世界がデジタルトランスフォーメーションの歩みを加速させる中、AIとDePIN(分散型物理インフラ)は、各業界の変革を推進する基盤技術となっています。AIとDePINの融合は、技術の迅速なイテレーションと応用の広がりを促進するだけでなく、より安全で透明かつ効率的なサービスモデルを開くことで、世界経済に深遠な変革をもたらします。
世界がデジタルトランスフォーメーションの歩みを加速させる中、AIとDePIN(分散型物理インフラ)は、各業界の変革を推進する基盤技術となっています。AIとDePINの融合は、技術の迅速なイテレーションと応用の広がりを促進するだけでなく、より安全で透明かつ効率的なサービスモデルを開くことで、世界経済に深遠な変革をもたらします。著者:Cynic、Shigeru
アルゴリズム、計算能力、データの力を利用して、AI技術の進歩はデータ処理とインテリジェントな意思決定の境界を再定義しています。一方で、DePINは中央集権的なインフラから分散型、ブロックチェーンベースのネットワークへのパラダイムシフトを表しています。
世界がデジタルトランスフォーメーションに向けて加速する中、AIとDePIN(分散型物理インフラ)は、あらゆる業界の変革を推進する基盤技術となっています。AIとDePINの融合は、技術の迅速なイテレーションと広範な応用を促進するだけでなく、より安全で透明かつ効率的なサービスモデルを開き、世界経済に深遠な変革をもたらします。
DePIN:分散型で実体経済の中流を支える
DePINは、分散型物理インフラ(Decentralized Physical Infrastructure)の略称です。狭義には、DePINは分散型台帳技術に支えられた伝統的な物理インフラの分散ネットワークを指し、例えば電力ネットワーク、通信ネットワーク、位置情報ネットワークなどがあります。広義には、物理デバイスに支えられたすべての分散ネットワークをDePINと呼ぶことができます。例えば、ストレージネットワークや計算ネットワークなどです。
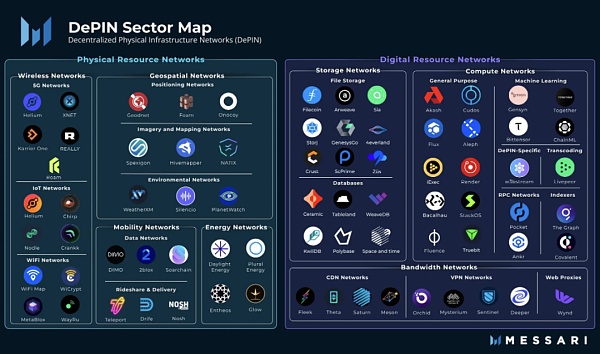
出典: Messari
もしCryptoが金融面で分散型の変革をもたらしたとすれば、DePINは実体経済における分散型の解決策です。PoWマイニングマシンは、DePINの一例と言えます。初日から、DePINはWeb3の核心的な柱でした。
AIの三要素------アルゴリズム、計算能力、データ、DePINはその二つを独占
人工知能の発展は通常、三つの重要な要素に依存していると考えられています:アルゴリズム、計算能力、データ。アルゴリズムはAIシステムを駆動する数学モデルとプログラムロジックを指し、計算能力はこれらのアルゴリズムを実行するために必要な計算リソースを指します。データはAIモデルのトレーニングと最適化の基礎です。

三つの要素の中でどれが最も重要でしょうか?chatGPTが登場する前、人々は通常アルゴリズムが最も重要だと考えていました。さもなければ、学術会議やジャーナル論文はアルゴリズムの微調整で埋め尽くされることはなかったでしょう。しかし、chatGPTとその知能を支える大規模言語モデル(LLM)が登場した後、人々は後の二つの重要性に気づき始めました。膨大な計算能力はモデルが誕生する前提であり、データの質と多様性は堅牢で効率的なAIシステムを構築するために不可欠です。それに対して、アルゴリズムへの要求は以前ほど厳密ではなくなりました。
大規模モデルの時代において、AIは精密な調整から大規模な飛躍へと変わり、計算能力とデータへの需要は日々増加していますが、DePINはちょうどそれを提供することができます。トークンのインセンティブはロングテール市場を活性化し、膨大な消費者向けの計算能力とストレージが大規模モデルに最適な栄養を提供します。
AIの分散化は選択肢ではなく必須
もちろん、誰かが尋ねるでしょう。計算能力とデータはAWSのデータセンターにあり、安定性や使用体験の面でDePINを上回っているのに、なぜDePINを選ぶのか、中央集権的なサービスではなく?
