Vitalik's latest long article: Should Ethereum encapsulate more features?

 Determining which features should be introduced into the protocol and which should be left to other layers of the ecosystem is a complex trade-off. As our understanding of user needs and the available ideas and technology suites continues to improve, this trade-off is expected to evolve over time.
Determining which features should be introduced into the protocol and which should be left to other layers of the ecosystem is a complex trade-off. As our understanding of user needs and the available ideas and technology suites continues to improve, this trade-off is expected to evolve over time.Original Title: "Should Ethereum be okay with enshrining more things in the protocol?"
Original Author: Vitalik Buterin
Original Compilation: Nian Yin Si Tang, Odailynews
Special thanks to Justin Drake, Tina Zhen, and Yoav Weiss for their feedback and review.
From the beginning of the Ethereum project, there has been a strong philosophy aimed at keeping core Ethereum as simple as possible and achieving this by building protocols on top of it. In the blockchain space, the debate between "building on L1" and "focusing on L2" is often seen as primarily about scalability, but in reality, there are similar issues in meeting the needs of various Ethereum users: digital asset exchange, privacy, usernames, advanced cryptography, account security, anti-censorship, front-running protection, and so on. However, there has been some cautious thinking recently about enshrining more of these features into the core Ethereum protocol.
This article will delve into some of the philosophical reasoning behind the original minimal enshrinement philosophy, as well as some recent thoughts on these ideas. The goal will be to start building a framework to better identify potential targets where enshrining certain features may be worth considering.
Early Philosophy on Protocol Minimalism
In the early history of what was then called "Ethereum 2.0," there was a strong desire to create a clean, simple, and elegant protocol that tried as little as possible to build through itself, leaving almost all such work to users. Ideally, the protocol would just be a virtual machine, and validating a block would simply be a virtual machine call.

The "state transition function" (the function that processes blocks) would just be a single VM call, with all other logic occurring through contracts: some system-level contracts, but mostly user-provided contracts. One very nice feature of this model is that even an entire hard fork could be described as a single transaction for the block processor contract, which would be approved through off-chain or on-chain governance and then run with upgraded permissions.
These discussions in 2015 were particularly relevant to the two areas we are considering: account abstraction and scalability. In the case of scalability, our idea was to try to create a maximally abstract form of scalability, feeling like a natural extension of the chart above. Contracts could call most of the data not stored by Ethereum nodes, the protocol would detect this, and resolve the call through some very general extended computation capabilities. From the perspective of the virtual machine, the call would enter some separate subsystem and then magically return the correct answer after a while.
We briefly explored this line of thinking but quickly abandoned it because we were too focused on verifying that any type of blockchain scalability was possible. However, as we will see later, the combination of data availability sampling and ZK-EVM means that a possible future for Ethereum scalability actually looks very close to this vision! On the other hand, for account abstraction, we knew from the beginning that some form of implementation was possible, so research immediately began to try to make something as close to the pure starting point of "a transaction is just a call" a reality.

A lot of boilerplate code would appear between handling transactions and making the actual underlying EVM calls from the sender's address, and even more boilerplate code would follow. How do we minimize this code as close to zero as possible?
One of the main pieces of code here is validate_transaction(state, tx), which is responsible for checking whether the transaction's nonce and signature are correct. From the very beginning, the actual goal of account abstraction was to allow users to replace the basic non-incremental validation and ECDSA validation with their own validation logic, making it easier for users to utilize features like social recovery and multi-signature wallets. Therefore, finding a way to restructure apply_transaction as a simple EVM call was not merely a task of "cleaning up the code for the sake of cleanliness"; rather, it was about moving logic into the user's account code, providing the flexibility users needed.
However, the practice of insisting that apply_transaction contain as little fixed logic as possible ultimately brought many challenges. We can look at one of the earliest account abstraction proposals, EIP-86.
If EIP-86 were included as is, it would reduce the complexity of the EVM at the cost of significantly increasing the complexity of other parts of the Ethereum stack, requiring essentially the same code to be written elsewhere, not to mention introducing entirely new classes of quirks, such as the same transaction with the same hash appearing multiple times in the chain, let alone the issue of multiple invalidations.

The multiple invalidation issue in account abstraction. A transaction included on-chain could invalidate thousands of other transactions in the memory pool, making it easy for the memory pool to be flooded cheaply.
