
Unveiling Unknown Types of MEV Activities in Ethereum Transaction Bundles

 How to identify unknown MEV activities through workflows?
How to identify unknown MEV activities through workflows?Guest: Zihao Li, PhD student at The Hong Kong Polytechnic University
Organizer: aididiao.eth, Foresight News
This article is a transcription of the video sharing by Zihao Li, a PhD student at The Hong Kong Polytechnic University, as part of the Web3 Young Scholars Program. The Web3 Young Scholars Program is jointly initiated by DRK Lab, imToken, and Crytape, inviting renowned young scholars in the crypto field to share some of the latest research findings with the Chinese-speaking community.
Hello everyone, I am Zihao Li, a third-year PhD student at The Hong Kong Polytechnic University. The topic I will share today is "Unveiling MEV Activities in Ethereum Transaction Bundles." In simple terms, it is about how to discover unknown types of MEV activities in the Ethereum network through transaction bundles. First, I will provide a basic background introduction, such as the concept of MEV, the transaction bundle mechanism, and the background of our work. Then, I will detail the complete workflow and some design ideas, such as the design principles we based our workflow on, what our dataset includes, and what tools we used to evaluate our workflow on various metrics. Finally, I will introduce three applications along with the relevant empirical analysis results.
Background Introduction: MEV, Transaction Bundles, Motivation

MEV activities refer to arbitrageurs in the blockchain generating arbitrage trades by monitoring the blockchain network, including block states. Some transaction information is propagated over the blockchain P2P network, or stored in the transaction pools of miners or validators, which contain transactions that have not yet been officially on-chain. When arbitrageurs listen to this transaction information, they generate their own arbitrage trades through certain strategies and specify those trades to be executed at a certain position in the next block, such as at the head of the next block or immediately following a specific transaction to propagate the same arbitrage trade. This specification of a position for arbitrage activities can be considered as MEV activities. For example, if an arbitrageur monitors a price fluctuation of an asset, they can buy the corresponding asset in a low-priced transaction pool and then sell it at a higher price in another pool, which we consider as an MEV activity.
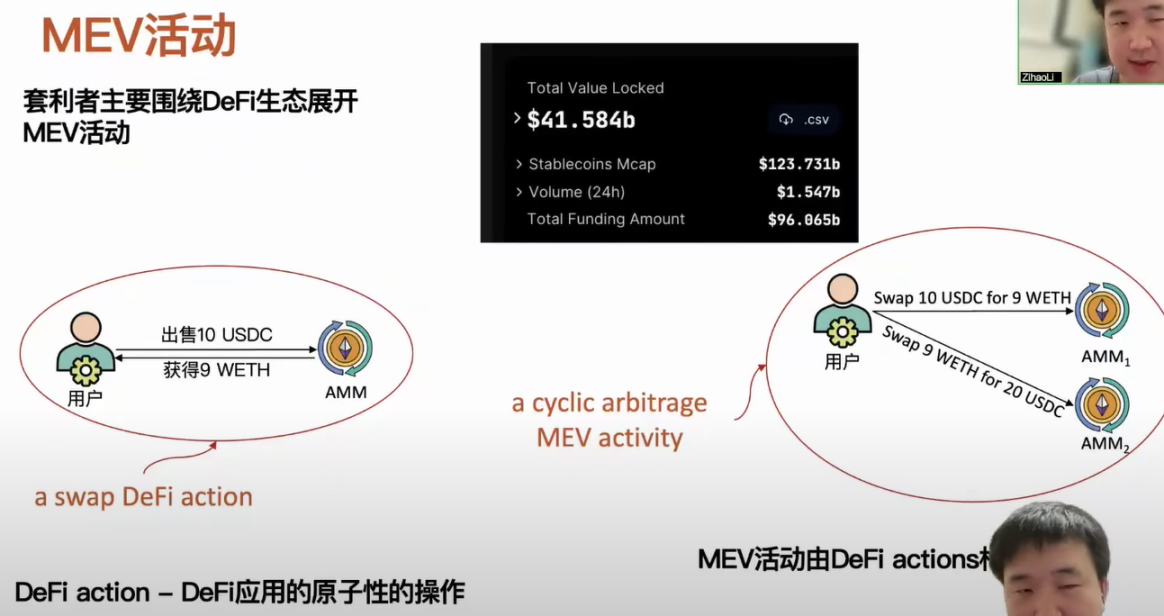
Currently, MEV activities are mainly carried out by arbitrageurs within the DeFi ecosystem, as the DeFi ecosystem primarily gathers assets. To date, the DeFi ecosystem on Ethereum and other chains has attracted over $40 billion in funds. Here, it is important to mention a concept related to the DeFi ecosystem, known as DeFi action, which corresponds to atomic service operations provided by a DeFi application. For example, we know that AMMs support exchanges between different types of assets; a user can sell a certain amount of USDC and receive ETH in return. This operation can be defined as a DeFi action. We can represent MEV activities using DeFi actions. For instance, if a user monitors price discrepancies across different AMMs, they can buy low and sell high to ultimately gain profit from the price difference. We can represent this MEV activity as two DeFi actions.
