
対話 Gensyn 創設者:分散型ネットワークを利用して、未使用の計算資源を最大限に活用し、機械学習を支援する

 ブロックチェーンは、単一の意思決定者や仲裁者を必要とする必要性を打破する方法を提供します。なぜなら、それは大規模なグループ間の合意を実現できるからです。
ブロックチェーンは、単一の意思決定者や仲裁者を必要とする必要性を打破する方法を提供します。なぜなら、それは大規模なグループ間の合意を実現できるからです。動画リンク:《Ben Fielding \& Harry Grieve: Gensyn -- The Deep Learning Compute Protocol》
ホスト: Dr. Friederike Ernst、Epicenter ポッドキャスト
講演者: Ben Fielding \& Harry Grieve、Gensyn共同創設者
整理 \& 編集: Sunny、深潮 TechFlow
ブロックチェーンAI計算プロトコルGensynは、6月12日にa16zが主導する4300万ドルのAラウンド資金調達を完了したことを発表しました。
Gensynの使命は、ユーザーにプライベート計算クラスターを所有するのと同等の計算規模へのアクセスを提供し、重要なことは公平なアクセスを実現し、中央のエンティティによる制御や停止を回避することです。同時に、Gensynは機械学習モデルのトレーニングに特化した分散型計算プロトコルです。
昨年末、Gensynの創設者HarryとBenがEpicenterのポッドキャストで計算リソースの調査を深く掘り下げており、AWS、ローカルインフラ、クラウドインフラを含め、これらのリソースを最適化し、AIアプリケーションの発展を支える方法を理解するための議論が行われています。
また、Gensynの設計理念、目標、市場ポジショニング、設計プロセスで直面したさまざまな制約、仮定、実行戦略についても詳しく議論されています。
ポッドキャストでは、Gensynのオフチェーンネットワークにおける4つの主要な役割が紹介され、Gensynのオンチェーンネットワークの特徴、Gensynトークンとガバナンスの重要性が探求されています。
さらに、BenとHarryは、AIの基本原理と応用についての興味深い情報を共有し、聴衆が人工知能についてより深く理解できるようにしています。

ブロックチェーンを分散型AIインフラの信頼層として
ホストは、BenとHarryに、なぜAIと深層学習の豊富な経験をブロックチェーンと組み合わせることにしたのかを尋ねました。
Benは、彼らの決定は一朝一夕のものではなく、比較的長い時間をかけて行われたものであると述べました。Gensynの目標は、大規模なAIインフラを構築することであり、最大規模のスケーラビリティを実現する方法を研究する中で、信頼のないレイヤーが必要であることに気づきました。
彼らは、集中型の新しいサプライヤーに依存せずに計算能力を統合できる必要がありました。そうしなければ、行政的な拡張の制限に直面することになります。この問題を解決するために、彼らは検証可能な計算の研究を探求し始めましたが、常に信頼できる第三者または仲裁者が計算を確認する必要があることがわかりました。
この制限が彼らをブロックチェーンの方向に導きました。ブロックチェーンは、単一の意思決定者や仲裁者が必要な状況を打破する方法を提供します。なぜなら、それは大規模な集団間での合意を実現できるからです。
Harryも彼の理念を共有し、彼とBenは自由な言論を強く支持し、検閲制度に懸念を抱いています。
彼らがブロックチェーンに移行する前、彼らは連邦学習を研究していました。これは、分散データソース上で複数のモデルをトレーニングし、それらを組み合わせてすべてのデータソースから学習できるメタモデルを作成する深層学習の分野です。彼らは銀行と協力してこの方法を実施しました。しかし、彼らはすぐに、これらのモデルをトレーニングするための計算リソースやプロセッサを取得することがより大きな問題であることに気づきました。
計算リソースを最大限に統合するためには、分散型の調整方法が必要であり、これがブロックチェーンの出番です。
市場計算リソース調査:AWS、ローカルインフラ、クラウドインフラ