Since then, account abstraction has evolved in phases. EIP-86 later became EIP-208, which ultimately led to the practical EIP-2938.
However, EIP-2938 is not minimalist at all. Its contents include:
- New transaction types
- Three new global variables for transaction ranges
- Two new opcodes, including the very clunky PAYgas opcode for handling gas price and gas limit checks as EVM execution breakpoints, and temporarily storing ETH to pay fees in one go
- A set of complex mining and relaying strategies, including a list of opcodes prohibited during the transaction validation phase
To implement account abstraction without involving Ethereum core developers (who are focused on optimizing the Ethereum client and implementing the merge), EIP-2938 was ultimately restructured to be entirely protocol-external as ERC-4337.
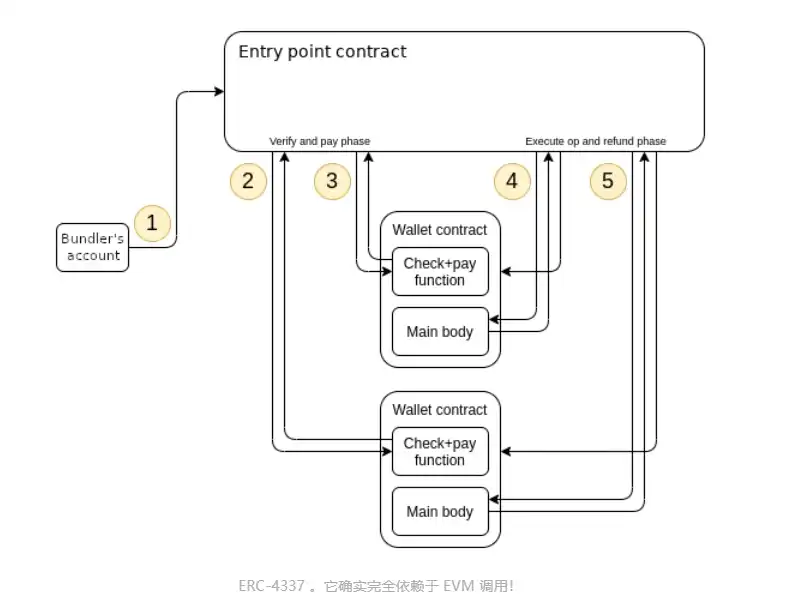
Because this is an ERC, it does not require a hard fork and technically exists "outside the Ethereum protocol." So… has the problem been solved? It turns out not necessarily. The current mid-term roadmap for ERC-4337 actually involves ultimately transforming most of ERC-4337 into a series of protocol features, which serves as a useful guiding example for understanding why this path should be considered.
Enshrining ERC-4337
There are several key reasons to discuss ultimately re-enshrining ERC-4337 into the protocol:
Gas Efficiency: Any operation performed within the EVM incurs a certain degree of virtual machine overhead, including inefficiencies when using gas-expensive features like storage slots. Currently, these additional inefficiencies add up to at least 20,000 gas, if not more. Putting these components into the protocol is the simplest way to eliminate these issues.
Code Bug Risk: If the ERC-4337 "entry point contract" has a sufficiently severe bug, all wallets compatible with ERC-4337 could see their funds drained. Replacing contracts with protocol-internal functionality creates an implicit responsibility to fix code errors through hard forks, thereby eliminating the risk of user funds being drained.
Support for EVM Opcodes, such as tx.origin. ERC-4337 itself makes tx.origin return the address of the "bundler" that packages a set of user operations into a transaction. Native account abstraction could solve this by making tx.origin point to the actual account sending the transaction, making it operate like an EOA.
Anti-Censorship: One of the challenges of proposer/builder separation is that censoring a single transaction becomes easier. In a world where the Ethereum protocol can identify individual transactions, including a list could greatly alleviate this issue, allowing proposers to specify a list of transactions that must be included in the next two slots in almost all cases. However, the protocol-external ERC-4337 encapsulates "user operations" within a single transaction, making user operations opaque to the Ethereum protocol; thus, the inclusion list provided by the Ethereum protocol would not offer censorship resistance for ERC-4337 user operations. Enshrining ERC-4337 and making user operations a "proper" transaction type would solve this issue.
It is worth noting that, in its current form, ERC-4337 is significantly more expensive than "basic" Ethereum transactions: a transaction costs 21,000 gas, while ERC-4337 costs about 42,000 gas.