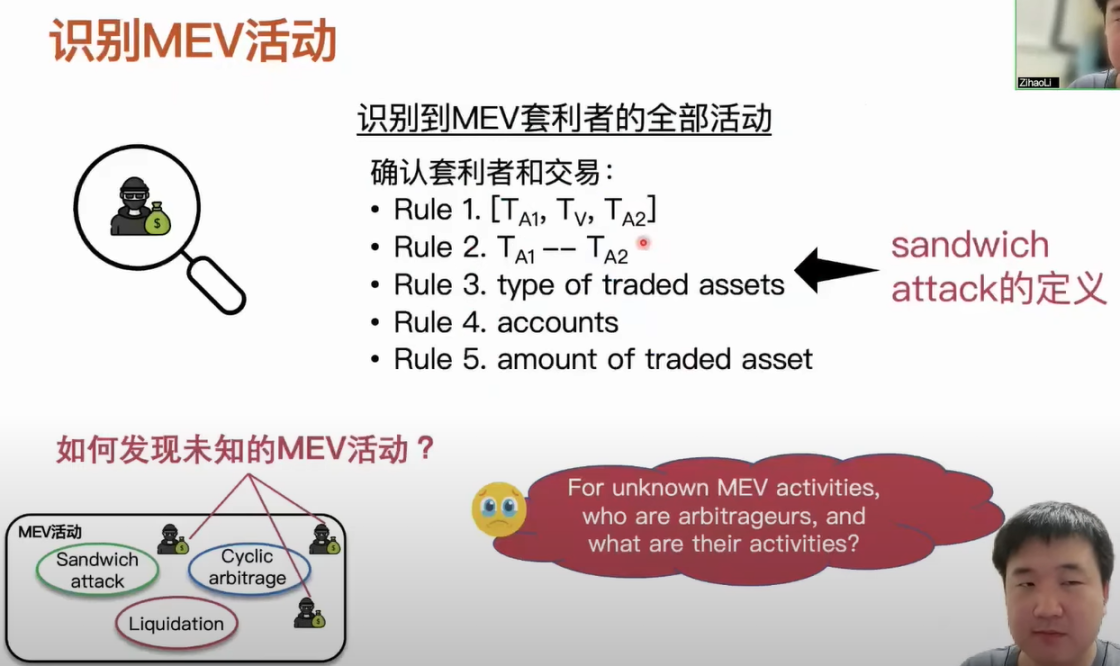
Currently, academic research on MEV activities mainly falls into three categories: sandwich attacks, reverse arbitrage, and liquidation. In our dataset, we found that these three types of MEV activities occurred over a million times. There is actually a question here: after we know the definitions of these MEV activities, how do we identify their occurrence? If we want to identify these MEV activities, we need to recognize all activities of arbitrageurs, such as what trades they generate and what types of arbitrage are involved in those trades, so that we can determine which type of MEV activity is currently occurring. The entire process heavily relies on our definitions of known MEV activities. Taking sandwich attacks as an example, after we know the definition of a sandwich attack, to determine the arbitrage value of a sandwich attack and its corresponding arbitrage trades, we need to set many rules based on the definition and then filter out candidate arbitrage values and trades for sandwich attacks using these rules. When identifying known types of MEV attacks in this way, two problems arise: the first is whether the three known types of MEV activities can represent all MEV activities. Clearly, they cannot, as the DeFi ecosystem is continuously evolving, new applications are being developed, and the strategies of these arbitrageurs are also iterating. The second question is how we can discover these unknown MEV activities. We approach this question by looking at the transaction bundle mechanism.

The transaction bundle mechanism was first proposed in 2021. In simple terms, it allows users to organize a queue of transactions, which can consist of a single transaction or multiple transactions. Users send these transactions to relayers in the blockchain network, which collect the transactions and privately send them to the relevant miners or validators. Currently, relayers run transaction bundles to undertake relaying tasks. A very important feature of the transaction bundle mechanism is that when users construct transaction bundles, they can include transactions that have not yet been on-chain, and the order of transactions within the bundle can be manipulated arbitrarily. At this point, users of the transaction bundle, or arbitrageurs using the transaction bundle, can design their own arbitrage rules. For example, they can design more complex and more profitable MEV activity strategies. In the case of a sandwich attack, if a sandwich attack arbitrageur does not use a transaction bundle, they need to generate at least one pair of trades to achieve arbitrage, and this pair of arbitrage trades can only target a specific transaction. The attack trades must be executed in a certain order to ensure successful arbitrage. However, if an arbitrageur uses a transaction bundle, they can collect many trades that can be arbitraged, and only need one pair of corresponding arbitrage trades to simultaneously arbitrage multiple trades. As long as this transaction bundle is on-chain, it will definitely succeed in arbitrage, and because it arbitrages multiple trades at once, the arbitrage result will also yield greater profits.

The characteristics of transaction bundles lead to very rich and complex MEV activities. Because users who use transaction bundles encapsulate their complete transactions within the bundle and send them to the P2P network's relayers, which then send them to the relevant miners and validators, we can accurately and completely identify all activities through transaction bundles. Therefore, we can use transaction bundles as a medium to accurately identify some unknown MEV activities.
