
IOSG: GPU Supply Crisis, Path to Breakthrough for AI Startups

 GPU clusters may face a similar aggregated fate as CDNs.
GPU clusters may face a similar aggregated fate as CDNs.Author: Mohit Pandit, IOSG Ventures
Abstract
The GPU shortage is a reality, with tight supply and demand, but the number of underutilized GPUs can meet today's supply-constrained needs.
An incentive layer is needed to promote participation in cloud computing, and ultimately coordinate computational tasks for inference or training. The DePIN model is well-suited for this purpose.
Due to incentives on the supply side and lower computing costs, the demand side finds this attractive.
Not everything is rosy; certain trade-offs must be made when choosing Web3 cloud, such as 'latency'. The trade-offs compared to traditional GPU clouds also include insurance, Service Level Agreements, etc.
The DePIN model has the potential to address GPU availability issues, but a fragmented model will not improve the situation. In cases where demand is growing exponentially, fragmented supply is as bad as no supply.
Given the number of new market participants, market aggregation is inevitable.
Introduction
We are on the brink of a new era in machine learning and artificial intelligence. While AI has existed in various forms for some time (AI refers to computer devices instructed to perform tasks that humans can do, such as washing machines), we are now witnessing the emergence of complex cognitive models capable of performing tasks that require intelligent human behavior. Notable examples include OpenAI's GPT-4 and DALL-E 2, as well as Google's Gemini.
In the rapidly growing field of artificial intelligence (AI), we must recognize the dual aspects of development: model training and inference. Inference involves the functionality and output of AI models, while training encompasses the complex processes required to build intelligent models (including machine learning algorithms, datasets, and computational power).
Taking GPT-4 as an example, end users are primarily concerned with inference: obtaining output from the model based on text input. However, the quality of this inference depends on model training. To train effective AI models, developers need access to comprehensive foundational datasets and immense computational power. These resources are primarily concentrated in the hands of industry giants, including OpenAI, Google, Microsoft, and AWS.
The formula is simple: better model training >> leads to enhanced AI model inference capabilities >> which attracts more users >> resulting in increased revenue, thereby providing more resources for further training.
These major players have access to large foundational datasets and, more critically, control vast amounts of computational power, creating barriers to entry for emerging developers. As a result, new entrants often struggle to obtain sufficient data or leverage the necessary computational power at an economically viable scale. Given this situation, we see that the network has significant value in democratizing resource access, primarily related to large-scale acquisition of computational resources and cost reduction.
GPU Supply Issues
NVIDIA's CEO Jensen Huang stated at CES 2019 that "Moore's Law is over." Today's GPUs are extremely underutilized. Even during deep learning/training cycles, GPUs are not fully utilized.
Here are typical GPU utilization figures for different workloads:
Idle (just booted into Windows): 0-2%
General productivity tasks (writing, simple browsing): 0-15%
Video playback: 15 - 35%
PC gaming: 25 - 95%
Graphic design/photo editing active workloads (Photoshop, Illustrator): 15 - 55%
Video editing (active): 15 - 55%
Video editing (rendering): 33 - 100%
3D rendering (CUDA / OptiX): 33 - 100% (often misreported by Windows Task Manager - use GPU-Z)
Most consumer devices with GPUs fall into the first three categories.
Image GPU runtime utilization %. Source: Weights and Biases
The above situation points to a problem: poor utilization of computational resources.
There is a need to better utilize the capacity of consumer GPUs, even when GPU utilization peaks, it is suboptimal. This clarifies two things that need to be done in the future:
Resource (GPU) aggregation
Parallelization of training tasks
In terms of available hardware types, there are currently four types for supply:
· Data center GPUs (e.g., Nvidia A100s)
· Consumer GPUs (e.g., Nvidia RTX3060)
· Custom ASICs (e.g., Coreweave IPU)
· Consumer SoCs (e.g., Apple M2)
With the exception of ASICs (as they are built for specific purposes), other hardware can be aggregated for the most efficient utilization. With many such chips in the hands of consumers and data centers, the aggregation of supply-side DePIN models may be a viable path.
GPU production is a volume pyramid; consumer-grade GPUs have the highest output, while high-end GPUs like NVIDIA A100s and H100s have the lowest output (but higher performance). The cost of producing these high-end chips is 15 times that of consumer GPUs, yet they do not always deliver 15 times the performance.
