
聖杯の解読:オンチェーン全同態暗号の課題と解決策

 FHEは、私たちが各プラットフォームでデータを保護する方法を根本的に再構築し、プライバシーの新時代への道を切り開きます。
FHEは、私たちが各プラットフォームでデータを保護する方法を根本的に再構築し、プライバシーの新時代への道を切り開きます。撰文:Jeffrey Hu、Arnav Pagidyala
核心观点:
- 全同態暗号(FHE)は「暗号学の聖杯」と称されていますが、現在その応用は性能、開発体験、安全性の制約を受けています。
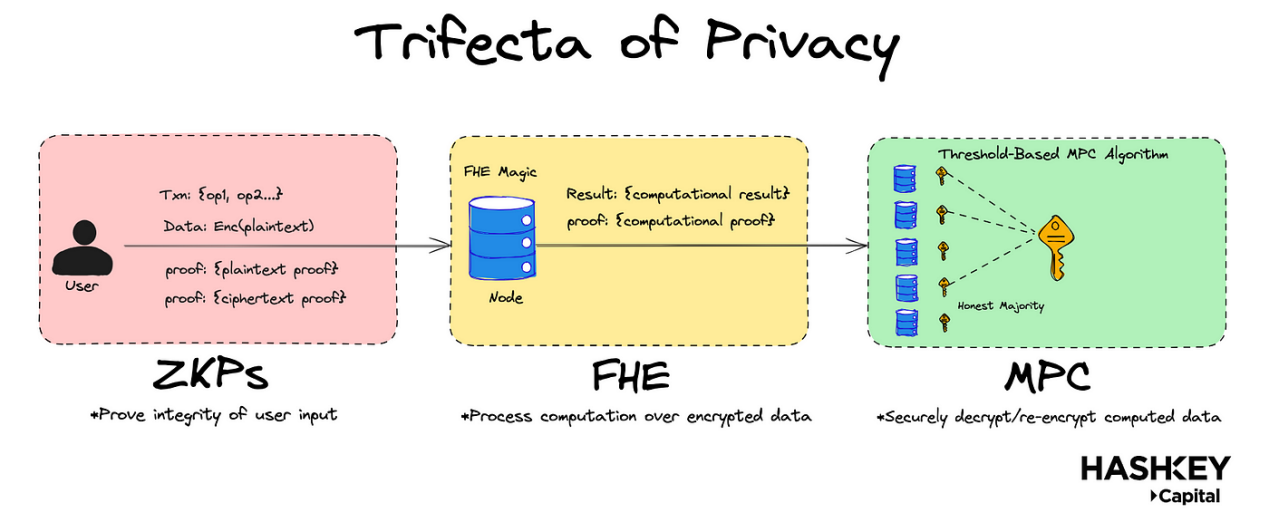
- 上の図に示すように、真に秘密で安全な共有状態システムを構築するためには、FHEをゼロ知識証明(ZKP)や多者計算(MPC)と組み合わせて使用する必要があります。
- FHEは急速に発展しています。新しいコンパイラ、ライブラリ、ハードウェアなどの開発や、Web2企業(インテル、グーグル、DARPAなど)の研究開発がFHEの発展を大いに促進しています。
- FHEおよびその周辺エコシステムの成熟に伴い、「検証可能なFHE」が標準となると予想しています。分散型アプリケーション(DApps)/ロールアップは、計算と検証をFHE協処理器にアウトソーシングすることを選択するかもしれません。
- チェーン上のFHEの基本的な制約は「誰が復号鍵を持つか」です。閾値復号(Threshold decryption)とMPCはこの制約に対する解決策を提供しますが、通常は性能と安全性の間でトレードオフが必要です。
引言:
ブロックチェーンの透明性は両刃の剣です。そのオープン性と可観察性は魅力的ですが、企業がブロックチェーン技術を採用する際の懸念でもあります。
チェーン上のプライバシーは、暗号分野において過去10年間で最も挑戦的な問題の一つです。多くのチームがゼロ知識証明(ZKP)に基づくシステムを構築してチェーン上のプライバシーを実現しようとしていますが、共有された暗号状態をサポートすることはできません。その理由は、これらのソリューションが一連のZKPの関数であるため、現在の状態に任意のロジックを適用することが不可能だからです。つまり、私たちはZKPだけを使って暗号化された共有状態アプリケーション(例えばプライベートなUniswap)を構築することはできません。
しかし、最近の技術的ブレークスルーは、ZKPと全同態暗号(FHE)を組み合わせることで、完全に汎用化された暗号化された分散型金融(DeFi)を実現できることを示しています。これはどのように実現されるのでしょうか?FHEは新興の暗号学の分野であり、暗号化されたデータ上で任意の計算を行うことができます。上の図に示すように、ZKPはユーザーの入力と計算の完全性を証明でき、FHEは計算自体を処理できます。