Workflow and Design Ideas
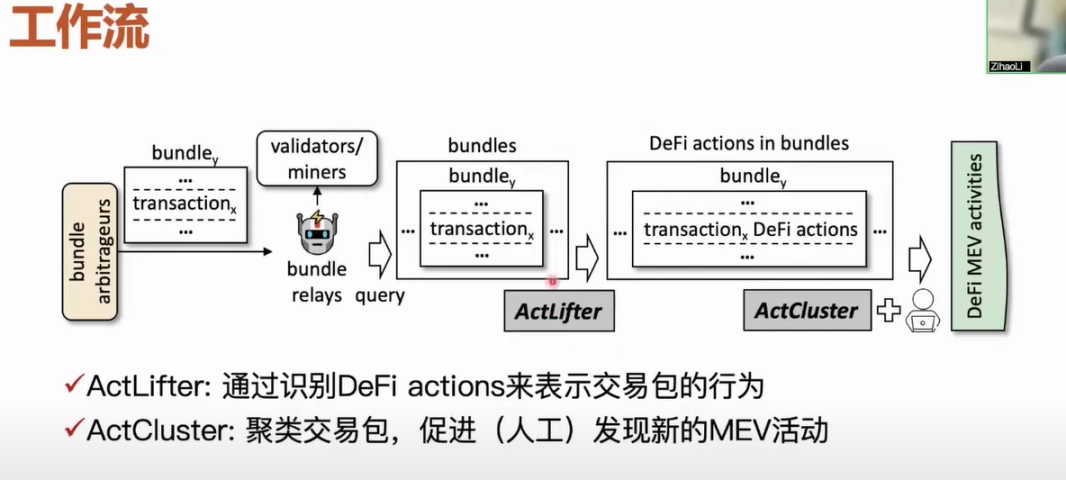
Next, I will specifically introduce our workflow. How do we discover unknown MEV activities through the medium of transaction bundles? The core workflow includes two tools. First, after the relayer collects the transaction bundles, we use the ActLifter tool to identify each DeFi action within the transaction bundle. After obtaining the results, we represent all actions within the transaction bundle. Then, we use the ActCluster tool to cluster transaction bundles with similar activities together, allowing us to discover new MEV activities more quickly. If we want to discover unknown MEV activities, we inevitably need manual confirmation to determine whether the MEV activity is of an unknown type. Of course, our workflow is designed to minimize manual workload as much as possible and to automate the entire process.
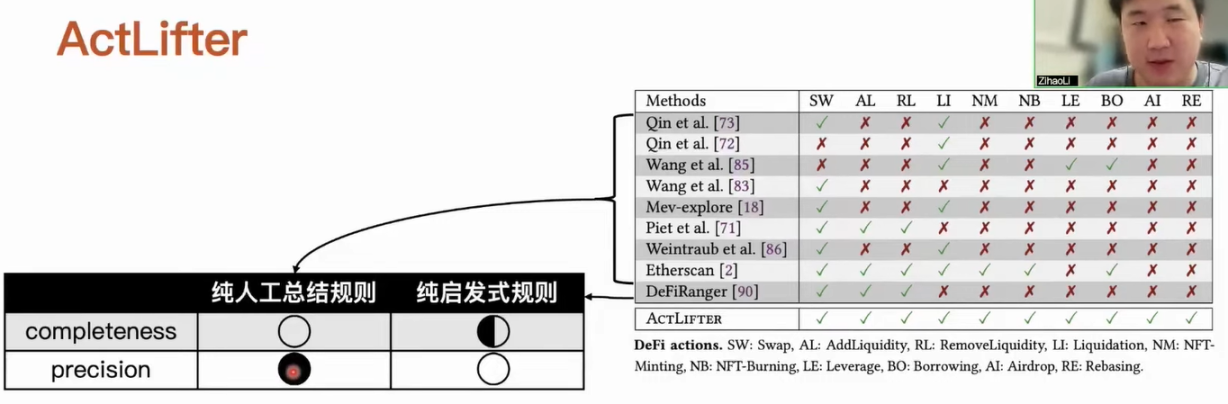
Currently, there are some tools that can identify MEV activities from transactions. We can roughly divide them into two categories: the first category is purely manual rule summarization; the second category is purely heuristic rules, which use a fully automated heuristic approach to identify specific types of MEV activities. For example, it checks whether certain transfer information meets heuristic rules after identifying it, and if it does, it can recognize the corresponding activity. The first method of purely manual rule summarization can achieve relatively good accuracy because this process involves completely manual analysis of specific applications, ensuring that the detection results are accurate. However, the analysis task requires a very large workload, so it cannot cover all DeFi applications. The second method, while fully automated, can only cover certain specific types. On the other hand, heuristic rules have some design issues that lead to unsatisfactory recognition accuracy.
We designed our workflow by integrating the advantages of both methods. We can identify ten currently major DeFi actions. We only need to manually determine which event in the DeFi application corresponds to which type of DeFi action, and then we can completely rely on automated analysis without further manual analysis. The second method can fully automate the identification of DeFi actions, but it cannot determine whether the analyzed object is related to MEV activities. For example, if we identify a SWAP transfer, it may incorrectly combine two completely unrelated transfers into one DeFi action, resulting in an inaccurate recognition outcome. However, we can use this information to filter out the information that is truly related to DeFi actions. After obtaining this information, we can use automated methods to avoid some errors that occur in the second method.