この意見には一理あります。結局のところ、現在のほとんどの大規模モデルは、大手インターネット企業によって直接または間接的に開発されています。chatGPTの背後にはマイクロソフトがあり、Geminiの背後にはグーグルがあります。中国のインターネット大手もほぼ全てが大規模モデルを持っています。なぜでしょうか?それは、大手インターネット企業だけが十分な質の高いデータと強力な財力を持つ計算能力を支えているからです。しかし、これは正しくありません。人々はもはやインターネットの巨人にすべてを操られることを望んでいません。
一方で、中央集権的なAIはデータのプライバシーとセキュリティリスクを抱え、検閲や制御を受ける可能性があります。もう一方で、インターネットの巨人が作り出すAIは、人々の依存をさらに強化し、市場の集中化を引き起こし、革新の障壁を高めます。

出典: https://www.gensyn.ai/
人類はAIの時代のマーチン・ルーサーを必要とするべきではなく、人々は神と直接対話する権利を持つべきです。
ビジネスの観点から見るDePIN:コスト削減と効率向上が鍵
分散型と中央集権の価値観の争いを脇に置いても、ビジネスの観点からDePINをAIに利用することには利点があります。
まず、インターネットの巨人が大量の高性能GPUリソースを持っている一方で、民間に散在する消費者向けGPUの組み合わせも非常に見込みのある計算ネットワークを構成できることを明確に認識する必要があります。これは計算能力のロングテール効果です。この種の消費者向けGPUは、実際には非常に高い稼働率を持っています。DePINが提供するインセンティブが電気代を上回る限り、ユーザーはネットワークに計算能力を提供する動機を持つでしょう。同時に、すべての物理施設はユーザー自身によって管理され、DePINネットワークは中央集権的な供給者が避けられない運営コストを負担する必要がなく、プロトコル設計自体に集中することができます。
データに関しては、DePINネットワークはエッジコンピューティングなどの方法を通じて、潜在的なデータの可用性を解放し、伝送コストを削減できます。また、ほとんどの分散ストレージネットワークは自動重複排除機能を備えており、AIトレーニングデータのクレンジング作業を削減します。
最後に、DePINがもたらすCrypto経済学はシステムのフォールトトレランスを強化し、提供者、消費者、プラットフォームの三者がウィンウィンの状況を実現することが期待されます。
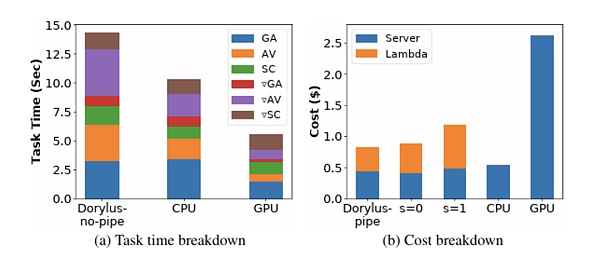
出典: UCLA
あなたが信じないかもしれないので、UCLAの最新の研究によると、同じコストで分散型計算を使用することは、従来のGPUクラスターに比べて2.75倍の性能を実現しました。具体的には、1.22倍速く、4.83倍安価です。
苦難の道:AIとDePINはどのような課題に直面するか?
We choose to go to the moon in this decade and do the other things, not because they are easy, but because they are hard.