FHEは「暗号学の聖杯」と称されていますが、私たちはこの分野とそのさまざまな課題および可能な解決策について客観的な分析を提供しようとしています。この技術報告書では、以下のチェーン上のFHEのテーマを取り上げます:
- FHEスキーム、ライブラリ、コンパイラ(FHE Schemes, Libraries and Compilers)
- 安全な閾値復号(Secure Threshold Decryption)
- ユーザー入力と計算者のZKP(ZKPs for User Inputs + Computing Party)
- プログラム可能でスケーラブルなデータ可用性(DA)層(Programmable, Scalable DA Layer)
- FHEハードウェア(FHE Hardware)
全同態暗号(FHE)スキーム、ライブラリ、コンパイラ
挑戦:新興のFHEスキーム、ライブラリ、コンパイラ
チェーン上のFHEの基本的なボトルネックは、その開発ツールとインフラストラクチャの遅れにあります。ゼロ知識証明(ZKP)や多者計算(MPC)とは異なり、FHEは2009年以降の発展が短いため、成熟度が低いです。
FHEの開発体験の主な制約には以下が含まれます:
- 開発者がバックエンドの暗号学を深く理解することなくコーディングできるような使いやすいフロントエンド言語が不足しています。
- パラメータ選択、BGV/BFVのSIMD最適化や並列最適化など、すべての複雑な作業を処理できる完全な機能を持つFHEコンパイラが不足しています。
- 現在のFHEスキーム(特にTFHE)は、通常の計算に比べて約1000倍遅いです。
FHEを統合する複雑さを真に理解するために、開発者が経験するプロセスを見てみましょう:
アプリケーションにFHEを統合する最初のステップは、FHEスキームを選択することです。下の表は主要なスキームを説明しています:
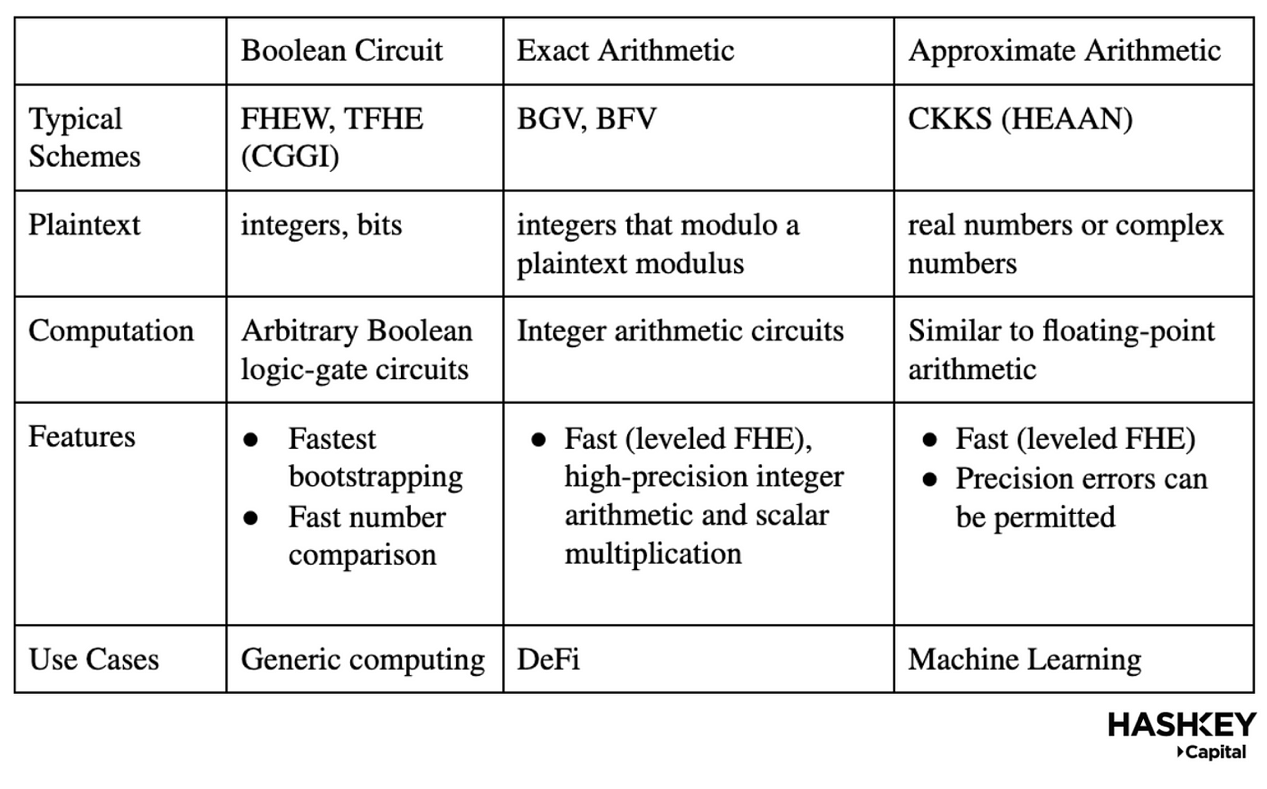
上の表に示すように、ブール回路(FHEWやTFHEなど)は最も速いブートストラッピング速度を持ち、複雑なパラメータ選択プロセスを回避でき、任意/汎用計算に使用できますが、相対的に遅いです。一方、BGV/BFVは一般的なDeFiアプリケーションに適しており、高精度の算術計算においてより効率的ですが、開発者は回路の深さを事前に知っておく必要があります。対照的に、CKKSは同態乗算をサポートし、精度誤差を許容するため、機械学習などの不正確なユースケースに適しています。
開発者として、FHEスキームを慎重に選択する必要があります。なぜなら、それが他のすべての設計決定や将来の性能に影響を与えるからです。また、FHEスキームを正しく設定するために重要なパラメータがいくつかあります。例えば、モジュラスのサイズの選択や多項式の次数の役割などです。