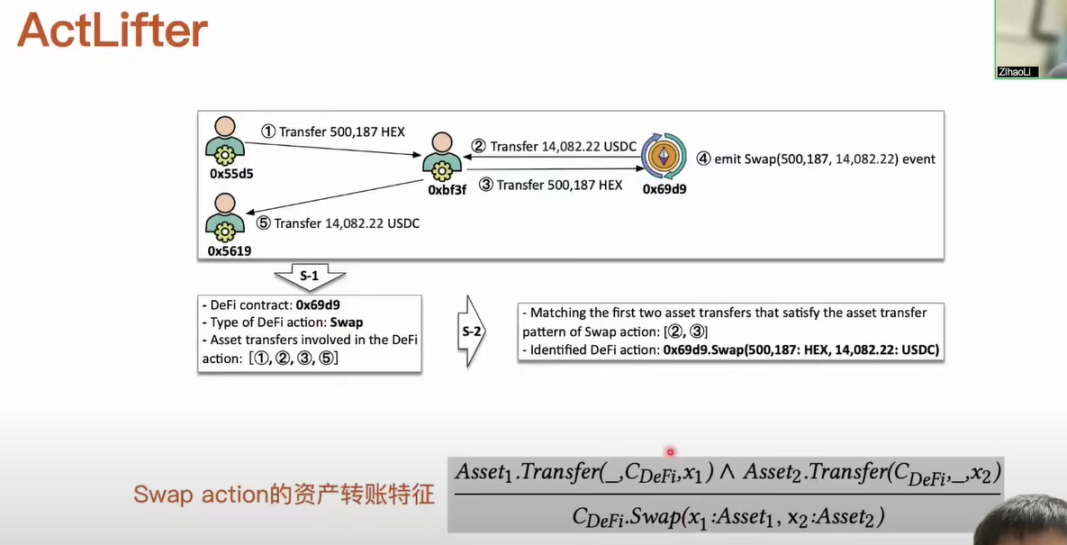
For example, here is a transaction that involves four transfers, with their occurrence order, fund amounts, and categories marked with numbers. In this process, the AMM actually initiated an event related to the Swap action. The first method, upon determining that this event was initiated, needs to use some parameters of the event to recover the current content. For example, it needs to look at the code of the 699 contract, its business logic, and some function variables to recover the current content. After obtaining this information, we designed a rule based on its unique asset transfer characteristics. For instance, our extracted rule states that the current DeFi contract is receiving and transferring different types of assets. When we find that two such asset transfers meet this characteristic, we can recover the corresponding Swap action content. The second method directly matches two asset transfers, assuming that the accounts involved in the first and fifth transfers are receiving and transferring different types of assets. It would incorrectly consider these two transfers as related and assume that the intermediate account is an AMM, which clearly shows that the recognition result is inaccurate.
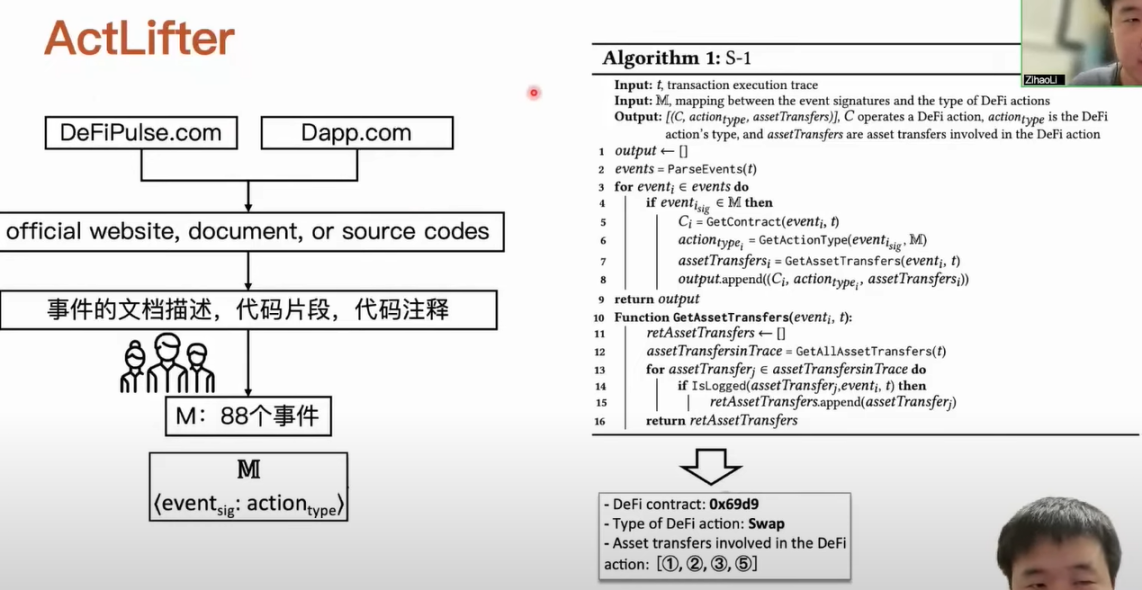
The rules we summarized through manual analysis are related to the types of DeFi actions corresponding to relevant events. Although the results are derived from manual analysis, we still strive to refine the manual analysis process into a semi-automated process to ensure the reliability of the entire process. We will query the official websites of DeFi applications, developer documentation, and some contract source codes from DeFiPulse.com and Dapp.com. Our developed parsing tool can extract descriptions of events from these materials, such as how the event is defined with tokens and in which functions the event is used, along with code snippets and comments. After extracting this information, we manually analyze and discuss it, ultimately determining that there are 88 events corresponding to different types of DeFi actions.
We input the transactions to be analyzed into this dictionary and parse which events occurred in the transactions. When an event appears in this dictionary, we extract key information based on the corresponding rules, such as which contract is operating this DeFi action, what the type of DeFi is, and which asset transfers are related to this DeFi action. After obtaining such content, we summarize the characteristic rules of asset transfers and use these rules to match the final DeFi action. Starting from the definitions of ten DeFi actions, we summarized the characteristic rules of asset transfers. After collecting this information in the previous step, we will use these matching rules to help us identify which specific DeFi actions occurred in the transaction. After ActCluster identifies each transaction in the transaction bundle, we can represent the actions of the transaction bundle.