------ジョン・F・ケネディ
DePINの分散ストレージと分散計算を利用して信頼なしに人工知能モデルを構築することには、まだ多くの課題があります。
作業検証
本質的に、深層学習モデルの計算とPoWマイニングは一般的な計算であり、最も基本的にはゲート回路間の信号の変化です。マクロ的に見ると、PoWマイニングは「無駄な計算」であり、無数のランダム数生成とハッシュ関数計算を通じて、n個の0を持つハッシュ値を導き出そうとします。一方、深層学習計算は「有用な計算」であり、前向き推論と逆向き推論を通じて深層学習の各層のパラメータ値を計算し、高効率なAIモデルを構築します。
実際には、PoWマイニングのような「無駄な計算」はハッシュ関数を使用しており、原像から像を計算するのは容易ですが、像から原像を計算するのは難しいため、誰でも簡単かつ迅速に計算の有効性を検証できます。一方、深層学習モデルの計算は階層構造を持っており、各層の出力が次の層の入力となるため、計算の有効性を検証するには以前のすべての作業を実行する必要があり、簡単かつ効果的に検証することはできません。
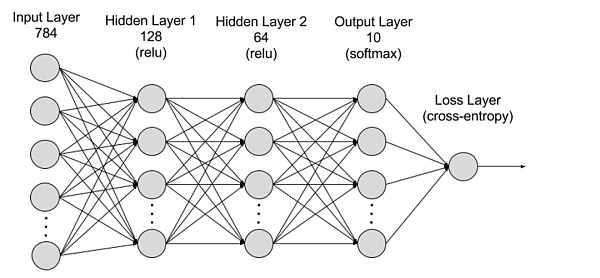
出典: AWS
作業検証は非常に重要です。そうでなければ、計算の提供者は計算を行わず、ランダムに生成された結果を提出することができます。
一つの考え方は、異なるサーバーが同じ計算タスクを実行し、繰り返し実行して同じかどうかを検証することです。しかし、ほとんどのモデル計算は非決定的であり、完全に同じ計算環境でも同じ結果を再現することはできず、統計的な意味で類似性を実現することしかできません。また、繰り返し計算はコストの急激な上昇を引き起こし、これはDePINのコスト削減と効率向上の主要な目標とは一致しません。
別の考え方はOptimisticメカニズムであり、最初は結果が有効な計算であると楽観的に信じ、誰でも計算結果を検証できるようにし、誤りが見つかった場合はFraud Proofを提出できるようにします。プロトコルは詐欺者に対して罰則を科し、通報者に報酬を与えます。
並列化
前述のように、DePINが主に活性化するのはロングテールの消費者向け計算能力市場であり、これは単一のデバイスが提供できる計算能力が限られていることを意味します。大規模AIモデルにとって、単一のデバイスでトレーニングを行う時間は非常に長くなり、並列化の手段を通じてトレーニングに必要な時間を短縮する必要があります。
深層学習トレーニングの並列化の主な難しさは、前後のタスク間の依存性です。この依存関係は並列化を難しくします。
現在、深層学習トレーニングの並列化は主にデータ並列とモデル並列に分かれています。
データ並列は、データを複数のマシンに分散させ、各マシンがモデルの全パラメータを保持し、ローカルデータを使用してトレーニングを行い、最後に各マシンのパラメータを集約します。データ並列はデータ量が非常に大きい場合に効果的ですが、パラメータを集約するために同期通信が必要です。