The entire cloud computing market is currently valued at approximately $483 billion, and is expected to grow at a compound annual growth rate of about 27% over the next few years. By 2023, there will be approximately 13 billion hours of ML computing demand, which, at current standard rates, translates to about $56 billion in spending on ML computing in 2023. This entire market is also rapidly growing, doubling every three months.
GPU Demand
Computational demand primarily comes from AI developers (researchers and engineers). Their main requirements are: price (low-cost computing), scale (large amounts of GPU computing), and user experience (ease of access and use). Over the past two years, there has been a massive demand for GPUs due to the increased need for AI-based applications and the development of ML models. Developing and running ML models requires:
Significant computation (from accessing multiple GPUs or data centers)
The ability to perform model training, fine-tuning, and inference, with each task deployed across a large number of GPUs for parallel execution
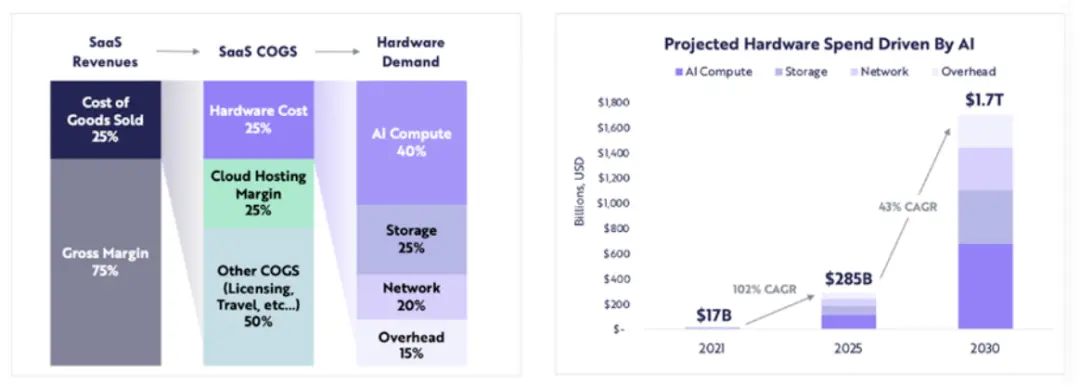
Expenditures related to computing hardware are expected to grow from $17 billion in 2021 to $285 billion by 2025 (approximately a 102% compound annual growth rate), with ARK projecting that computing-related hardware expenditures will reach $1.7 trillion by 2030 (43% compound annual growth rate).
ARK Research
With many LLMs in the innovation stage, competition drives the demand for more parameters in computation, as well as retraining, we can expect a sustained demand for high-quality computation in the coming years.
Where Does Blockchain Fit In With New GPU Supply Constraints?
When resources are scarce, the DePIN model can provide assistance:
Activate the supply side, creating a large supply
Coordinate and complete tasks
Ensure tasks are completed correctly
Correctly reward providers for completed work
Aggregating any type of GPU (consumer, enterprise, high-performance, etc.) may encounter issues in utilization. When computational tasks are split, A100 chips should not be performing simple computations. GPU networks need to decide what types of GPUs they believe should be included in the network, based on their market entry strategy.
When computational resources themselves are dispersed (sometimes globally), users or the protocol itself must make choices about which type of computational framework to use. Providers like io.net allow users to choose from three computational frameworks: Ray, Mega-Ray, or deploying Kubernetes clusters to execute computational tasks in containers. There are more distributed computing frameworks, such as Apache Spark, but Ray is the most commonly used. Once the selected GPU completes the computational task, the output will be reconstructed to yield a trained model.
A well-designed token model will subsidize computing costs for GPU providers, making such solutions more attractive to many developers (the demand side). Distributed computing systems inherently have latency. There is computation decomposition and output reconstruction. Therefore, developers need to weigh the cost-effectiveness of training models against the time required.
Do Distributed Computing Systems Need Their Own Chain?
Networks can operate in two ways:
Charge per task (or computational cycle) or charge by time
Charge by time unit
In the first method, a work proof chain similar to what Gensyn is attempting can be built, where different GPUs share the "work" and thus earn rewards. For a more trustless model, they have the concept of validators and whistleblowers who are rewarded for maintaining the integrity of the system, based on proofs generated by solvers.