Harryは、AIモデルを実行するためのさまざまな計算リソースの選択肢について説明しました。これはモデルの規模によって異なります。
学生はAWSやローカルマシンを使用するかもしれませんし、スタートアップはオンデマンドのAWSや予約されたより安価なオプションを選ぶかもしれません。
しかし、大規模なGPUの需要に対して、AWSはコストとスケーラビリティの制限を受ける可能性があり、通常は内部インフラを構築することを選択します。
研究によると、多くの組織がスケールを拡大しようと努力しており、一部はGPUを購入して自ら管理することを選択しています。全体的に見て、GPUを購入することは長期的にはAWSで運用するよりもコスト効率が良いとされています。
機械学習計算リソースの選択肢には、クラウドコンピューティング、ローカルでのAIモデルの実行、または自分の計算クラスターの構築が含まれます。Gensynの目標は、独自のクラスターを所有するのと同等の計算規模へのアクセスを提供することであり、重要なのは公平なアクセスを実現することで、これが中央のエンティティによって制御されたり停止されたりすることはありません。

表1:現在市場にあるすべての計算リソースの選択肢
Gensynの設計理念、目標、市場ポジショニングについての探討
ホストは、Gensynが以前のブロックチェーン計算プロジェクト、例えばGolem Networkとどのように異なるのかを尋ねました。
Harryは、Gensynの設計理念は主に2つの軸に沿って考慮されていると説明しました:
- プロトコルの精緻さ:Golemのような汎用計算プロトコルとは異なり、Gensynは機械学習モデルのトレーニングに特化した精緻なプロトコルです。
- 検証のスケーラビリティ:初期のプロジェクトは通常、評判や比較的耐障害性の低い複製方法に依存しており、これは機械学習の結果に対して十分な信頼を持っていません。Gensynの目標は、暗号の世界における計算プロトコルの学習経験を活用し、特に機械学習に適用して速度とコストを最適化し、満足のいく検証レベルを確保することです。
Harryは、ネットワークが持つべき特性を考慮する際、機械学習エンジニアや研究者に対して設計される必要があると補足しました。それは検証部分を持つ必要がありますが、重要なのは誰でも参加できるようにし、検閲に対抗し、ハードウェアに対して中立である必要があります。
設計プロセスにおける制約、仮定、実行
Gensynのプラットフォーム設計プロセスにおいて、Benはシステムの制約と仮定に対する重視を強調しました。彼らの目標は、世界全体をAIスーパーコンピュータに変換できるネットワークを創造することであり、そのためには製品の仮定、研究の仮定、技術の仮定の間でバランスを取る必要があります。
なぜGensynを独自の第一層ブロックチェーンとして構築するのかという理由は、合意メカニズムなどの重要な技術分野でより大きな柔軟性と意思決定の自由を保持するためです。彼らは将来的に彼らのプロトコルを証明できることを望んでおり、プロジェクトの初期段階で不必要な制限を課したくありません。さらに、彼らは将来的にさまざまなチェーンが広く受け入れられる情報プロトコルを介して相互作用できると信じており、そのため彼らの決定もこのビジョンに合致しています。
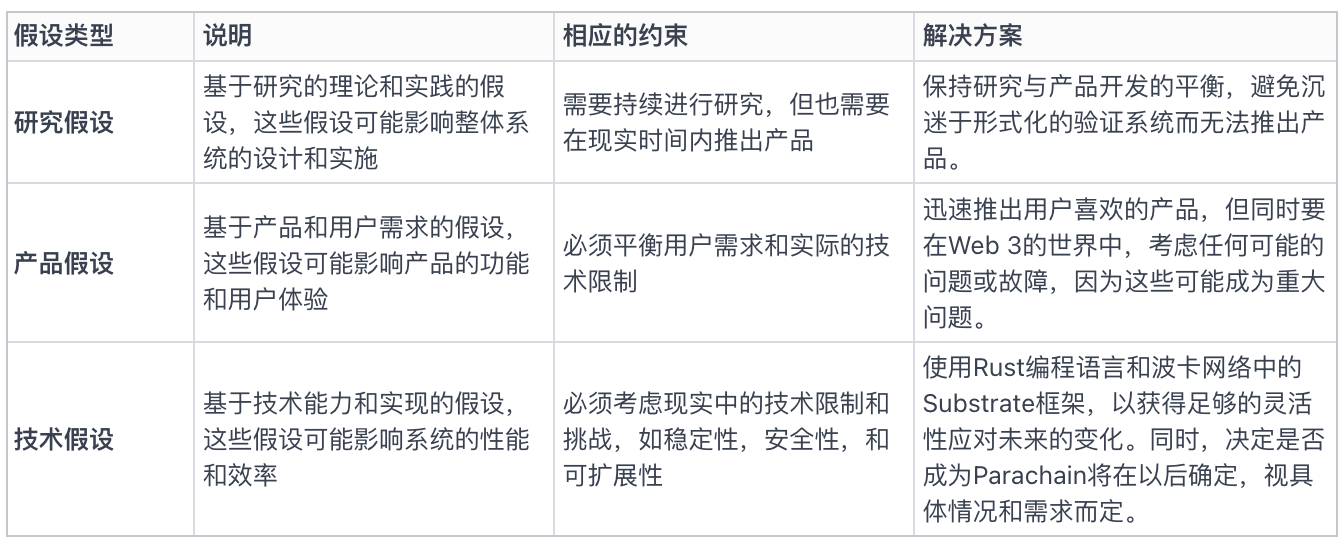
図表2:製品の仮定、研究の仮定、技術の仮定、制約と実行
Gensynオフチェーンネットワークにおける4つの主要な役割
このGensyn経済の議論では、4つの主要な役割が紹介されました:提出者、作業者、検証者、通報者。提出者は、特定の画像を生成したり、自動運転車を運転できるAIモデルを開発したりするなど、Gensynネットワークにさまざまな問題を提出できます。
提出者(Submitter)がタスクを提出
Harryは、Gensynを使用してモデルをトレーニングする方法を説明しました。ユーザーはまず、テキストプロンプトに基づいて画像を生成するなど、期待される結果を定義します。その後、テキストプロンプトを入力として受け取り、対応する画像を生成するモデルを構築します。トレーニングデータは、モデルの学習と改善にとって重要です。モデルアーキテクチャとトレーニングデータが準備できたら、ユーザーはそれらを学習率スケジュールやトレーニングの持続時間などのハイパーパラメータと共にGensynネットワークに提出します。このトレーニングプロセスの結果は、トレーニングされたモデルであり、ユーザーはそのモデルをホストして使用できます。