モデル並列は、モデルのサイズが大きすぎて単一のマシンに収まらない場合、モデルを複数のマシンに分割し、各マシンがモデルの一部のパラメータを保持します。前向きと逆向きの伝播時には異なるマシン間で通信が必要です。モデル並列はモデルが非常に大きい場合に有利ですが、前後の伝播時の通信コストが大きくなります。
異なる層間の勾配情報については、同期更新と非同期更新に分けることができます。同期更新はシンプルで直接的ですが、待機時間が増加します。非同期更新アルゴリズムは待機時間が短いですが、安定性の問題を引き起こす可能性があります。
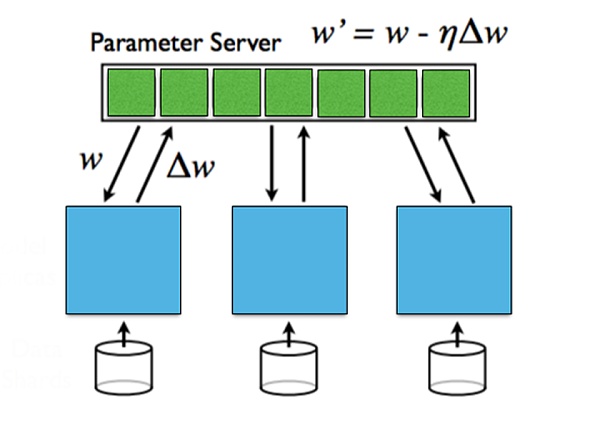
出典: スタンフォード大学、並列および分散深層学習
プライバシー
世界中で個人のプライバシー保護の潮流が高まっており、各国政府は個人データのプライバシーとセキュリティの保護を強化しています。AIは公開データセットを大量に使用していますが、実際に異なるAIモデルを区別するのは各企業の専有ユーザーデータです。
トレーニングプロセスで専有データの利点を得る一方で、プライバシーを露呈しない方法は?構築したAIモデルのパラメータが漏洩しないことをどう保証するか?
これはプライバシーの二つの側面、データプライバシーとモデルプライバシーです。データプライバシーはユーザーを保護し、モデルプライバシーはモデルを構築する組織を保護します。現在の状況では、データプライバシーはモデルプライバシーよりもはるかに重要です。
さまざまなソリューションがプライバシーの問題を解決しようとしています。フェデレーテッドラーニングは、データのソースでトレーニングを行い、データをローカルに留め、モデルパラメータを転送することでデータプライバシーを保護します。一方、ゼロ知識証明は新たな注目を集める可能性があります。
ケーススタディ:市場にはどのような優れたプロジェクトがあるか?
Gensyn
GensynはAIモデルのトレーニングに使用される分散計算ネットワークです。このネットワークは、Polkadotに基づくレイヤー1ブロックチェーンを使用して深層学習タスクが正しく実行されたかを検証し、コマンドを通じて支払いをトリガーします。2020年に設立され、2023年6月には4300万ドルのAラウンド資金調達を発表し、a16zがリードしました。
Gensynは、実行された作業の証明を構築するために、勾配に基づく最適化プロセスのメタデータを使用し、多層的でグラフィックに基づく正確なプロトコルとクロス評価者が一貫して実行し、検証作業を再実行して一貫性を比較し、最終的にはチェーン自体が確認することで計算の有効性を保証します。作業検証の信頼性をさらに強化するために、Gensynはステーキングを導入してインセンティブを創出します。
システムには四種類の参加者がいます:提出者、解決者、検証者、通報者。
• 提出者はシステムのエンドユーザーで、計算するタスクを提供し、完了した作業単位に対して支払います。
• 解決者はシステムの主要な作業者で、モデルのトレーニングを実行し、検証者が確認できる証明を生成します。
• 検証者は非決定的なトレーニングプロセスと決定的な線形計算を結びつける重要な役割を果たし、部分的な解決者の証明を複製し、距離を期待される閾値と比較します。
• 通報者は最後の防衛線で、検証者の作業をチェックし、挑戦を提起します。挑戦が通過すると報酬を得ます。