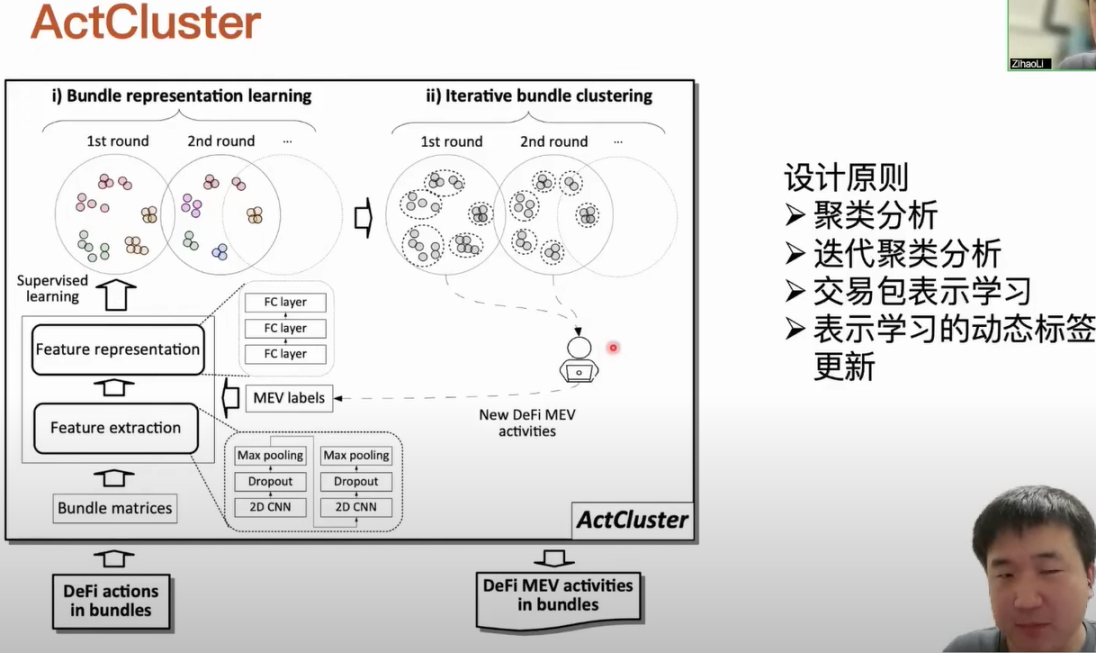
First, let's understand the design principles of ActCluster. We know that manual analysis is unavoidable in this process; it must rely on human input to determine whether the activities in the transaction bundle are unknown types of MEV activities. Based on this, our basic idea is to cluster transaction bundles with similar activities together. For each cluster, we only need to randomly sample one or a few transaction bundles for analysis, which can accelerate the manual analysis process and ultimately discover different types of MEV activities. When we perform clustering analysis on transaction bundles, we face a dilemma. If we set the clustering strength relatively coarse, transaction bundles containing different types of activities will be grouped together. Although this reduces the number of clusters and the corresponding manual analysis tasks, some new MEV activities may be overlooked. Conversely, if we set the clustering strength relatively fine, we can distinguish between similar but different MEV activities corresponding to transaction bundles, but the workload for manual analysis significantly increases.
To address this issue, we designed an iterative clustering analysis method that performs clustering analysis in multiple rounds. In each round, we exclude transaction bundles that contain known new MEV activities discovered in previous rounds and then increase the clustering strength for the remaining transaction bundles. We cannot directly use traditional clustering methods to cluster transaction bundles because transaction bundles actually contain multiple transactions, and each transaction can include multiple DeFi actions. The structure of the entire transaction bundle is heterogeneous and hierarchical. At this point, we use representation learning methods to represent the contents of the transaction bundle in a latent space. The advantage of using representation learning is that we do not need to deeply learn and understand the data we are analyzing, nor do we require extensive domain knowledge; we only need to perform data-driven processing.