未トレーニングのモデルをどのように選択するかについて尋ねられたとき、Harryは2つの方法を提案しました。
- 第一の方法は、現在人気のある基礎モデルの概念に基づいており、大企業(OpenAIやMidjourneyなど)が基礎モデルを構築し、ユーザーがその基礎モデルに特定のデータでトレーニングを行うことができます。
- 第二の選択肢は、ゼロからモデルを構築することであり、基礎モデルのアプローチとは異なります。
Gensynでは、開発者は進化的最適化のような方法を使用して、さまざまなアーキテクチャを提出し、トレーニングとテストを行い、期待されるモデルを構築するために継続的に最適化できます。
Benは、彼らの視点から基礎モデルに対する深い見解を提供しました。彼らは、これはこの分野の未来であると考えています。
Gensynはプロトコルとして、進化的最適化技術や類似の方法を使用するDAppsに実装されることを望んでいます。これらのDAppsは、個々のアーキテクチャをGensynプロトコルに提出してトレーニングとテストを行い、反復的に洗練させて理想的なモデルを構築します。
Gensynの目標は、純粋な機械学習計算基盤を提供し、それを中心にエコシステムを開発することを奨励することです。
事前トレーニングされたモデルは、組織が独自のデータセットを使用したり、トレーニングプロセスの情報を隠したりすることでバイアスを引き起こす可能性がありますが、Gensynの解決策はトレーニングプロセスをオープンにすることであり、ブラックボックスを排除したり、完全に決定論に依存したりすることではありません。基礎モデルを集団で設計しトレーニングすることで、特定の企業のデータセットによるバイアスを受けずにグローバルモデルを作成できます。
作業者(Solver)
タスクの割り当てにおいて、1つのタスクは1つのサーバーに対応します。しかし、1つのモデルは複数のタスクに分割される可能性があります。
大規模言語モデルは、設計時にその時点で利用可能な最大のハードウェア容量を十分に活用します。この概念はネットワークに拡張でき、デバイスの異質性を考慮します。
特定のタスクに対して、検証者や作業者はMempoolからタスクを引き受けることができます。タスクを引き受ける意思を示した人々の中から、ランダムに1人の作業者が選ばれます。モデルとデータが特定のデバイスに適応できない場合でも、デバイスの所有者が適応できると主張する場合、システムの混雑により罰金が科せられる可能性があります。
タスクが1台のマシンで実行できるかどうかは、利用可能な作業者のサブセットから作業者を選択することができる検証可能なランダム関数によって決定されます。
作業者の能力を検証する問題について、作業者が主張する計算能力を持っていない場合、計算タスクを完了できず、これは証明を提出する際に検出されます。
しかし、タスクのサイズは問題です。タスクが大きすぎると、サービス拒否攻撃(DoS)などのシステム問題を引き起こす可能性があります。作業者がタスクを完了すると主張するが、永遠に完了しない場合、時間とリソースが無駄になります。
したがって、タスクのサイズの決定は非常に重要であり、並列化やタスク構造の最適化などの要因を考慮する必要があります。研究者たちは、さまざまな制約条件に基づく最適な方法を積極的に研究し探求しています。
テストネットが起動した後、実際の状況も考慮され、システムが現実世界でどのように機能するかが観察されます。
完璧なタスクサイズを定義することは挑戦的であり、Gensynは現実世界からのフィードバックと経験に基づいて調整と改善を行う準備ができています。
オンチェーンでの大規模計算の検証メカニズムとチェックポイント(Checkpoints)