Another work proof system is Exabits, which does not split tasks but treats its entire GPU network as a single supercomputer. This model seems better suited for large LLMs.
Akash Network has increased GPU support and started aggregating GPUs into this space. They have an underlying L1 to reach consensus on state (showing the work completed by GPU providers), a market layer, and container orchestration systems like Kubernetes or Docker Swarm to manage the deployment and scaling of user applications.
For a system to be trustless, a work proof chain model would be most effective. This ensures the coordination and integrity of the protocol.
On the other hand, systems like io.net have not positioned themselves as a chain. They choose to address the core issue of GPU availability and charge customers by time unit (per hour). They do not require a verifiability layer because they are essentially "renting" GPUs for unrestricted use during a specific lease period. The protocol itself does not involve task splitting but is completed by developers using open-source frameworks like Ray, Mega-Ray, or Kubernetes.
Web2 vs. Web3 GPU Cloud
Web2 has many participants in the GPU cloud or GPU-as-a-service space. Major players in this field include AWS, CoreWeave, PaperSpace, Jarvis Labs, Lambda Labs, Google Cloud, Microsoft Azure, and OVH Cloud.
This is a traditional cloud business model where customers can rent GPUs (or multiple GPUs) by time unit (usually by the hour) when they need computation. There are many different solutions available for various use cases.
The main differences between Web2 and Web3 GPU clouds lie in the following parameters:
- Cloud setup costs
Due to token incentives, the cost of establishing a GPU cloud is significantly lower. OpenAI is raising $1 trillion for the production of computing chips. It seems that defeating market leaders without token incentives would require at least $1 trillion.
- Computing time
Non-Web3 GPU clouds will be faster because the rented GPU clusters are located within geographic regions, while Web3 models may have a more widely distributed system, with latency potentially arising from inefficient task splitting, load balancing, and, most importantly, bandwidth.
- Computing costs
Due to token incentives, the costs of Web3 computing will be significantly lower than existing Web2 models.
Comparison of computing costs:
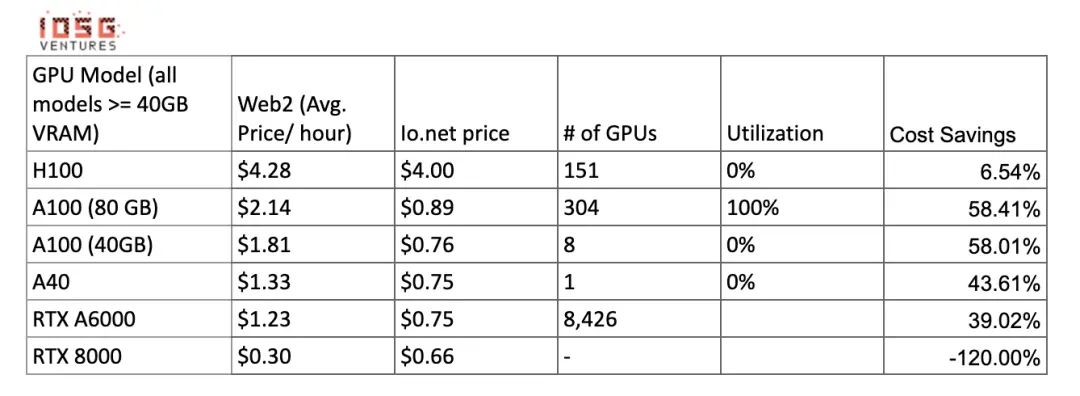
Image These numbers may change when there is more supply and utilization of clusters providing these GPUs. Gensyn claims to offer A100s (and their equivalents) for as low as $0.55 per hour, while Exabits promises a similar cost-saving structure.
4. Compliance
In permissionless systems, compliance is not easy. However, Web3 systems like io.net and Gensyn do not position themselves as permissionless systems. They address compliance issues such as GDPR and HIPAA during the GPU onboarding, data loading, data sharing, and result sharing phases.