In theory, it should be possible to adjust the EVM gas cost system until the costs of protocol-internal and protocol-external access to storage match; when other types of storage editing operations are cheaper, there is no reason for transferring ETH to cost 9,000 gas. In fact, two EIPs related to the upcoming Verkle tree conversion are actually trying to achieve this. However, even if we do this, there is an obvious reason why, no matter how efficient the EVM becomes, enshrined protocol functionality will inevitably be much cheaper than EVM code: encapsulated code does not need to pay gas for preloading.
A fully functional ERC-4337 wallet is large, and compiling and putting this implementation on-chain takes up about 12,800 bytes. Of course, you could deploy this code once and use DELEGATECALL to allow each individual wallet to call it, but it still requires accessing that code in every block it is used. Under the Verkle tree gas cost EIP, 12,800 bytes would consist of 413 chunks, and accessing these chunks would require paying twice the witness branchcost (totaling 3,800 gas) and 413 times the witness chunkcost (totaling 82,600 gas). This does not even begin to mention the ERC-4337 entry point itself, which, in version 0.6.0, has 23,689 bytes on-chain (which, according to Verkle tree EIP rules, requires about 158,700 gas to load).
This leads to a problem: the actual gas cost of accessing this code must somehow be shared among transactions. The current method used by ERC-4337 is not great: the first transaction in the bundle incurs a one-time storage/code read cost, making it much more expensive than other transactions. Enshrining these public shared libraries as part of the protocol would allow everyone to access them for free.
What Can We Learn from This Example, and When Should We Enshrine More Generally?
In this example, we see some different fundamental principles regarding the enshrinement of account abstraction in the protocol.
When fixed costs are high, a market-based approach of "pushing complexity to the edge" is most likely to fail. In fact, the long-term account abstraction roadmap looks like it has a lot of fixed costs per block. 244,100 gas to load standardized wallet code is one thing; however, aggregation could add hundreds of thousands of gas for ZK-SNARK verification, along with the on-chain costs of proof verification. There is no way to charge users for these costs without introducing a lot of market inefficiencies, and transforming some of these functionalities into protocol features that everyone can access for free could solve this problem well.
Community-wide responses to code bugs. If some code snippets are used by all users or a very broad set of users, it often makes more sense for the blockchain community to bear the responsibility of hard forking to fix any bugs that arise. ERC-4337 introduces a lot of globally shared code, and in the long run, fixing bugs in the code through hard forks is undoubtedly more reasonable than causing users to lose large amounts of ETH.
Sometimes, a stronger form can be achieved by directly leveraging the protocol's functionality. A key example here is the anti-censorship functionality within the protocol, such as inclusion lists: inclusion lists within the protocol can better guarantee censorship resistance than protocol-external methods. For user-level operations to truly benefit from inclusion lists within the protocol, individual user-level operations need to be "readable" by the protocol. Another lesser-known example is that the proof-of-stake design from the Ethereum era of 2017 abstracted account keys, which was abandoned in favor of encapsulating BLS, as BLS supports an "aggregation" mechanism that must be implemented at both the protocol and network levels, making it more efficient to handle large numbers of signatures.
But it is important to remember that even encapsulating account abstraction within the protocol represents a significant "de-encapsulation" compared to the status quo. Today, top Ethereum transactions can only be initiated from externally owned accounts (EOAs), which are verified using a single secp 256 k 1 elliptic curve signature. Account abstraction eliminates this and leaves the verification conditions to be defined by users themselves. Therefore, in this story about account abstraction, we also see the strongest argument against enshrinement: the flexibility to meet the needs of different users.
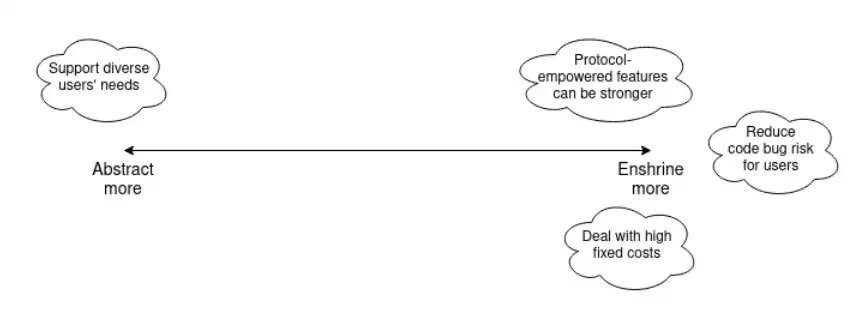
Let us further enrich this story by looking at several other features that have recently been considered for enshrinement. We will particularly focus on: ZK-EVM, proposer-builder separation, private memory pools, liquid staking, and new precompiles.