次にライブラリについて議論します。下の表は現在使用されているFHEライブラリの機能と能力を示しています:
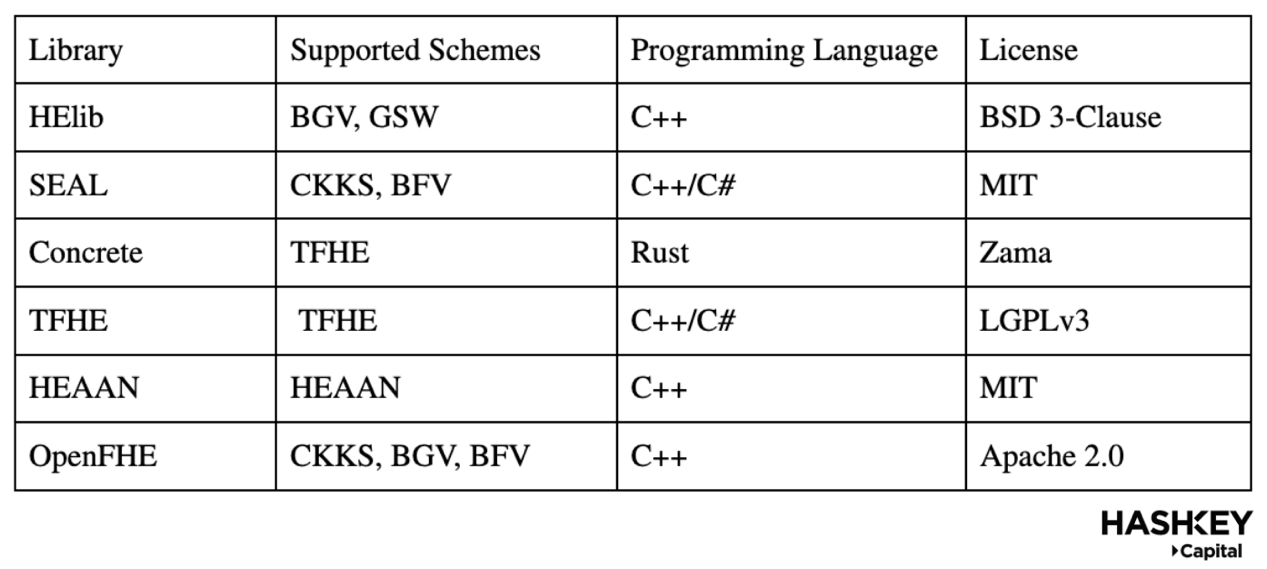
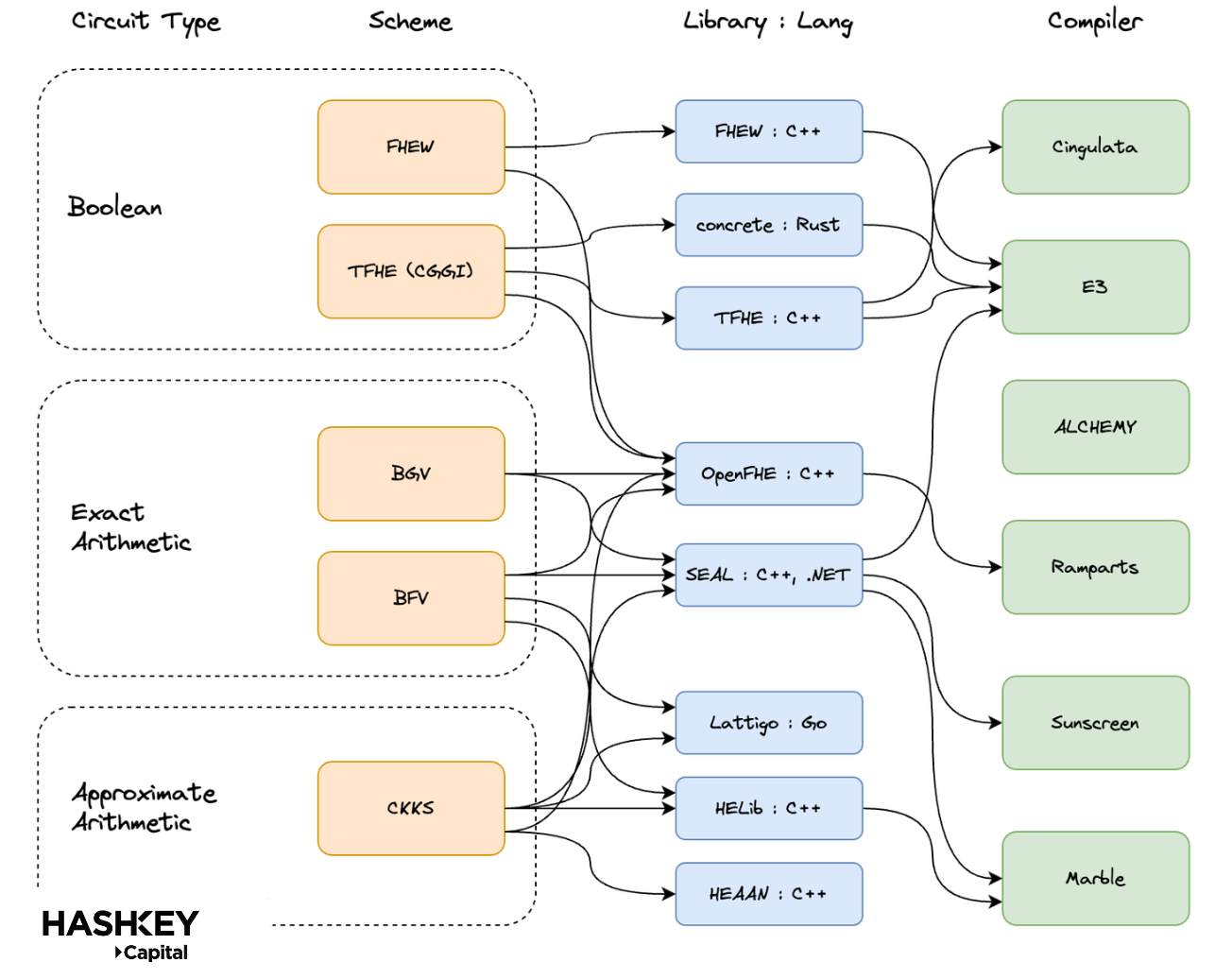
しかし、これらのライブラリは異なるFHEスキームやコンパイラとの関係が異なります。以下のように:
FHEスキームを選択した後、開発者はパラメータを設定する必要があります。正しいパラメータの選択は、FHEスキームの性能に大きな影響を与えます。比較的困難なのは、抽象代数、FHE特有の操作(再線形化やモジュラス切り替えなど)、および算術または二進法回路についての理解が必要であることです。最後に、効果的にパラメータを選択するためには、それらがFHEスキームにどのように影響を与えるかを概念的に理解する必要があります。
この時点で、開発者は次のような質問をするかもしれません:
私の平文(plaintext)空間はどれくらい必要ですか?許容できる暗号文の大きさはどれくらいですか?どこで並列計算できますか?などの質問……
さらに、FHEは任意の計算をサポートできますが、開発者はFHEプログラムを書く際に思考方法を変える必要があります。例えば、プログラム内で変数に基づいて分岐(if-else)を書くことはできません。なぜなら、プログラムは変数を通常のデータとして直接比較することができないからです。代わりに、開発者はコードを分岐からすべての分岐条件を含む何らかの計算に変更する必要があります。同様に、これにより開発者はコード内でループを書くこともできなくなります。
要するに、FHEに不慣れな開発者にとって、FHEをアプリケーションに統合することはほぼ不可能です。これには、FHEが提示する複雑さを抽象化するための重要な開発ツールとインフラストラクチャが必要です。
解決策:
1. Web3特有のFHEコンパイラ
すでにグーグルやマイクロソフトなどの企業によって構築されたFHEコンパイラは存在しますが、それらは:
- 性能を設計目標にしておらず、回路を直接書くのに比べて1000倍の「オーバーヘッド」を増加させます。
- CKKS(つまりML)に最適化されており、DeFiに必要なBFV/BGVにはあまり役立ちません。
- Web3のために構築されていません。ZKPスキームやプログラム可能なブロックチェーンとの互換性をサポートしていません。