HarryとBenは、計算の正確性を検証することが重要な課題であることを示しました。なぜなら、それはハッシュ関数のように決定論的ではないため、計算が行われたかどうかを単純にハッシュ検証で確認することができないからです。この問題を解決するための理想的な解決策は、計算全体の過程に対するゼロ知識証明の応用を利用することです。現在、Gensynはこの能力の実現に向けて努力しています。
現在、Gensynはチェックポイントを使用したハイブリッドアプローチを導入しており、確率メカニズムとチェックポイントを通じて機械学習計算を検証しています。ランダム監査スキームと勾配空間パスを組み合わせることで、比較的堅牢なチェックを確立できます。さらに、検証プロセスを強化するためにゼロ知識証明が導入され、モデルの全体的な損失に適用されています。
検証者(Verifier)と通報者(Whistleblower)
ホストとHarryは、検証プロセスに関与する2つの追加の役割、検証者(Verifier)と通報者(Whistleblower)について議論しました。彼らはこれら2つの役割の具体的な責任と機能について詳しく説明しました。
検証者の任務はチェックポイントの正確性を確保することであり、通報者の任務は検証者がその職務を正確に果たしていることを確保することです。通報者は検証者のジレンマを解決し、検証者の仕事が正確で信頼できることを保証します。検証者は故意に作業にエラーを導入し、通報者の役割はこれらのエラーを識別し明らかにすることで、検証プロセスの完全性を確保します。
検証者は故意にエラーを導入して通報者の警戒心をテストし、システムの有効性を確保します。作業にエラーがある場合、検証者はエラーを検出し、通報者に通知します。エラーはその後ブロックチェーンに記録され、オンチェーンで検証されます。定期的に、そしてシステムの安全性に関連する速度で、検証者は意図的にエラーを導入して通報者の参加を維持します。通報者が問題を発見した場合、彼らは「ピンポイントプロトコル」と呼ばれるゲームに参加し、計算を神経ネットワークの特定の領域のメルケルツリー内の具体的なポイントに絞り込むことができます。その後、これらの情報は仲裁のためにチェーン上に提出されます。これは検証者と通報者のプロセスの簡略化されたバージョンであり、彼らはシードラウンドの終了後にさらなる開発と研究を行いました。
Gensynオンチェーンネットワーク
BenとHarryは、Gensyn調整プロトコルがオンチェーンでどのように機能し、実装されるかについて詳しく議論しました。彼らはまず、ネットワークブロックの構築プロセスに言及し、ここにはそのステーキングネットワークの一部としてトークンをステーキングすることが含まれます。その後、これらの構成要素がGensynプロトコルとどのように関連しているかを説明しました。
Benは、Gensynプロトコルは主にバニラサブストレートのポルカネットワークプロトコルに基づいていると説明しました。彼らはプルーフオブステークに基づくGrandpa Babe合意メカニズムを採用し、検証者は通常の方法で操作します。しかし、以前に紹介されたすべての機械学習コンポーネントはオフチェーンで行われ、さまざまなオフチェーン参加者がそれぞれのタスクを実行します。
これらの参加者は、ステーキングを通じてインセンティブを得ることができ、Substrate内のステーキングブロックまたはスマートコントラクト内に特定の数のトークンを提出することでステーキングを行います。彼らの作業が最終的に検証されると、報酬を得ることができます。
BenとHarryが言及した課題は、ステーキング額、可能な減少額、報酬額の間のバランスを確保することであり、怠惰または悪意のある行動のインセンティブを防ぐことです。
さらに、通報者を増やすことによる複雑さについても議論しましたが、スケール計算の需要により、彼らの存在は検証者の誠実性を確保するために重要です。彼らは、ゼロ知識証明技術を通じて通報者を排除する可能性を探求し続けています。彼らは、現在のシステムがライトペーパーに記載された内容と一致していると述べましたが、各側面を簡素化するために積極的に努力しています。