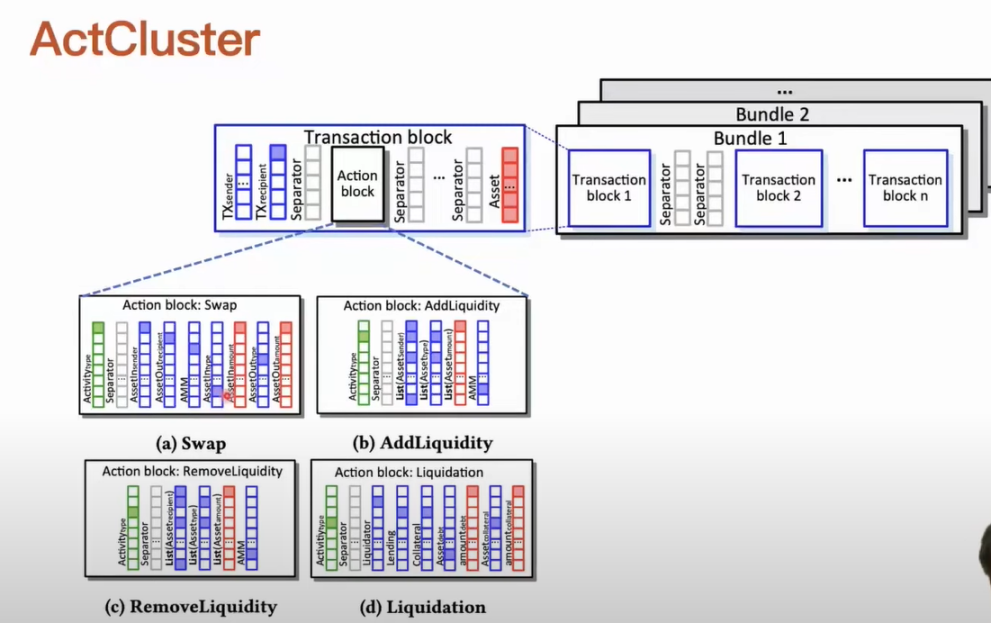
For example, we only need to label the transaction bundle to indicate which MEV activities it contains. If we know the definition of an MEV activity, it is relatively easy to design corresponding rules to automatically detect its existence. We can automate the labeling of these transaction bundles for representation learning. Our clustering analysis is iterative, and after each iteration, we can discover new MEV activities. At this point, we can enrich the labels corresponding to these newly discovered MEV activities into our representation learning process. When the labels used in the representation learning process are enriched, the performance and efficiency of the entire representation learning model can be iteratively improved, and the representation capability of the model for transaction bundle activities can also be iteratively enhanced. A transaction bundle can contain multiple transactions, and each transaction can also contain multiple DeFi actions. We need to represent the transaction bundle. First, for each type of DeFi action, we define a standardized parameter, such as which contract is operating, and what the quantities and types of assets received and transferred are. We define each type of DeFi action in this way. If we identify that a transaction contains multiple DeFi actions, we represent them using action blocks, thus allowing us to represent the corresponding transaction block of this transaction, including the source information of the transaction, such as who initiated the transaction and who the transfer was sent to. When DeFi actions occur in the transaction, we will sequentially fill in the action blocks. Each transaction is represented using transaction blocks, and finally, we obtain the structure of the transaction bundle, which can be considered a matrix. After representing this transaction bundle, we can proceed with representation learning. Each transaction bundle has a unified structure, allowing us to process them in batches using models.
Performance Evaluation
Next, I will share the methods we used to evaluate the performance of our workflow. The dataset for our entire analysis process was obtained through the API provided by Flashbots, collecting transaction bundle data from February 2021 to December 2022, including over 6 million transaction bundles and 26 million transactions.
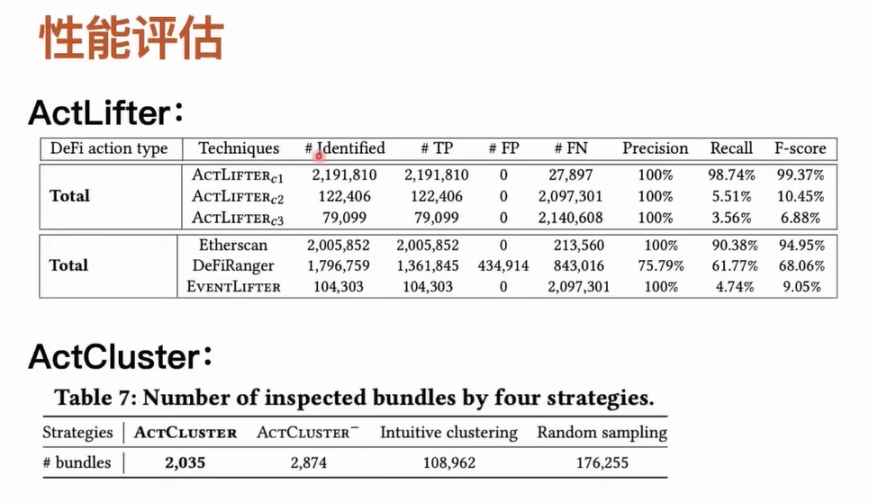
We designed some tools to compare the accuracy and completeness of DeFi actions. It is important to note that among these on-chain tools, currently only Etherscan can recover DeFi actions from transactions through its web interface and the information it provides. As for DeFiRanger, we replicated their methods based on their paper. In addition, we designed a tool called EventLifter, which attempts to directly recover DeFi actions from transaction events. We tested ActLifter under different configurations and used various tools to compare recognition accuracy. For ActCluster, our main idea is to adopt an ablation learning approach. For new activities that can be recognized, after ablating part of the ActCluster module, we assess how many transaction bundles need to be manually analyzed or how large the manual analysis workload is to discover the same number of new activities. For example, we performed an ablation on the dynamic label updating in the representation learning module of ActCluster, effectively removing the entire process. We randomly sampled from the 6 million transaction bundles and examined how many transaction bundles we need to manually analyze to discover the same number of new MEV activities.