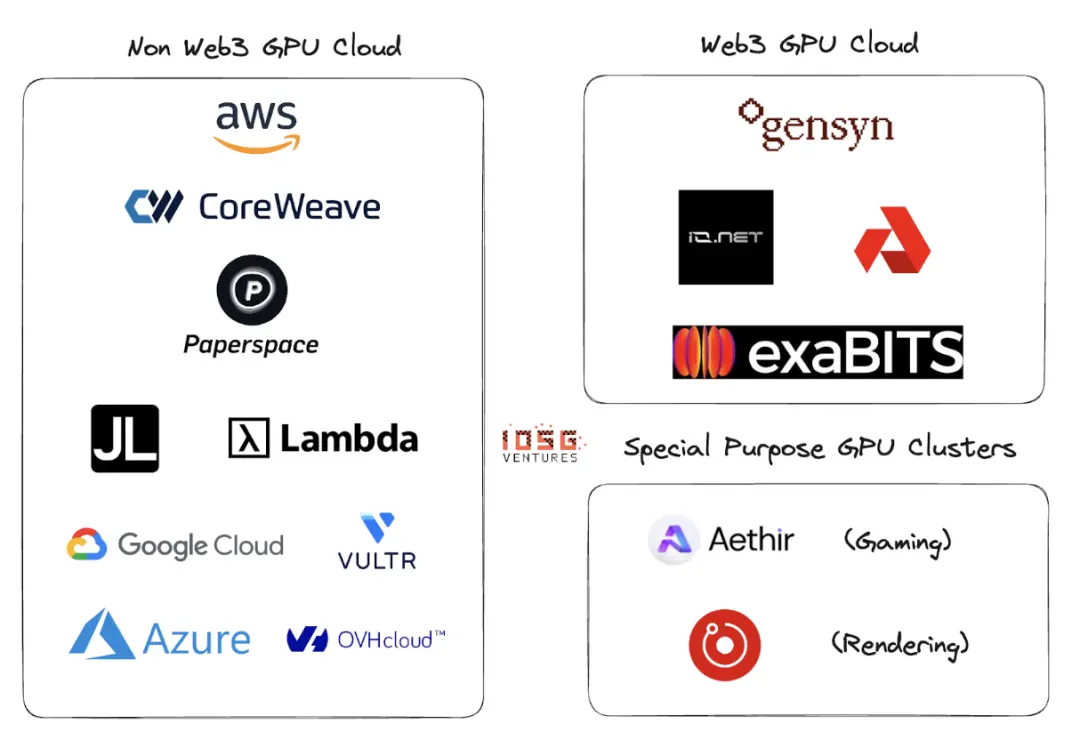
Ecosystem
Gensyn, io.net, Exabits, Akash
Risks
- Demand Risk
I believe that top LLM players will either continue to accumulate GPUs or utilize GPU clusters like NVIDIA's Selene supercomputer, which has a peak performance of 2.8 exaFLOP/s. They will not rely on consumer or long-tail cloud providers to aggregate GPUs. Currently, the competition among top AI organizations is more about quality than cost.
For non-heavy ML models, they will seek cheaper computing resources, and blockchain-based token-incentivized GPU clusters can provide services while optimizing existing GPUs (the above assumes that those organizations prefer to train their own models rather than using LLMs).
- Supply Risk
With significant capital invested in ASIC research and inventions like tensor processing units (TPUs), this GPU supply issue may resolve itself. If these ASICs can provide a good performance-to-cost ratio, the existing GPUs hoarded by large AI organizations may return to the market.
Does blockchain-based GPU clustering solve a long-term problem? While blockchain can support any chip beyond GPUs, the actions of the demand side will entirely determine the direction of projects in this field.
Conclusion
A fragmented network with small GPU clusters will not solve the problem. There is no position for "long-tail" GPU clusters. GPU providers (retail or smaller cloud players) will tend to favor larger networks, as the incentives of the network are better. It will be the functionality of a good token model and the ability of the supply side to support multiple types of computation.
GPU clusters may see a similar aggregative fate as CDNs. If large players want to compete with existing leaders like AWS, they may begin to share resources to reduce network latency and the geographic proximity of nodes.
If the demand side grows larger (more models to train, more parameters to train), Web3 players must be very proactive in the development of supply-side businesses. If too many clusters compete from the same customer base, fragmented supply will occur (rendering the entire concept ineffective), while demand (measured in TFLOPs) grows exponentially.
Io.net has already stood out from numerous competitors by starting with an aggregator model. They have aggregated GPUs from Render Network and Filecoin miners, providing capacity while also guiding supply on their own platform. This could be the winning direction for DePIN GPU clusters.