ホストがデータ可用性の解決策があるかどうかを尋ねると、Henryは彼らがサブストレートの上に「可用性の証明(POA)」と呼ばれるレイヤーを導入したと説明しました。このレイヤーは、エラー訂正コードなどの技術を利用して、広範なストレージレイヤー市場で直面している制限を解決します。彼らは、すでにこのような解決策を実施している開発者に非常に興味を持っていると述べました。
Benは、彼らのニーズはトレーニングデータのストレージだけでなく、中間証明データにも関連しており、これらのデータは長期的に保存する必要がないと補足しました。たとえば、特定の数のブロックを発行した際には、約20秒間だけ保持する必要があるかもしれません。しかし、現在彼らがArweaveで支払っているストレージ費用は数百年の範囲をカバーしており、これらの短期的なニーズには不必要です。彼らは、Arweaveの保証と機能を持ちながら、より低コストで短期的なストレージニーズを満たすソリューションを探しています。
Gensynトークンとガバナンス
Benは、Gensynトークンがエコシステムにおいて重要な役割を果たしていることを説明しました。これは、ステーキング、罰則、報酬の提供、合意の維持などにおいて重要な役割を果たします。その主な目的は、システムの財務的合理性と完全性を確保することです。Benはまた、検証者に支払うためにインフレ率を慎重に使用し、ゲーム理論メカニズムを利用することに言及しました。
彼は、Gensynトークンの純粋な技術的用途を強調し、Gensynトークンを導入するタイミングと必要性を技術的に確保することを述べました。
Harryは、彼らが深層学習コミュニティの中で少数派であることを示し、特にAI学者が暗号通貨に対して広範な懐疑心を抱いていることを認識しています。それにもかかわらず、彼らは暗号通貨の技術的およびイデオロギー的側面の価値を認識しています。
しかし、ネットワークが立ち上がると、彼らはほとんどの深層学習ユーザーが主に法定通貨を使用して取引を行うと予想しており、トークンへの変換は裏でシームレスに行われると考えています。
供給面では、作業者と提出者が積極的にトークン取引に参加し、彼らは大量のGPUリソースを持ち、新しい機会を求めているEthereumマイナーからの関心をすでに受けています。
ここで重要なのは、深層学習や機械学習の実務者が暗号通貨用語(トークンなど)に対する恐怖を取り除き、ユーザー体験のインターフェースと分離することです。Gensynは、これはWeb 2とWeb 3の世界を結びつけるエキサイティングなユースケースであり、経済的合理性とその存在を支えるために必要な技術を持っていると述べています。

図1:ポッドキャストに基づいて整理されたGensynのオンチェーン・オフチェーンネットワークの運用モデル。運用メカニズムに誤りがある場合は、読者にお知らせください(画像提供:深潮)
AIの基礎知識
AI、深層学習、機械学習
Benは、近年のAI分野の発展についての見解を共有しました。彼は、AIと機械学習の分野は過去7年間にわたり一連の小さなブレイクスルーを経験してきたが、現在の進展は真の影響と価値のあるアプリケーションを生み出しており、これらはより広い聴衆と共鳴するものだと考えています。深層学習はこれらの変化の基本的な原動力です。深層神経ネットワークは、従来のコンピュータビジョン手法が設定したベンチマークを超える能力を示しています。さらに、GPT-3のようなモデルもこの進展を加速させています。
Harryは、AI、機械学習、深層学習の違いについてさらに説明しました。彼は、これら3つの用語がしばしば混同されるが、顕著な違いがあると考えています。彼は、AI、機械学習、深層学習はロシアのマトリョーシカのようなものであり、AIが最外層であると比喩しました。
- 広義には、AIは機械にタスクを実行させるためのプログラミングを指します。
- 機械学習は1990年代と2000年代初頭に普及し、データを利用して意思決定の確率を決定するものであり、if-thenルールを持つ専門家システムに依存しません。
- 深層学習は機械学習の基礎の上に構築されますが、より複雑なモデルを許可します。

図表3:人工知能、機械学習、深層学習の違い
人工狭義知能、人工汎用知能、人工超知能
この部分では、ホストとゲストが人工知能の3つの重要な領域、人工狭義知能(ANI)、人工汎用知能(AGI)、人工超知能(ASI)について深く探討しました。