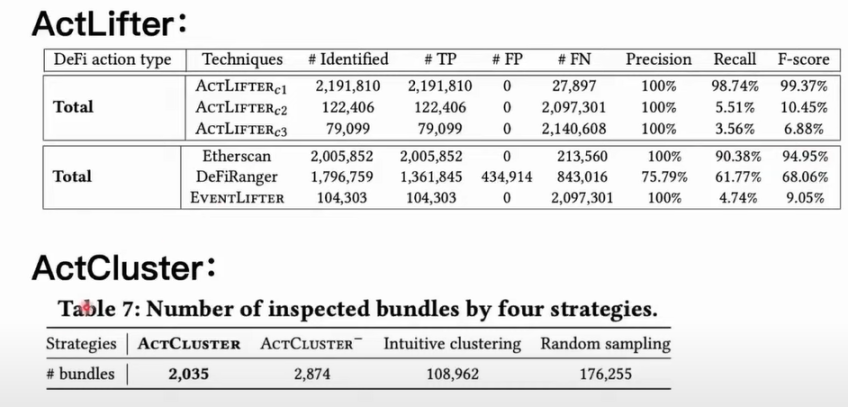
Our tools can achieve nearly 100% accuracy and completeness under uniform configurations. However, other tools like Etherscan, while achieving 100% accuracy, may miss a significant number of DeFi actions. Etherscan itself does not have an open-source method, and we speculate that it may use manual analysis methods to summarize rules for identifying DeFi actions, which correspondingly leads to missing some types that cannot be covered by manual analysis. It is also worth noting that Etherscan does not provide an automated interface, making it impossible to perform large-scale recognition tasks directly. The completely heuristic-based DeFiRanger does not perform satisfactorily in terms of accuracy and completeness. After experimenting with ActCluster, we found that through four rounds of iterative analysis, we only needed to analyze 2,000 transaction bundles to identify 17 unknown MEV activities. If we ablate some of its modules, we may need to manually analyze up to 170,000 transaction bundles to identify the aforementioned 17 unknown MEV activities.
Empirical Analysis and Applications
What specific applications can our method for identifying unknown types of MEV activities have? First, can it enhance existing MEV mitigation measures and defend against some MEV activities? The second is whether we can conduct a more comprehensive analysis of the impact of MEV activities on the blockchain ecosystem, including the effects on blockchain forks, reorganization, and user financial security.
We previously mentioned that MEV boost network attackers run tools to obtain transaction bundles from users and then distribute them to the miners and validators connected to them. Relayers will exclude transaction bundles containing MEV activities from those they receive, thereby reducing the negative impact of MEV activities on the blockchain. The main idea here is to design corresponding rules based on the definitions of existing MEV activities to detect whether transaction bundles contain MEV activities. Clearly, these relayers cannot exclude transaction bundles containing unknown MEV activities. Based on our workflow, we designed a tool called MEVHunter, which can detect new types of MEV activities from transaction bundles.
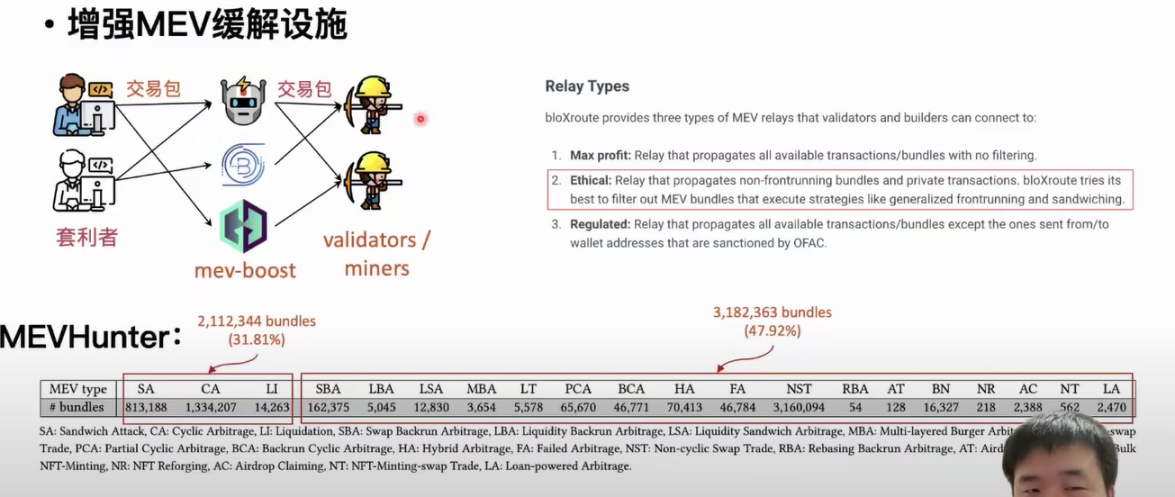
Detection results show that over 1 million transaction bundles contain reverse arbitrage MEV activities, and additionally, 30% of 6 million transaction bundles contain three known types of MEV activities. For the new MEV activities we discovered, we found that nearly half of the transaction bundles only contained these new MEV activities. If relayers use the MEVHunter tool, it can help them filter out 3 million transaction bundles containing MEV activities, allowing them to choose to exclude these transaction bundles and reduce the negative impact of MEV activities on the blockchain.