Sunscreen FHEコンパイラの登場まで。これはWeb3ネイティブのコンパイラであり、算術操作(例えばDeFi)に対して最高の性能を提供し、ハードウェアアクセラレーターを必要としません。前述のように、パラメータ選択はFHEスキームを実装する際に最も困難な部分かもしれません。Sunscreenはパラメータ選択を自動化するだけでなく、データエンコーディング、鍵選択、再線形化とモジュラス切り替えの実装、回路の設定、SIMD操作の実現を行います。
技術の進歩に伴い、私たちはSunscreenコンパイラだけでなく、他のチームが自分たちのものを構築し、他の高級言語をサポートするさらなる最適化を期待しています。
2. 新しいFHEライブラリ
研究者たちは新しい有効なスキームを探求し続けていますが、FHEライブラリもより多くの開発者がFHEを統合できるようにします。
FHEスマートコントラクトの例を挙げましょう。異なるFHEライブラリから選択することは難しいかもしれませんが、チェーン上のFHEについて話すと、Web3には主導的なプログラミング言語が数種類しかないため、選択が容易になります。
例えば、ZamaのfhEVMは、ZamaのオープンソースライブラリTFHE-rsを典型的なEVMに統合し、同態操作をプレコンパイルコントラクトとして公開します。これにより、開発者はコンパイラツールを変更することなく、彼らのコントラクトで暗号化データを使用できるようになります。
他の特定のシナリオでは、いくつかの他のインフラストラクチャが必要になるかもしれません。例えば、C++で書かれたTFHEライブラリはRustバージョンほどメンテナンスが行き届いていません。TFHE-rsはC/C++のエクスポートをサポートできますが、C++開発者がより良い互換性と性能を求める場合、彼らは自分自身のTFHEライブラリバージョンを書く必要があります。
最後に、市場にFHEインフラストラクチャが不足している核心的な理由の一つは、FHE-RAMを構築するための有効な方法が不足していることです。可能な解決策の一つは、特定の操作コードがないFHE-EVMに関する研究です。
安全な閾値復号(Secure Threshold Decryption)
挑戦:安全でない/中央集権的な閾値復号
すべての秘密の共有状態システムは、暗号化および復号鍵に基づいています。どの単一の当事者も信頼できないため、復号鍵はネットワーク参加者間で多者計算(MPC)を通じて分割されます。
チェーン上の全同態暗号(FHE)の最も挑戦的な側面の一つは、安全で高性能な閾値復号プロトコルを構築することです。主に二つのボトルネックがあります:(1)FHEに基づく計算は著しい「オーバーヘッド」を引き起こすため、高性能のノードが必要であり、これは本質的に検証者集合の潜在的規模を減少させます;(2)復号プロトコルに参加するノードの数が増えると、遅延も増加します。