Enshrining ZK-EVM
Let’s shift our attention to another potential enshrinement target within the Ethereum protocol: ZK-EVM. Currently, we have a large number of ZK-rollups, all of which must write fairly similar code to verify the execution of Ethereum blocks in ZK-SNARKs. There is a fairly diverse ecosystem of independent implementations: PSE ZK-EVM, Kakarot, Polygon ZK-EVM, Linea, Zeth, and so on.
A recent controversy in the EVM ZK-rollup space concerns how to handle bugs that may arise in ZK code. Currently, all of these running systems have some form of "safety council" mechanism to control the proof system in the event of a bug. Last year, I attempted to create a standardized framework to encourage projects to clarify their level of trust in the proof system and the safety council, gradually reducing the power of that organization over time.
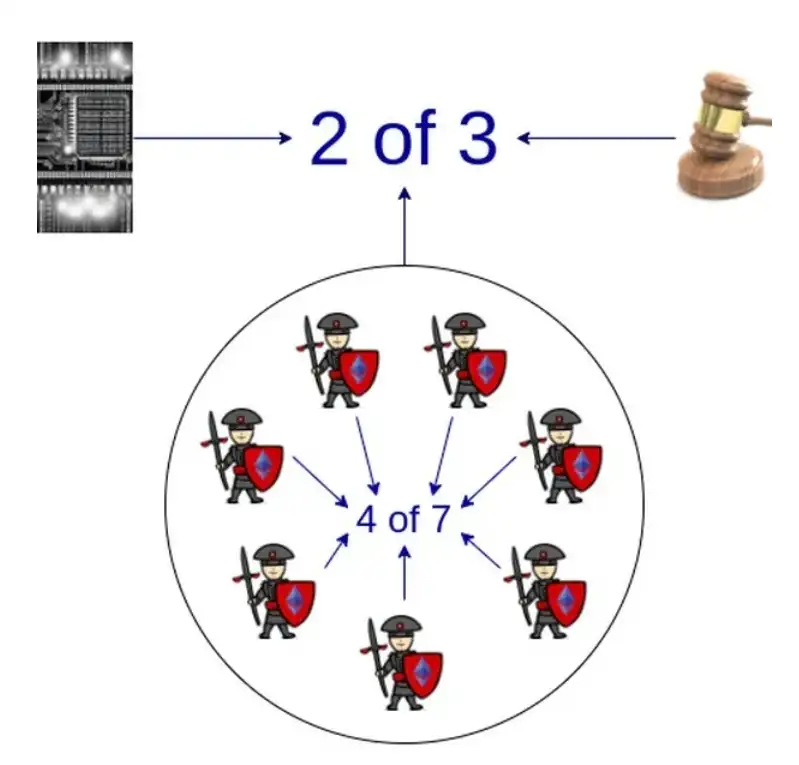
In the medium term, rollups may rely on multiple proof systems, with the safety council only having power in extreme cases where two different proof systems diverge.
However, there is a sense that some of this work feels redundant. We already have the Ethereum base layer, which has an EVM, and we already have a working mechanism for handling bugs in implementations: if there is a bug, the client will update to fix it, and then the chain continues to operate. From the perspective of a buggy client, it seems that blocks that have been confirmed will no longer be confirmed, but at least we won’t see users losing funds. Similarly, if a rollup just wants to maintain equivalence with the EVM, then they need to implement their own governance to constantly change their internal ZK-EVM rules to match upgrades to the Ethereum base layer, which feels wrong because ultimately they are building on top of the Ethereum base layer itself, which knows when to upgrade and under what new rules.
Since these L2 ZK-EVMs essentially use the same EVM as Ethereum, could we somehow incorporate "verifying EVM execution in ZK" into protocol functionality and handle exceptional cases, such as bugs and upgrades, through Ethereum's social consensus, just as we have done for the base layer EVM execution itself?
This is an important and challenging topic.