- 人工狭義知能(Artificial Narrow Intelligence、ANI):現在の人工知能は主にこの段階にあり、機械は特定のタスクを非常に得意としています。例えば、医学的スキャンから特定のタイプの癌を検出するためのパターン認識です。
- 人工汎用知能(Artificial General Intelligence、AGI):AGIは、機械が人間にとって比較的簡単なタスクを実行できることを指しますが、計算システムにおいては非常に挑戦的です。例えば、混雑した環境でスムーズにナビゲートし、周囲のすべての入力に対して離散的な仮説を立てることがAGIの一例です。AGIは、モデルやシステムが人間のように日常的なタスクを実行できることを指します。
- 人工超知能(Artificial Super Intelligence、ASI):AGIに達した後、機械はさらに発展して人工超知能になる可能性があります。これは、機械がそのモデルの複雑性、増加した計算能力、無限の寿命、完璧な記憶により人間の能力を超えることを指します。この概念は、しばしばSFやホラー映画で探求されます。
さらに、ゲストは脳と機械の融合、例えば脳-機械インターフェースを通じてAGIを実現する可能性について言及しましたが、これには一連の倫理的および道徳的な問題も引き起こされます。
深層学習のブラックボックスを解明する:決定論と確率論
Benは、深層学習モデルのブラックボックス性はその絶対的なサイズに起因していると説明しました。あなたは依然としてネットワーク内の一連の意思決定ポイントを通じて経路を追跡しています。ただし、この経路は非常に大きく、モデル内の重みやパラメータを具体的な値と結びつけることが難しいのです。これらの値は数百万のサンプルを入力した後に得られたものです。あなたは確実にこれを行うことができ、各更新を追跡できますが、最終的に生成されるデータの量は非常に大きくなります。
彼は2つのことが起こっていると見ています:
私たちが構築しているモデルに対する理解が深まるにつれて、ブラックボックスの本質は徐々に消失しています。深層学習は研究分野であり、興味深い急速な時期を経て、多くの実験が行われました。これらの実験は研究の基盤によって駆動されているのではなく、むしろ私たちが何を得られるかを見ているのです。したがって、私たちはより多くのデータを投入し、新しいアーキテクチャを試し、何が起こるかを見ているのです。基本原理から出発してこのものを設計し、正確にそれがどのように機能するかを知っているわけではありません。したがって、すべてがブラックボックスであるという刺激的な時期がありました。しかし、彼はこの急成長が鈍化し始めていると考えており、人々がこれらのアーキテクチャを再検討し、「なぜこれがうまくいくのか?もう少し深く掘り下げて証明しよう」と言っているのを見ています。したがって、ある程度、この幕は開かれつつあります。
もう一つの起こっていることは、計算システムが完全に決定論的である必要があるのか、それとも私たちが確率の世界に生きることができるのかという見解の変化です。私たちは人間として確率の世界に生きています。自動運転車の例が最も明確かもしれません。私たちが運転するとき、私たちはランダムな出来事が起こることを受け入れ、小さな事故が起こる可能性があり、自動運転車システムに問題が発生する可能性があることを受け入れています。しかし、私たちはこれを完全には受け入れられず、これは完全に決定論的なプロセスでなければならないと言います。自動運転車業界の課題の一つは、人々が自動運転車に適用される確率メカニズムを受け入れると仮定していることですが、実際には人々は受け入れていないのです。彼はこの状況が変わると考えており、議論の余地があるのは、私たちが社会として確率計算システムが共存することを許可するかどうかです。彼はこの道が順調に進むかどうかは不明ですが、これは起こると考えています。
勾配最適化法:深層学習の核心的な最適化手法
勾配最適化は深層学習の核心的な手法の一つであり、神経ネットワークのトレーニングにおいて重要な役割を果たします。神経ネットワークでは、一連の層のパラメータは実際には実数です。ネットワークのトレーニングは、これらのパラメータをデータを正しく伝達し、ネットワークの最後の段階で期待される出力を引き起こす実際の値に設定することを含みます。