少なくとも現時点では、FHEプロトコルは検証者の大多数が誠実であることに依存しています(honesty majority)。しかし、上記のように、チェーン上のFHEは小さな検証者集合を意味するため、より高い共謀や悪意の行動の可能性があります。
もし閾値ノードが共謀して悪事を働いた場合、彼らはプロトコルを回避し、基本的にユーザー入力から任意のチェーン上のデータを復号することができるでしょう。さらに、現在のシステムでは復号プロトコルが気づかれずに発生する可能性がある(つまり「サイレントアタック」)ことに注意が必要です。
解決策:改良された閾値復号または動的MPC
閾値復号の欠点を解決するためのいくつかの可能な方法があります。(1)n/2の閾値を有効にすることで、共謀をより困難にします;(2)ハードウェアセキュリティモジュール(HSM)内で閾値復号プロトコルを実行します;(3)信頼された実行環境(TEE)に基づく閾値復号ネットワークを使用し、分散型チェーンが認証を制御し、動的な鍵管理を可能にします。
閾値復号を利用する代わりに、MPCを使用する可能性が高いです。チェーン上のFHEで使用できるMPCプロトコルの現象的な例は、Odsyの新しい2PC-MPCであり、これは初の非共謀かつ大規模に分散化されたMPCアルゴリズムです。
別の方法は、ユーザーの公開鍵のみを使用してデータを暗号化することです。その後、検証者が同態操作を処理し、必要に応じてユーザー自身が結果を復号できます。これは特定のユースケースにのみ適用されますが、閾値仮定を完全に回避することができます。
要約すると、チェーン上のFHEには、次の特徴を持つ効率的なMPC実装が必要です:(1)悪意のある行為者が存在する場合でも機能する;(2)最小限の遅延を導入する;(3)許可なしで柔軟なノードの参加を許可する。
ユーザー入力と計算者のゼロ知識証明(ZKP)
挑戦:ユーザー入力と計算の可検証性:
Web2の世界では、計算タスクの実行を要求する際、私たちは特定の企業が約束した通りにそのタスクを裏で実行することを完全に信頼しています。Web3では、このモデルは完全に逆転しています。私たちはもはや企業の評判に依存せず、彼らが誠実に行動することを単純に信じるのではなく、信頼を必要としない環境で運営されています。つまり、ユーザーは誰も信頼する必要がないのです。
全同態暗号(FHE)は暗号化データを処理することを許可しますが、ユーザー入力や計算の正確性を検証することはできません。検証能力がなければ、FHEはブロックチェーンの文脈ではほとんど役に立ちません。
解決策:ユーザー入力と計算者のZKP:
FHEは誰でも暗号化データに対して任意の計算を行うことを許可しますが、ZKPは人々が基礎となる情報を明らかにすることなく、何かが真実であることを証明することを可能にします。それでは、これらはどのように関連しているのでしょうか?