One possible argument regarding data availability in native ZK-EVM is statefulness. If ZK-EVMs do not need to carry "witness" data, their data efficiency would be much higher. That is, if a particular piece of data has already been read or written in a previous block, we can simply assume that the prover can access it and does not need to make it available again. This is not just about not reloading storage and code; it turns out that if a rollup compresses data correctly, stateful compression can save up to 3 times the data compared to stateless compression.
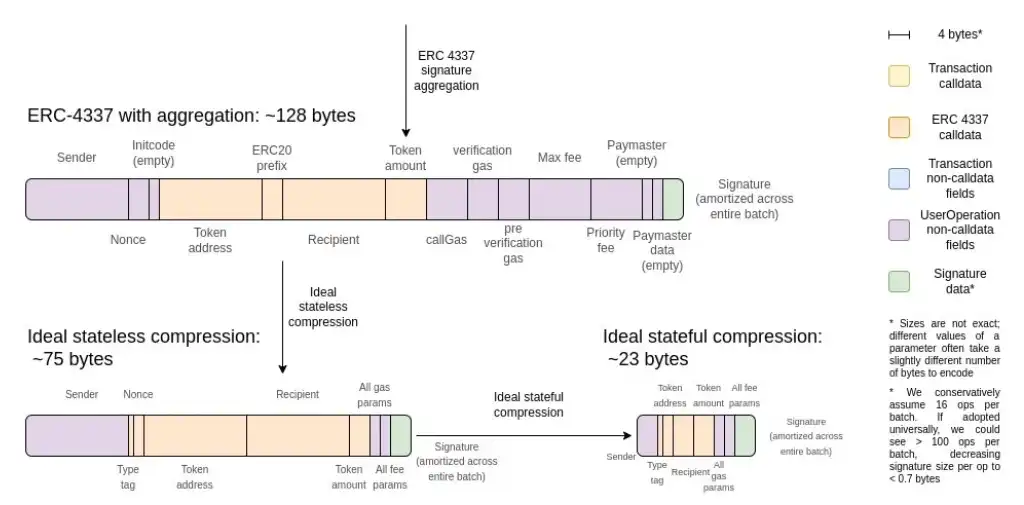
This means that for ZK-EVM precompiles, we have two options:
1. Precompiles require all data to be available in the same block. This means the prover can be stateless, but it also means that using this precompile would be much more expensive for ZK-rollups than using custom code.
2. Precompiles allow pointers to previously used or generated data. This brings ZK-rollups closer to optimality, but it is more complex and introduces a new state that must be stored by the prover.
What can we learn from this? There is a good reason to encapsulate ZK-EVM verification: rollups are already building their own custom versions, and it feels wrong for Ethereum to place the weight of its multiple implementations and off-chain social consensus on L1 to execute the EVM, while L2s doing the exact same work must implement complex gadgets involving safety councils. But on the other hand, there is a big problem in the details: there are different versions of ZK-EVMs with varying costs and benefits. The distinction between stateful and stateless is just scratching the surface; trying to support "almost-EVM" custom code that has already been proven by other systems could expose a larger design space. Therefore, enshrining ZK-EVM brings both hope and challenges.
Enshrining Proposer-Builder Separation (ePBS)
The rise of MEV has turned block production into a large-scale economic activity, with complex participants able to produce blocks that generate more revenue than those produced by the default algorithm, which simply observes the transaction memory pool and includes them. So far, the Ethereum community has tried to address this issue through protocol-external proposer-builder separation schemes like MEV-Boost, which allow regular validators ("proposers") to outsource block construction to specialized participants ("builders").
However, MEV-Boost introduces a trust assumption in a new category of participants called relays. Over the past two years, many have proposed creating "encapsulated PBS." What are the benefits of doing this? In this case, the answer is very simple: PBS built using protocol functionality is stronger than PBS built without it (in the sense of having weaker trust assumptions). This is similar to the case of encapsulating price oracles within the protocol—although in this case, there are also strong objections.
Enshrining Private Memory Pools
When users send transactions, those transactions are immediately public and visible to everyone, even before they are included on-chain. This makes users of many applications vulnerable to economic attacks, such as front-running.
Recently, many projects have been dedicated to creating "private memory pools" (or "encrypted memory pools") that encrypt users' transactions until they are irreversibly accepted into a block.