解決者はステーキングを行う必要があり、通報者は解決者の作業を検証し、悪事を発見した場合は挑戦を行い、挑戦が通過すると解決者のステーキングされたトークンが没収され、通報者が報酬を得ます。
Gensynの予測によれば、このソリューションはトレーニングコストを中央集権的な供給者の1/5に削減することが期待されています。
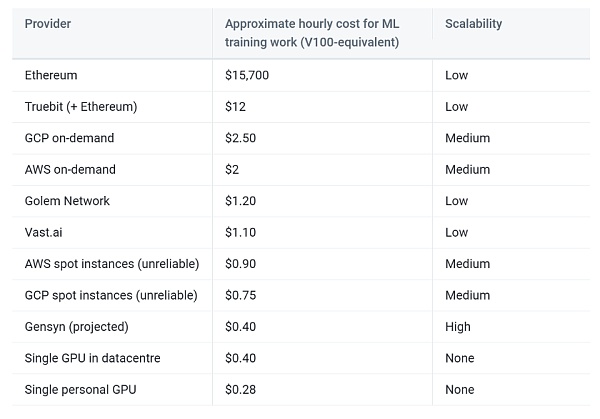
出典: Gensyn
FedML
FedMLは、どこでも任意の規模で分散型および協調型AIを実現するための分散型協力機械学習プラットフォームです。より具体的には、FedMLはMLOpsエコシステムを提供し、機械学習モデルをトレーニング、デプロイ、監視、継続的に改善しながら、プライバシーを保護する方法でデータ、モデル、計算リソースを組み合わせて協力します。2022年に設立され、FedMLは2023年3月に600万ドルのシードラウンド資金調達を発表しました。
FedMLは、FedML-APIとFedML-coreの二つの主要なコンポーネントで構成されており、それぞれ高レベルAPIと低レベルAPIを表しています。
FedML-coreは、分散通信とモデルトレーニングの二つの独立したモジュールを含んでいます。通信モジュールは異なる作業者/クライアント間の低レベル通信を担当し、MPIに基づいています。モデルトレーニングモジュールはPyTorchに基づいています。
FedML-APIはFedML-coreの上に構築されています。FedML-coreを利用することで、クライアント指向のプログラミングインターフェースを採用して新しい分散アルゴリズムを簡単に実装できます。
FedMLチームの最新の研究では、FedML Nexus AIを使用して消費者向けGPU RTX 4090上でAIモデルの推論を行うと、A100よりも20倍安価で、1.88倍速いことが証明されました。
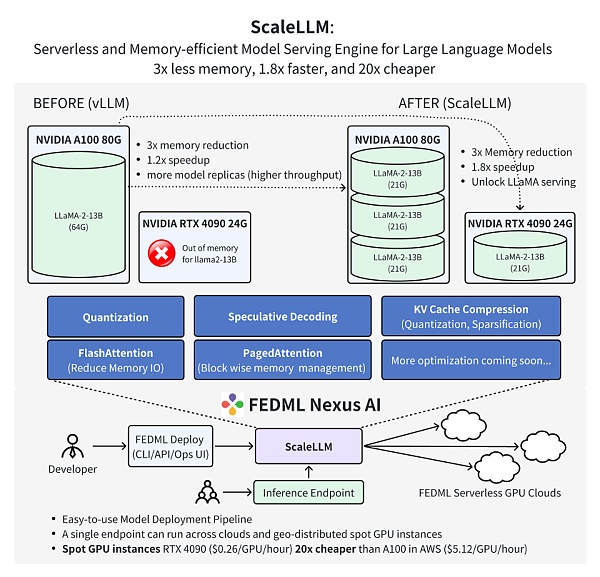
出典: FedML
未来展望:DePINがAIの民主化をもたらす
いつの日か、AIがAGIにさらに発展し、その時、計算能力は事実上の普遍的通貨となり、DePINはこのプロセスを早めるでしょう。
AIとDePINの融合は新たな技術成長点を開き、人工知能の発展に巨大な機会を提供します。DePINはAIに膨大な分散計算能力とデータを提供し、より大規模なモデルのトレーニングを助け、より強力な知能を実現します。同時に、DePINはAIをよりオープンで安全かつ信頼性の高い方向に発展させ、単一の中央集権的インフラへの依存を減少させます。
未来を展望すると、AIとDePINは不断に協調して発展していくでしょう。分散ネットワークは超大規模モデルのトレーニングに強力な基盤を提供し、これらのモデルはDePINの応用において重要な役割を果たします。プライバシーとセキュリティを保護しながら、AIはDePINネットワークプロトコルとアルゴリズムの最適化を支援します。私たちは、AIとDePINがより効率的で、公平で、信頼できるデジタル世界をもたらすことを期待しています。