FHEとZKPの組み合わせには、三つの重要な方法があります:
- ユーザーは、彼らの入力暗号文が正しい形式であることを示す証明を提出する必要があります。これは、暗号文が暗号スキームの要件を満たしていることを意味し、単なる任意のデータ文字列ではありません。
- ユーザーは、彼らの入力平文が与えられたアプリケーションの条件を満たしていることを示す証明を提出する必要があります。例えば、アカウントの残高が送金額より大きいこと。
- 検証ノード(計算者)は、彼らがFHE計算を正しく実行したことを証明する必要があります。これは「検証可能なFHE」と呼ばれ、ロールアップに必要なZKPの類似物と見なすことができます。
ZKPの応用をさらに探求するために:
1. 暗号文のZKP
FHEは格(lattice)に基づく暗号学に基づいており、これは暗号原語の構造が格に関与しており、これらの格は後量子(post-quantum)安全です。対照的に、人気のあるZKP、例えばSNARKs、STARKs、Bulletproofsは、格に基づく暗号学に依存していません。
ユーザーのFHE暗号文形式が正しいことを証明するためには、リングからの要素(entries from rings)を持つ行列-ベクトル方程式を満たすことを示す必要があります。基本的には、格に基づく関係(lattice-based relations)を処理するために設計された、チェーン上での検証コストが効率的な証明システムが必要であり、これはオープンな研究分野です。
2. 明文入力のZKP
形式が正しい暗号文を証明するだけでなく、ユーザーは彼らの入力平文がアプリケーションの要件を満たしていることを証明する必要があります。幸いなことに、前のステップとは異なり、一般的なSNARKsを利用してユーザー入力の有効性を証明できるため、開発者は既存のZKPスキーム、ライブラリ、インフラストラクチャを利用できます。
しかし、課題は、これら二つの証明システムを「接続」する必要があることです。接続とは、ユーザーが二つの証明システムで同じ入力を使用したことを確認する必要があることを意味します。そうでなければ、悪意のあるユーザーがプロトコルを欺く可能性があります。ここで再度強調する必要がありますが、これは非常に困難な暗号学的偉業であり、初期研究のオープンな分野です。
Sunscreenはこのための基盤を築いており、彼らのZKPコンパイラはBulletproofsをサポートしています。これはSDLPとの接続が最も容易です。FHEとZKPコンパイラの「接続」に関する研究も進行中です。
Mind NetworkはZKPの統合をリードしており、ゼロ信頼の入力と出力を確保しつつ、FHEを利用して安全な計算を行っています。
3. 正確な計算のZKP
既存のハードウェア上で動作するFHEは非常に非効率的で高価です。前述のスケーラビリティの三難問題の動的な表現のように、ノードリソースに対する要求が高いネットワークは、十分な分散化レベルにスケールすることができません。可能な解決策は、「検証可能なFHE」と呼ばれるプロセスであり、計算者(検証者)が取引の誠実な実行を証明するためにZKPを提出します。
検証可能なFHEの初期プロトタイプは、SherLOCKEDというプロジェクトを通じて示すことができます。本質的に、FHE計算はRisc ZEROのBonsai zkVMにロードされ、このVMはチェーン外で暗号化データ上の計算を処理し、ZKPを伴う結果を返し、チェーン上の状態を更新します。

最近のFHE協処理器を利用した例として、Aztecのチェーン上のオークションデモがあります。前述のように、既存のFHEチェーンは閾値鍵で全体の状態を暗号化しており、これはシステムの強度がその閾値委員会(threshold committee)に依存することを意味します。対照的に、Aztecではユーザーが自分のデータを所有しているため、閾値安全仮定の制約を受けません。
最後に、開発者が最初にFHEアプリケーションを構築できる場所を理解することが重要です。開発者はFHEをサポートするL1、FHEロールアップ上でアプリケーションを構築するか、任意のEVMチェーン上で構築し、FHE協処理器を利用することができます。各設計にはそれぞれのトレードオフがありますが、私たちはFhenixが開創した設計の良いFHEロールアップやFHE協処理器を好みます。なぜなら、これらはイーサリアムからセキュリティなどの他の利点を引き継いでいるからです。
最近まで、FHE暗号化データ上で詐欺証明を実現することは複雑でしたが、最近Fhenix.ioのチームは、Arbitrum Nitroスタックを使用してFHEロジックをWebAssemblyにコンパイルすることで詐欺証明を実現する方法を示しました。
FHEのデータ可用性(DA)層
挑戦:カスタマイズ性とスループットの不足
Web2では「ストレージ」が商品化されていますが、Web3ではそうではありません。全同態暗号(FHE)が10000倍以上のデータ膨張を維持していることを考えると、大量のFHE暗号文をどこに保存するかを決定する必要があります。与えられたDA層の各ノードオペレーターがFHEチェーンのデータをすべてダウンロードして保存する必要がある場合、機関オペレーターのみが需要に追いつくことができ、中央集権のリスクが増加します。
スループットに関しては、Celestiaの最高速度は6.7 MB/sであり、FHEMLのいかなる形式を実行したい場合、毎秒数GBの帯域幅が必要です。1k(x)が最近共有したデータによると、設計上の決定がスループットを制限しているため(意図的に)、既存のDA層はFHEをサポートできません。