勾配に基づく最適化手法は、神経ネットワークと深層学習の分野において大きな変革をもたらしました。この手法は、ネットワーク内の各層のパラメータに対する誤差の微分である勾配を使用します。連鎖律を適用することで、勾配をネットワーク全体に逆伝播させることができます。このプロセスでは、誤差面上の位置を特定できます。誤差はユークリッド空間内の表面としてモデル化でき、この表面は高低起伏のある領域に見えます。最適化の目標は、誤差を最小化する領域を見つけることです。
勾配は各層に対して、あなたがこの表面上のどの位置にいるか、そしてパラメータを更新すべき方向を示します。あなたはこの起伏のある表面上をナビゲートし、誤差を減少させる方向を見つけることができます。ステップサイズは表面の傾斜の程度によって決まります。傾斜が大きければ、より遠くにジャンプします。傾斜が小さければ、より小さくジャンプします。本質的に、あなたはこの表面上をナビゲートし、凹みを探しているだけであり、勾配は位置と方向を特定するのに役立ちます。
この手法は大きな突破口であり、勾配は明確な信号と有用な方向を提供します。これはパラメータ空間内でランダムにジャンプするのに比べて、あなたが表面のどの位置にいるか、山の頂上にいるのか、谷の中にいるのか、平坦な領域にいるのかをより効果的に導くことができます。
深層学習には最適解を見つけるための多くの技術が存在しますが、現実の状況は通常より複雑です。深層学習のトレーニングで使用される多くの正則化技術は、科学というよりも芸術のようなものにしています。これが、勾配に基づく最適化が現実の応用において、より芸術的であり、正確な科学ではない理由です。

図2:簡単に言えば、最適化の目標は谷底を見つけることです(画像提供:深潮)
まとめ
Gensynの目標は、世界最大の機械学習計算リソースシステムを構築することであり、個人のスマートフォンやコンピュータなど、未使用または十分に使用されていない計算リソースを最大限に活用することです。
機械学習とブロックチェーンの文脈において、台帳に保存される記録は通常計算結果、つまり機械学習を通じて処理されたデータの状態です。この状態は、「このデータは機械学習され、有効で、発生時間はX年X月である」というものです。この記録の主な目的は結果の状態を表現することであり、計算プロセスを詳述することではありません。
このフレームワークにおいて、ブロックチェーンは重要な役割を果たします:
- ブロックチェーンはデータ状態結果を記録する方法を提供します。その設計はデータの真実性を確保し、改ざんや否認を防ぎます。
- ブロックチェーン内部には経済的インセンティブメカニズムがあり、これを通じて計算ネットワーク内の異なる役割の行動を調整できます。例えば、提出者、作業者、検証者、通報者の4つの役割が挙げられます。
- 現在のクラウドコンピューティング市場の調査を通じて、クラウドコンピューティングには全く価値がないわけではなく、さまざまな計算方法には特定の問題があります。ブロックチェーンの分散型計算方法は、いくつかのシナリオで機能する可能性がありますが、従来のクラウドコンピューティングを全面的に置き換えることはできません。つまり、ブロックチェーンは万能の解決策ではありません。
- 最後に、AIは生産力の一種と見なすことができますが、AIを効果的に組織し、トレーニングする方法は生産関係の範疇に属します。これには協力、クラウドソーシング、インセンティブなどの要素が含まれます。この点で、Web 3.0は多くの可能な解決策やシナリオを提供します。
したがって、私たちはブロックチェーンとAIの結合、特にデータとモデルの共有、計算リソースの調整、結果の検証などの面で、AIのトレーニングと使用プロセスにおけるいくつかの問題を解決するための新しい可能性を提供していると理解できます。
引用 1.https://docs.gensyn.ai/litepaper/ 2.https://a16zcrypto.com/posts/announcement/investing-in-gensyn/