However, the problem is that such schemes require a special form of encryption: to prevent users from flooding the system and front-running the decryption, the encryption must automatically decrypt after the transaction has indeed been irreversibly accepted.
To achieve this form of encryption, there are various technical trade-offs. Jon Charbonneau has described this well:
- Encryption for centralized operators, such as Flashbots Protect.
- Time-lock encryption, which can be decrypted by anyone after a certain sequence of computational steps and cannot be parallelized.
- Threshold encryption, trusting a honest majority committee to decrypt the data. Specific proposals can be found in the closed beacon chain concept.
- Trusted hardware, such as SGX.
Unfortunately, each of these encryption methods has different weaknesses. While there is a portion of users willing to trust each solution, none of the solutions have a level of trust sufficient for them to be actually accepted by Layer 1. Therefore, at least until delayed encryption is perfected or some other technological breakthrough occurs, encapsulating anti-front-running functionality in Layer 1 seems to be a difficult proposition, even if it is a sufficiently valuable feature that many application solutions have emerged.
Enshrining Liquid Staking
A common need among Ethereum DeFi users is the ability to use their ETH for staking while also using it as collateral in other applications. Another common need is simply convenience: users want to stake without the complexity of running a node and keeping it online all the time (and protecting their online staking keys).
So far, the simplest staking "interface" that meets both needs is simply an ERC 20 token: convert your ETH into "staked ETH," hold it, and then convert it back. In fact, liquid staking providers like Lido and Rocket Pool have already started doing this. However, liquid staking has some natural centralization mechanisms at play: people naturally gravitate toward the largest version of staked ETH because it is the most familiar and liquid.
Each version of staked ETH needs to have some mechanism to determine who can become the underlying node operator. It cannot be unrestricted, as attackers would join and exploit users' funds to amplify their attacks. Currently, the top two are Lido and Rocket Pool, with the former having DAO whitelisted node operators and the latter allowing anyone to run a node with a deposit of 8 ETH. These two approaches have different risks: the Rocket Pool method allows attackers to perform a 51% attack on the network and force users to bear most of the costs; as for the DAO method, if a particular staking token dominates, it could lead to a single, potentially attackable governance gadget controlling a large portion of all Ethereum validators. It is certain that protocols like Lido have implemented safeguards, but one layer of defense may not be enough.
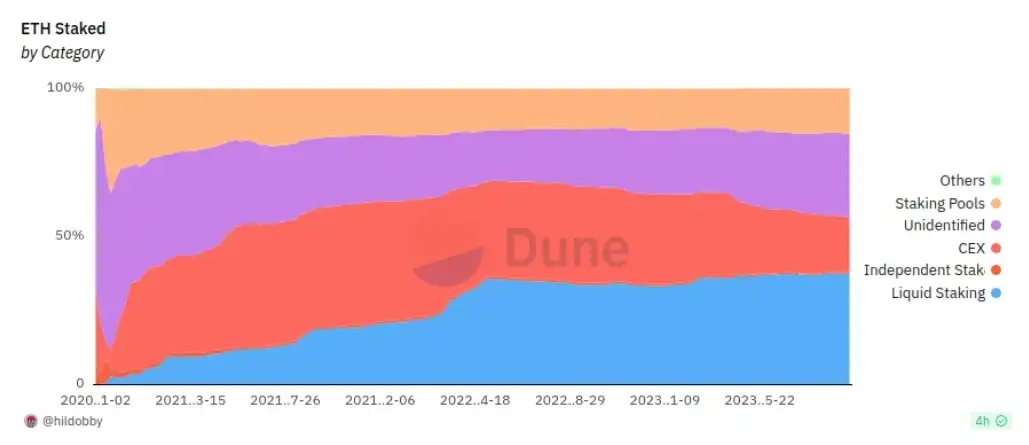
In the short term, one option is to encourage ecosystem participants to use diverse liquid staking providers to reduce the systemic risk posed by a single dominant player. However, in the long term, this is an unstable balance, and over-relying on moral pressure to solve the problem is dangerous. A natural question arises: does it make sense to encapsulate some functionality in the protocol to make liquid staking less centralized?
The key question here is: what kind of protocol-internal functionality? Simply creating a protocol-internal alternative "staked ETH" token has a problem: it either must have an encapsulated Ethereum-wide governance to choose who runs the nodes, or it must be open, which would turn it into a tool for attackers.