解決策:水平スケーリング + カスタマイズ性
私たちは水平にスケーラブルなDA層をサポートできるものが必要です。既存のDAアーキテクチャは、すべてのデータをネットワーク内の各ノードに伝播させるため、スケーラビリティの主要な制約となっています。対照的に、より多くのDAノードがシステムに参加するにつれて、水平スケーラビリティは各ノードが保存するデータ量を減少させ、より多くのブロックスペースが利用可能になることで性能とコストが改善されます。
さらに、FHEに関連する大量のデータのサイズを考慮すると、開発者に対してより高いレベルのエラーメッセージのカスタマイズを提供することが理にかなっています。言い換えれば、開発者はDAシステムに対してどの程度の保証を求めているのでしょうか?それは権益に基づく重み付けか、分散化に基づく重み付けか。
EigenDAのアーキテクチャは、FHEのDA層の可能性の一つの基盤として機能します。その水平スケーラビリティ、構造コストの削減、DAとコンセンサスのデカップリングなどの特性は、FHEのスケーラビリティレベルをサポートするための道を開いています。
最後に、より高次元のアイデアは、FHE暗号文を保存するために最適化されたストレージスロットを構築することかもしれません。暗号文が特定のエンコーディングスキームに従うため、最適化されたストレージスロットを持つことは、ストレージスペースの効率的な使用とより迅速な取得に役立つ可能性があります。
全同態暗号(FHE)ハードウェア
挑戦:低性能の全同態暗号(FHE)ハードウェア
チェーン上の全同態暗号(FHE)アプリケーションの普及において、主要な問題は計算オーバーヘッドによる著しい遅延であり、これにより標準的な処理ハードウェア上でFHEを実行することが非現実的になります。この制約は、大量のデータを処理する必要があるため、メモリとの大量の相互作用に起因しています。メモリの相互作用に加えて、複雑な多項式計算や時間のかかる暗号文の維持操作も多くのオーバーヘッドを引き起こします。
FHEアクセラレーターの状態を深く理解するためには、特定のアプリケーション向けのFHEアクセラレーターと汎用のFHEアクセラレーターの具体的な設計を明らかにする必要があります。
FHEの計算の複雑さとハードウェア設計の核心は、与えられたアプリケーションに必要な乗算の数に常に関連しています。これは「同態操作の深さ」と呼ばれます。特定のアプリケーションの場合、深さは既知であるため、システムパラメータと関連計算は固定されています。したがって、特定のアプリケーション向けのハードウェア設計は容易であり、通常は汎用アクセラレーター設計よりも優れた性能を得ることができます。一般的に、FHEが任意の数の乗算をサポートする必要がある場合、同態操作に蓄積されたノイズの一部を除去するためにブートストラッピング技術を導入する必要があります。ブートストラッピング技術はコストが高く、大量のハードウェアリソース(チップメモリ、メモリ帯域幅、計算など)を必要とするため、ハードウェア設計は特定のアプリケーションの設計とは大きく異なることになります。したがって、インテル、Duality、SRI、DARPAなどの業界の重要な参加者がGPUやASIC設計に関して行っている作業は、上限を引き上げることに疑いなく貢献していますが、ブロックチェーンシナリオをサポートするために一対一で適用できるわけではありません。
開発コストの観点から、汎用ハードウェアは特定のアプリケーション向けのハードウェアよりも設計と製造に多くの資本を必要としますが、その柔軟性により、ハードウェアはより広範なアプリケーション範囲で使用できます。一方、特定のアプリケーション向けの設計では、アプリケーションの要求が変化し、より深い同態計算をサポートする必要がある場合、特定のアプリケーション向けのハードウェアをいくつかのソフトウェア技術(MPCなど)と組み合わせて、汎用ハードウェアと同じ目的を達成する必要があります。
特定のアプリケーションユースケース(例えばFHEML)と比較して、チェーン上のFHEの加速ははるかに困難です。なぜなら、より一般的な計算を処理できる必要があるからです。例えば、fhEVM開発ネットワークの現在の取引処理速度は、単位数TPSに制限されています。
ブロックチェーン向けにカスタマイズされたFHEアクセラレーターが必要であることを考慮すると、もう一つの考慮事項は、ZKPハードウェアからFHEハードウェアへの移行性がどのようになるかです。
ZKPとFHEの間には、数論変換(NTT)や基礎的な多項式操作など、いくつかの共通モジュールがあります。しかし、これら二つのケースで使用されるNTTのビット幅(bit width)は異なります。ZKPでは、ハードウェアは64ビットや256ビットなど、NTTのさまざまなビット幅をサポートする必要がありますが、FHEでは残余数システムを使用しているため、NTTのオペランドは短くなります。次に、ZKPで処理されるNTTの次数は通常FHEよりも高いです。この二つの理由から、ZKPとFHEの両方に対して開発者が満足できる性能を持つNTTモジュールを設計することは容易ではありません。
NTTの他にも、FHEにはZKPには存在しない自同型(automorphism)などの計算ボトルネックがいくつかあります。ZKPハードウェアをFHE設定に単純に移行する一つの方法は、NTT計算タスクをZKPハードウェアにロードし、CPUまたは他のハードウェアを使用してFHEの残りの計算を処理することです。
