

















Understanding the AI-focused decentralized Web3 underlying protocol KIP Protocol #2

 RAG is an innovative technology used in generative AI, involving three key value creators in AI (app developers, model creators, and data owners). The KIP Protocol is the world's first protocol supporting decentralized RAG, essentially providing a foundational framework for decentralizing all AI, which is the first step in helping to break free from the monopoly of AI giants.
RAG is an innovative technology used in generative AI, involving three key value creators in AI (app developers, model creators, and data owners). The KIP Protocol is the world's first protocol supporting decentralized RAG, essentially providing a foundational framework for decentralizing all AI, which is the first step in helping to break free from the monopoly of AI giants.1) Overview of RAG
AI models are trained by feeding them large amounts of data. They learn from the data, adjusting internal weights to recognize patterns, enabling them to make predictions or decisions based on new data. The model can then answer user questions based on the newly acquired "raw" knowledge.
However, this training process requires exposing the entire dataset to the model, which essentially leads to the data being "absorbed" into the model. If the data contains confidential or copyrighted information, the model may potentially reveal this information verbatim at some point in the future.
So, what if you don't want your data to be at risk?
This is where RAG (Retrieval-Augmented Generation) comes into play.
RAG is a sophisticated technology that allows AI models to generate answers they originally did not know by retrieving data and information from external knowledge bases and databases.
It acts like a smart assistant that, while not knowing the answer to your question, can professionally find the answer you seek from external data.
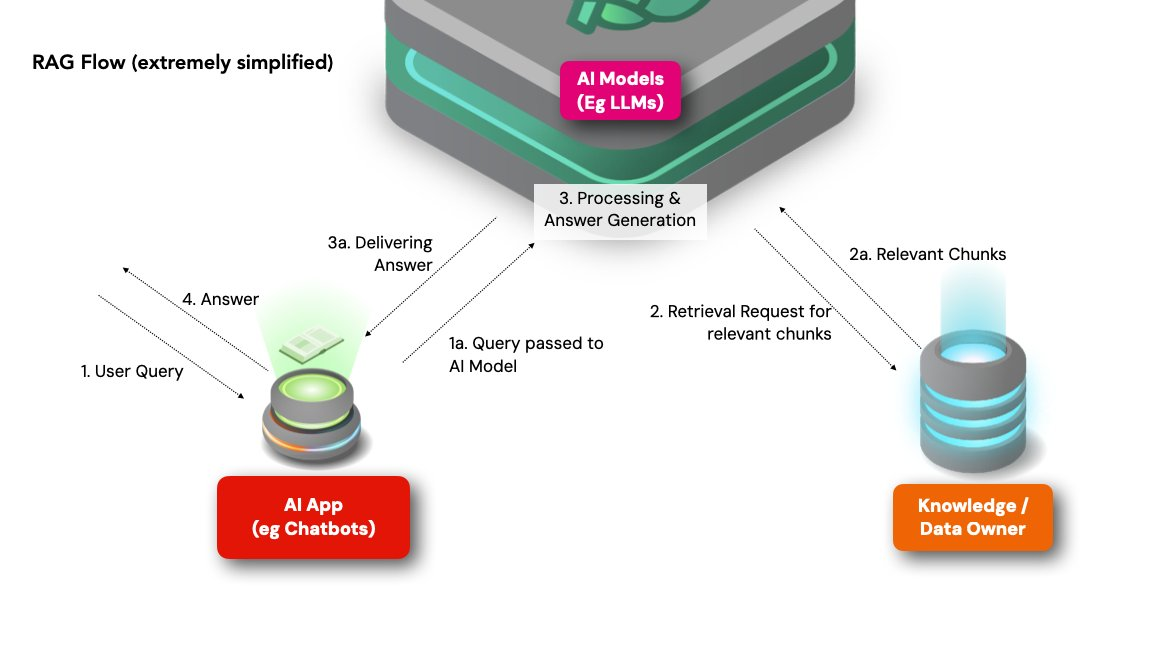
1. User Query Input:
First, the user poses a question to the chatbot running the RAG system.
For example, "What are the symptoms of COVID-19?"
2. Retrieval from External Databases:
The model searches connected external knowledge bases and databases, such as medical journals, health websites, and clinical databases, to initiate the retrieval phase, only fetching data and information relevant to the user query.
3. Data Processing, Filtering, and Generation:
The retrieved data is processed and filtered to extract key information and eliminate irrelevant data. The AI model integrates the retrieved data with the context of the user query to generate an answer.
In the case of the COVID-19 symptoms query, RAG might generate a response listing common symptoms such as fever, cough, and shortness of breath, but it may also include information from the latest medical research papers that the model was not trained on—a higher quality answer.
4. Sending the Reply:
The generated reply is presented to the user through the chatbot interface.
Thus, RAG allows the use of external data to answer AI queries without requiring the model to first "absorb" this data through a training process.
RAG technology is becoming increasingly mature, and in our research paper, we demonstrate that the quality of answers provided by RAG can surpass those of well-trained models. https://arxiv.org/pdf/2311.05903.pdf
2) Importance of RAG
RAG will become increasingly important because:
Training models is a highly technical and specialized task, often at a high cost—not everyone has the skills or resources required to train models.
Many data owners (confidential data, proprietary data, etc.) may be reluctant to expose their data to models that they do not fully own or control.
You may also notice an important issue:
Under the RAG framework, app developers, model creators, and data owners can collaborate, each contributing to answering user queries.
Therefore, in a fair scenario, all parties should receive fair compensation for their contributions.

