
Why is data availability so important for Layer 2?

 What exactly is data availability? What data availability issues does L2 face? Why is there so much controversy surrounding the data availability layer L2?
What exactly is data availability? What data availability issues does L2 face? Why is there so much controversy surrounding the data availability layer L2?Author: Jian Shu
Ethereum Foundation researcher Dankrad Feist once stated in a tweet that not using Ethereum for data availability does not qualify as L2. If we follow his reasoning, many chains would be excluded from the L2 category, such as Arbitrum Nova, Polygon, and Mantle.
So, what exactly is data availability? What data availability issues do L2s face? Why is there so much controversy surrounding data availability layers in L2? This article will focus on these questions and attempt to unveil the mystery of data availability.
What is Data Availability
In simple terms, data availability refers to the stage where block producers publish all transaction data of a block to the network so that validators can download it.
If a block producer publishes complete data and allows validators to download it, we say the data is available; if it conceals some data, preventing validators from downloading the complete data, we say the data is unavailable.
The Difference Between Data Availability and Data Retrievability
Typically, we tend to confuse data availability with data retrievability, but they are quite different.
Data availability pertains to the stage when a block has been produced but has not yet been added to the blockchain through consensus, so data availability is not related to historical data but rather to whether newly published data can be confirmed through consensus.
Data retrievability involves the stage after data has been confirmed through consensus and permanently stored on the blockchain, which is the ability to retrieve historical data. In Ethereum, nodes that store all historical data are called archive nodes.
Therefore, L2 BEAT co-founder once stated in a lengthy tweet that full nodes have no obligation to provide us with historical data; the only reason we can access it is that full nodes are kind enough.
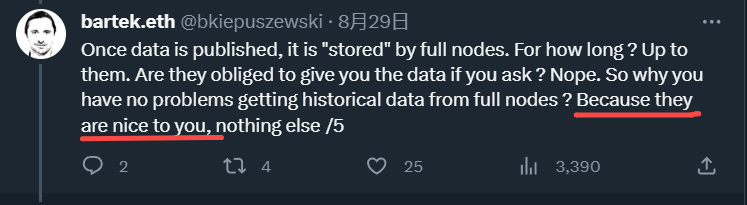
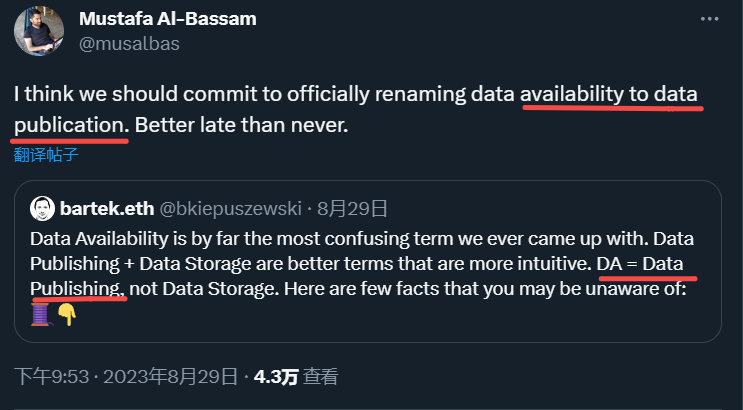
He also mentioned that the term data availability can lead to misunderstandings about its role and should be replaced with data publishing, a sentiment echoed by the founder of Celestia.
Data Availability Issues in L2
Although the concept of data availability originates from Ethereum, our current focus is on data availability at the L2 level.
In L2, sequencers are the block producers who need to publish sufficient transaction data for validators to verify the validity of transactions. (For more information about sequencers, please read the previous article in the Insight Weekly titled “Research Report | The Principles, Current Status, and Future of Sequencers”)
However, there are two issues they face in this process: ensuring the security of the verification mechanism and reducing the cost of data publication. The following will elaborate on these.
Ensuring the Security of the Verification Mechanism
We know that OP Rollup uses fraud proofs to verify transaction validity, while ZK Rollup uses validity proofs.
For OP Rollup: If the sequencer does not publish the complete retrievable data of the block, challengers in the fraud proof will be unable to initiate valid challenges;
For ZK Rollup: Although validity proofs do not require data availability, ZK Rollup as a whole still needs data availability. Without retrievable block data, users will not know their balances and may lose assets.
To ensure secure verification, current L2 sequencers generally publish both L2 state data and transaction data on the more secure Ethereum, relying on Ethereum for settlement and data availability.
Thus, the data availability layer is essentially where L2 publishes transaction data, and currently, mainstream L2s treat Ethereum as the data availability layer.
Reducing the Cost of Data Publication
Today's L2s simply have data availability and settlement occur on Ethereum. While this provides sufficient security, it also incurs significant costs. This is the second issue L2s face: how to reduce the cost of data publication.
The total gas fees paid by users to L2 mainly consist of the gas for executing transactions on L2 and the gas for submitting data to L1. The former is negligible, while the latter constitutes the bulk of user fees, where the transaction data published to ensure data availability accounts for the majority of L2's data submissions to L1, while the proof data for verifying transaction validity constitutes a small portion.