これらの課題をまとめると、暗号化データ上でFHEを使用して計算することは、平文データ上で行うよりも100,000倍遅いことがかつてありました。しかし、新しい暗号スキームやFHEハードウェアの最新の進展により、現在の性能は平文データよりも約100倍遅いという大幅な改善が見られています。
解決策:
1. FHEハードウェアの改良
多くのチームがFHEアクセラレーターの構築に積極的に取り組んでいますが、彼らは汎用ブロックチェーン計算(例えばTFHE)特有のFHEアクセラレーターに焦点を当てていません。ブロックチェーン向けの特定のハードウェアアクセラレーターの例は、FPTという固定小数点FPGAアクセラレーターです。FPTは、FHE計算における固有のノイズを重度に利用する最初のハードウェアアクセラレーターであり、完全に近似の固定小数点算術を使用してTFHEを実現しています。FHEに役立つ可能性のある別のプロジェクトは、クラウドでFHE計算を大幅に加速することを目的としたハードウェアアクセラレーターアーキテクチャのシリーズであるBASALISCです。
前述のように、FHEハードウェア設計の主要なボトルネックは、メモリとの大量の相互作用です。この障害を回避するための潜在的な解決策は、メモリとの相互作用を可能な限り減らすことです。プロセッサ内メモリ(PIM)や近接メモリ計算(near memory computation)がこの場合に役立つかもしれません。PIMは、未来のコンピュータシステムの「メモリの壁(memory wall)」の課題に対処するための有望な解決策であり、メモリが計算とストレージの両方の機能を同時に担うことを可能にし、計算とメモリの関係に根本的な改革を約束します。
過去10年間で、この問題を解決するための非揮発性メモリの設計において大きな進展がありました。例えば、抵抗型RAM、自旋転移トルク磁気RAM、相変化メモリなどです。この特殊なメモリを使用することで、機械学習や格に基づく公開鍵暗号において計算性能が大幅に改善されたことが示されています。
2. 最適化されたソフトウェアとハードウェア
最近の進展において、ソフトウェアはハードウェア加速プロセスの重要な構成要素として認識されています。例えば、著名なFHEアクセラレーターであるF1やCraterLakeは、コンパイラを使用してハイブリッドなソフトウェアとハードウェアの共同設計を行っています。
この分野の進展に伴い、私たちはブロックチェーン向けのFHEコンパイラと共同設計された機能豊富なコンパイラを期待しています。FHEコンパイラは、対応するFHEスキームのコストモデルに基づいてFHEプログラムを最適化できます。これらのFHEコンパイラは、FHEアクセラレーターコンパイラと統合され、ハードウェアレベルのコストモデルを組み合わせることで、エンドツーエンドの性能を改善します。
3. ネットワークFHEアクセラレーター:垂直スケーリングから水平スケーリングへ
FHEハードウェア加速に関する既存の努力は、主に「垂直スケーリング」に集中しており、単一のアクセラレーターの垂直的な改善に焦点を当てています。一方、「水平スケーリング」は、ネットワークを通じて複数のFHEアクセラレーターを横方向に接続することに焦点を当てており、これにより性能が大幅に向上する可能性があります。これは、ゼロ知識証明(ZKPs)の並列証明生成と類似しています。
FHE加速の主要な困難は、データ膨張の問題です。これは、暗号化と計算の過程でデータサイズが著しく増加することを指し、チップ内とチップ外のメモリ間での効率的なデータ転送に課題をもたらします。
データ膨張は、複数のFHEアクセラレーターをネットワークで横方向に接続することに対して顕著な課題をもたらします。したがって、FHEハードウェアとネットワークの共同設計は、今後の研究の有望な方向性となるでしょう。例えば、FHEアクセラレーターの適応型ネットワークルーティングを実現し、リアルタイムの計算負荷やネットワークトラフィックに基づいて、FHEアクセラレーター間のデータパスのルーティングメカニズムを動的に調整することができます。これにより、最適なデータ転送速度と効率的なリソース利用が確保されるでしょう。
終わりに
FHEは、私たちがさまざまなプラットフォームでデータを保護する方法を根本的に再構築し、前例のないプライバシーの新時代への道を開くことになるでしょう。このようなシステムを構築するには、FHE、ゼロ知識証明(ZKPs)、多者計算(MPC)において重要な進展が必要です。
この新しい分野に入る際、暗号学者、ソフトウェアエンジニア、ハードウェア専門家の協力が不可欠です。法制化者や規制機関なども言うまでもなく、コンプライアンスは主流の採用を実現する唯一の道です。
結局のところ、FHEはデジタル主権の変革の波の最前線に立ち、データのプライバシーとセキュリティが相互排除ではなく、密接に結びついた未来を予示しています。
特別な感謝
非常に感謝します Mason Song(Mind Network)、Guy Itzhaki(Fhenix)、Leo Fan(Cysic)、Kurt Pan、Xiang Xie(PADO)、Nitanshu Lokhande(BananaHQ)のレビューに。私たちは読者がこれらの人々がこの分野で行った印象的な仕事と努力を理解することを期待しています!