However, there is currently no simple way to achieve this without compromising the independence or ownership of the parties involved. (By the way, this issue is precisely what prompted us to start building KIP over a year ago).
This is the "revenue problem."
3) The "Revenue Problem" of RAG and Centralized AI
Let’s imagine a scenario where one entity owns all three elements of AI value creation: there is no need to redistribute payments collected from users among the parties because internal accounting can be done directly.
Conversely, if we cannot accept that one entity owns all three elements of AI value creation (app developers, model creators, and data owners), we must address how to resolve the revenue problem among the roles of AI value creation across different industries.
If the "revenue problem" is not resolved, app developers, model creators, and data owners will not be able to maintain their independence and transactional freedom.
However, the monopoly in the AI industry has already begun.
Here are our views on the OpenAI monopoly:
OpenAI clearly possesses some of the most powerful models—closed-source models like GPT-4, which are trained on knowledge and content collected from the internet over the years. This fuels their apps (like ChatGPT) and user-created GPTs.
Through their copyright protection measures (i.e., the commitment to pay legal fees for anyone found uploading copyrighted data to their platform), they encourage users to upload data to their closed platform without worrying about legal consequences.
Given that OpenAI is a centralized, closed-source web2 platform, we should ask ourselves: does the data uploaded by users (whether for ChatGPT or GPT Apps) still belong to the uploader?
Therefore, based on their existing models, their unreserved "scraping" of all data, copyright protection measures, and massive funding reserves, you might find that OpenAI is the most greedy "data vacuum cleaner" in history, continuously sucking in data and resources to meet the needs of their models.
Putting all these factors together (along with the $7 billion they raised for hardware), it is not hard to see that, unless some measures are taken, the complete monopoly of the AI industry by one or a few companies will be inevitable.
Based on the reasons we have shared, we firmly believe that the monopoly in the AI industry is detrimental to humanity, and we will actively seek solutions to escape this monopoly.
4) The Significance of Decentralized RAG
RAG involves all three core factors of AI value creation (app developers, model creators, and data owners).
Therefore, by establishing a decentralized RAG framework, KIP is essentially creating a decentralized control framework for AI value creation, providing a fair competitive environment for all value creators and breaking free from AI monopolies.
We allow AI to operate efficiently, becoming the culmination of the efforts of millions of small and large creators, without any single large company controlling every core function.
To achieve this, we will first address the three fundamental issues that hinder the decentralization of RAG:
1. Ownership: Ensuring that app developers, model creators, and data owners can easily and securely publish content to web3 by creating their Web3 "transaction entities" in the form of ERC 3525 semi-fungible tokens, allowing them to prove their digital ownership on-chain.
2. On-chain/Off-chain Connectivity: Ensuring smooth interactions between on-chain and off-chain, providing an open environment for app developers, model creators, and data owners to easily and freely connect with each other.
3. Monetization: Providing a universal framework for recording and accounting for each AI value creator's contributions, as well as automatic revenue sharing and withdrawals.

By implementing decentralized RAG (d/RAG), KIP is drawing the first important blueprint to escape the AI monopoly.
Unlocking digital ownership for every AI value creator allows everyone to transact while maintaining independence, which is precisely the opposite of what large tech companies in web2 are trying to achieve.
The KIP protocol will provide the necessary tools for AI value creators to break free from the AI monopoly.
About KIP Protocol
KIP Protocol builds a Web3 underlying protocol for AI app developers, model creators, and data owners, enabling AI assets to be easily deployed and monetized while retaining full digital ownership.
KIP will establish a new AI business ecosystem to address the challenges and issues faced in decentralized AI deployment, ensuring that everyone can enjoy the economic benefits brought by AI.
The KIP team consists of senior PhDs and technical experts dedicated to AI research since 2019, who also have a strong professional background and rich experience in the Web3 field, committed to promoting AI decentralization and becoming a catalyst for the decentralized AI wave.
For more information, please follow our official account:
 Risk warning Risk warning
Risk warning Risk warning