An interesting idea is Dankrad Feist's article on maximizing liquid staking. First, we grit our teeth and accept that if Ethereum suffers a 51% attack, only about 5% of the attacking ETH would be slashed. This is a reasonable trade-off; currently, over 26 million ETH are staked, with one-third (about 8 million ETH) being an excessive attack cost, especially considering how many "off-model" attacks could be executed at a lower cost. In fact, similar trade-offs have been discussed in the "super committee" proposal regarding the implementation of single-slot finality.
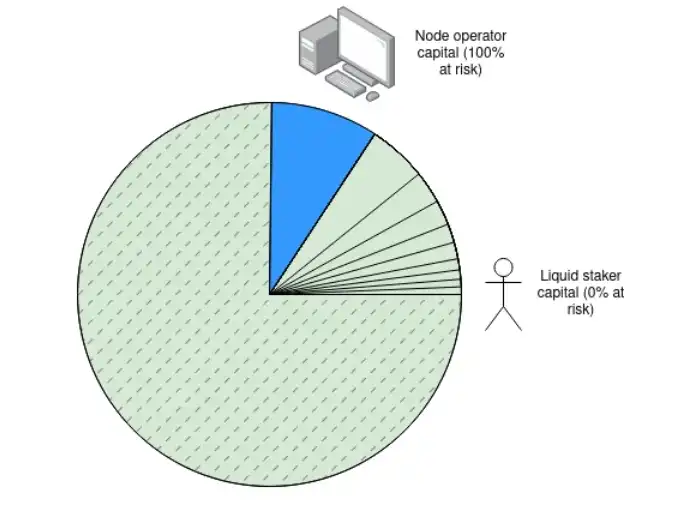
If we accept that only 5% of the attacking ETH would be slashed, then over 90% of staked ETH would not be affected by slashing, allowing them to serve as protocol-internal alternative liquid staking tokens that could then be used by other applications.
This path is intriguing. But it still leaves a question: what specifically should be encapsulated? The way Rocket Pool operates is very similar: each node operator provides some funds, while liquid stakers provide the rest. We could simply adjust some constants to limit the maximum slashing penalty to 2 ETH, making Rocket Pool's existing rETH risk-free.
With simple protocol adjustments, we could also do other clever things. For example, suppose we want a system with two "layers" of staking: node operators (high collateral requirements) and depositors (no minimum collateral requirements, able to join and leave at any time), but we still want to prevent centralization of node operators by empowering a randomly sampled depositor committee to suggest a list of transactions that must be included (for anti-censorship reasons), control fork selection during inactivity leakage, or require signatures on blocks. This could be achieved in a way that is essentially detached from the protocol by adjusting the protocol to require each validator to provide (i) a regular staking key, and (ii) an ETH address that can be called in each slot to output a secondary staking key. The protocol would empower these two keys, but the mechanism for selecting the second key in each slot could be left to the staking pool protocol. Directly encapsulating some functionality might still be better, but it is worth noting that this design space of "including some things and leaving others to users" exists.
Enshrining More Precompiles
Precompiles (or "precompiled contracts") are Ethereum contracts that implement complex cryptographic operations, with their logic natively implemented in client code rather than EVM smart contract code. Precompilation was a compromise adopted at the beginning of Ethereum development: since the overhead of the virtual machine was too great for certain very complex and highly specialized code, we could implement some key operations valuable to important applications in native code to make them faster. Today, this essentially includes some specific hashing functions and elliptic curve operations.
Currently, there are pushes to add precompiles for secp 256 r 1, which is a slightly different elliptic curve than the secp 256 k 1 used for basic Ethereum accounts, as it has good support from trusted hardware modules, and widespread use of it could enhance wallet security. In recent years, the community has also pushed to add precompiles for BLS-12-377, BW 6-761, generalized pairing, and other functionalities.
The counterargument to these demands for more precompiles is that many of the previously added precompiles (such as RIPEMD and BLAKE) ended up being used far less than expected, and we should learn from this. Instead of adding more precompiles for specific operations, we might focus on a more moderate approach based on ideas like EVM-MAX and dormant but always recoverable SIMD proposals, which would enable EVM implementations to execute a wider class of code at lower costs. Perhaps even the existing rarely used precompiles could be removed and replaced with EVM code implementing the same functions (inevitably less efficiently). That said, there may still be specific cryptographic operations whose value is sufficient to warrant acceleration, making it sensible to add them as precompiles.