Therefore, to make L2 overall cheaper, the cost of data publication must be reduced. So, how can costs be lowered? There are mainly two methods:
Lowering the cost of publishing data on L1, such as the upcoming EIP-4844 upgrade on Ethereum. For those interested in EIP-4844, you can read the previous article in Insight Weekly titled “Web3 Science Popularization | Easily Understand the Major Benefits of Layer 2: EIP-4844”;
Following the example of Rollup, separating transaction execution from L1, data availability can also be separated from L1 to reduce costs, meaning not using Ethereum as the data availability layer.
Controversies Regarding L2 and Data Availability Layers
To discuss the controversies surrounding L2 and data availability layers, we must start with modular blockchains. Modular blockchains decouple the core functionalities of the overall blockchain into relatively independent parts, expanding the performance of a single blockchain through combinations of various specialized networks.
Although there is some debate regarding the layering of modular blockchains, it is generally accepted to divide modular blockchains into four layers: execution layer, settlement layer, consensus layer, and data availability layer. The functions of each module are illustrated in the following diagram.
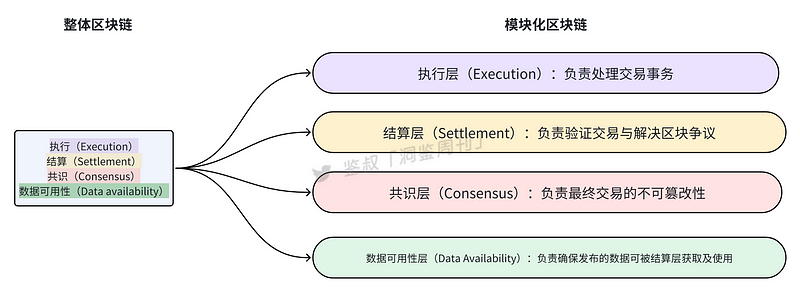
Modular blockchains are similar to Lego blocks, allowing for customization and the use of the best blocks to build a good model, alleviating the "impossible triangle" problem of blockchains.
However, currently, L2s still perform the functions of the other three layers on Ethereum, aside from separating the execution layer. Due to cost considerations, many L2s are also preparing to separate the data availability layer from Ethereum, using Ethereum only as the settlement and consensus layer.
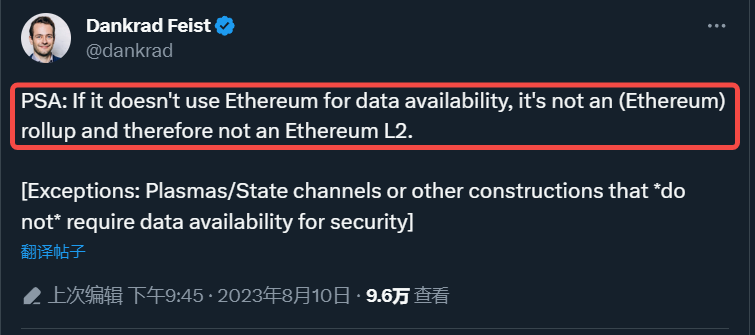
Interestingly, Ethereum seems reluctant to allow L2s to obtain data availability from elsewhere. Ethereum Foundation researcher Dankrad Feist has stated in a tweet that not using Ethereum as a data availability layer does not qualify as a Rollup, and therefore not as L2.
Additionally, in the latest definition of L2 by L2 BEAT, it is pointed out that any scaling solution that does not publish data on L1 is not L2, as using off-chain data availability solutions cannot guarantee that operators will provide the published data.

Of course, there is still no definitive conclusion about what L2 is. The insistence of Ethereum Foundation members and L2 BEAT that L2 should keep the data availability layer on Ethereum seems to stem from security considerations. However, is there a concern about undermining Ethereum's status?
Ethereum's vision is to become a supercomputer platform. Later, to enhance network performance, it had to develop Rollups, causing many ecosystems to migrate to cheaper L2s. However, since security is provided by Ethereum, its status has not been significantly affected. But if L2s also separate the data availability layer related to data publication from Ethereum, it essentially weakens the reliance on Ethereum's security, gradually distancing itself from Ethereum, which poses a threat to Ethereum's status.
Nevertheless, this does not hinder the vigorous development of projects related to data availability layers. In the next article about data availability, I will detail the main data availability solutions available in the market and related projects, so stay tuned.
References:
【1】Ethereum Documentation: Data Availability
【2】Misunderstanding Data Availability: DA = Data Publishing ≠ Historical Data Retrieval
【3】Expelling Validium? A New Perspective on Layer 2 from the Danksharding Proposer
【4】Data Availability Checks
【5】A Note on Data Availability and Erasure Coding
【6】IOSG Ventures: Dissecting the Data Availability Layer, the Overlooked Lego Block in Modular Futures