What Have We Learned from All This?
The desire to encapsulate as little as possible is understandable and good; it stems from the Unix philosophy of creating minimal software that can easily adapt to users' different needs, avoiding the curse of software bloat. However, blockchains are not personal computing operating systems; they are social systems. This means that encapsulating certain functionalities within the protocol makes sense.
In many cases, these other examples are similar to what we see in account abstraction. But we have also learned some new lessons:
Encapsulating functionality can help avoid centralization risks in other areas of the stack:
Generally, keeping the core protocol minimal and simple pushes complexity to some ecosystem outside the protocol. From the perspective of the Unix philosophy, this is good. However, sometimes there are centralization risks in the protocol-external ecosystem, often (but not exclusively) due to high fixed costs. Encapsulation can sometimes reduce de facto centralization.
Encapsulating too much may overextend the trust and governance burden of the protocol:
This is the theme of the previous article on "not overloading Ethereum consensus": if encapsulating a specific functionality weakens the trust model and makes Ethereum as a whole more "subjective," it undermines Ethereum's credible neutrality. In these cases, it is better to treat specific functionalities as mechanisms above Ethereum rather than trying to bring them into Ethereum itself. Here, encrypted memory pools are the best example; they may be somewhat difficult to encapsulate, at least until delayed encryption technologies improve.
Encapsulating too much may make the protocol overly complex:
Protocol complexity is a systemic risk, and adding too many functionalities to the protocol increases this risk. Precompiles are the best example.
In the long run, encapsulating functionalities may backfire because user needs are unpredictable:
A functionality that many people think is important and will be used by many users may not actually be frequently used in practice.
Moreover, the cases of liquid staking, ZK-EVM, and precompiles show a possible middle ground: minimal viable enshrinement. The protocol does not need to encapsulate an entire functionality but can include specific parts that address key challenges, making that functionality easier to implement without being overly paranoid or too narrow. Such examples include:
Instead of encapsulating a complete liquid staking system, changing the staking penalty rules to make trustless liquid staking more feasible;
Instead of encapsulating more precompiles, encapsulating EVM-MAX and/or SIMD to make a broader class of operations easier to implement effectively;
Simply encapsulating EVM verification rather than encapsulating the entire concept of rollups.
We can extend the previous chart as follows:
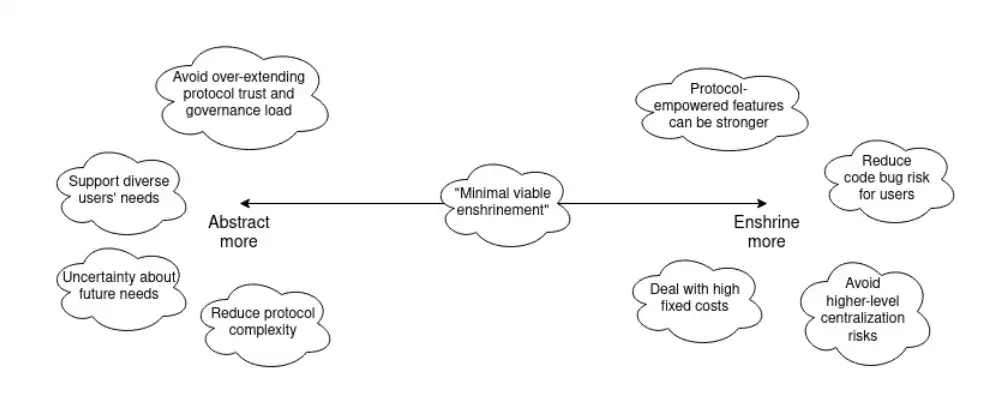
Sometimes, it makes sense to de-encapsulate something, and removing rarely used precompiles is one example. Account abstraction as a whole, as mentioned earlier, is also an important form of de-encapsulation. If we want to support backward compatibility for existing users, then that mechanism may actually be surprisingly similar to the mechanism of de-encapsulating precompiles: one of the proposals is EIP-5003, which would allow EOAs to convert their accounts into contracts with the same (or better) functionality.
Which functionalities should be introduced into the protocol, and which should be left to other layers of the ecosystem, is a complex trade-off. As our understanding of user needs and the available ideas and technological toolkit continues to improve, this trade-off is expected to evolve over time.