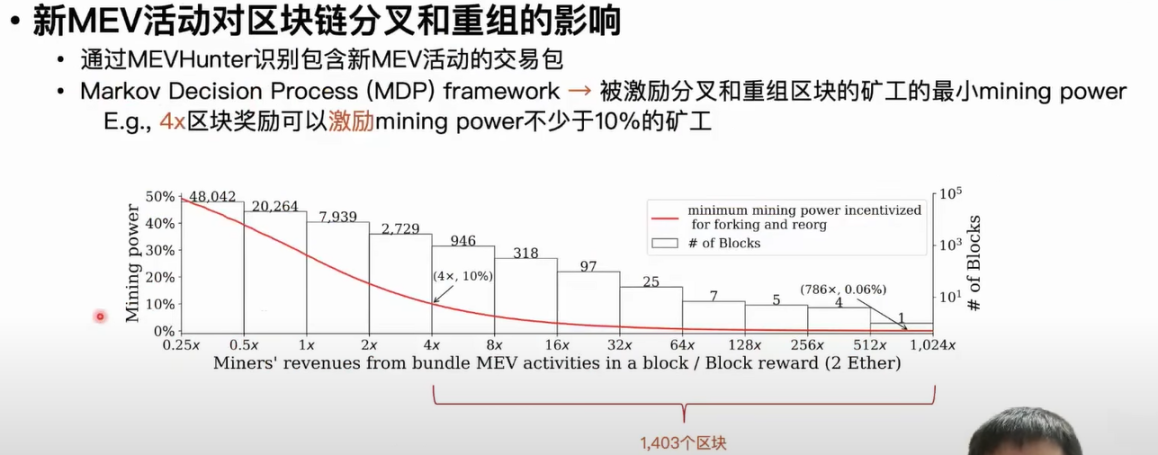
The second application is to explore the impact of new MEV activities on blockchain forks and reorganizations. Previous studies have reported that some financial miners are incentivized by the profits from MEV activities to fork and reorganize the current blockchain to engage in MEV activities themselves and enjoy the profits. For example, when the profits from MEV activities in a block are four times the block reward, at least 10% of miners will fork and reorganize that block.
We first use the aforementioned MEVHunter tool to identify which transaction bundles contain new MEV activities, and then estimate the corresponding intensity of these MEV activities based on the profits of miners from these transaction bundles. Here, we need to introduce a concept: in the transaction bundle mechanism, these arbitrageurs typically share a portion of the MEV activity profits with miners to ensure that their arbitrage transaction bundles can be included on-chain, and miners ultimately choose to include the transaction bundle with the highest profits. We can uniformly estimate the MEV activity profits in each transaction bundle based on this profit. According to our statistical results, we found that there are over 900 blocks where MEV profits are four to eight times the block reward, and one block even has MEV rewards exceeding 700 times the block reward. We used a Markov decision framework to determine the minimum number of miners that can be incentivized to fork and reorganize blocks given a certain MEV profit. We ultimately found that over 1,000 blocks can incentivize at least 10% of miners to fork and reorganize blocks. In the most severe cases, at least 0.06% of miners will fork and reorganize blocks.
The third application is to explore the impact of MEV activities on the financial security of blockchain users. MEV activities can lead to delays in the time users' transactions wait to be included on-chain in the transaction pool or P2P network, which is one of the main threats to users' financial security. If a user's transaction is delayed in being included on-chain, arbitrageurs will have more time to design more complex and more profitable MEV activities. The third application is to compare the impact of MEV activities on the waiting time for users' transactions to be included on-chain. The first step is to collect the waiting times of transactions. We mainly do this by deploying nodes on the network and recording the time the transaction is first discovered on the network and the time it is ultimately included on-chain, thus calculating the waiting time. We use the three quartiles of waiting times for all transactions in each block for statistical analysis, allowing us to organize the waiting times of transactions into a time series for each block. We then characterize the MEV activities in each block based on the profits miners obtained from transaction bundles containing new MEV activities, resulting in multiple time series. We use Granger causality tests to evaluate the impact of MEV activities on transaction times. Causality tests can determine whether fluctuations in one time series lead to fluctuations in another time series and over what range they influence or cause fluctuations in the other time series. When MEV activities fluctuate, we assess whether they lead to longer waiting times for users' transactions and whether this influence persists over subsequent blocks.
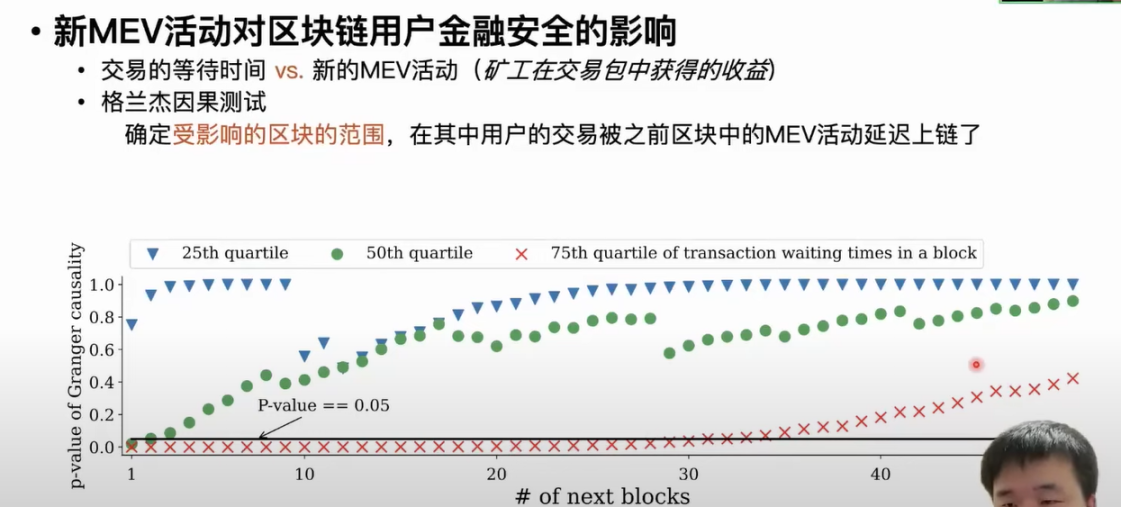
When the P-value of the causality test is less than or equal to 0.5, it indicates that the waiting time of transactions in that block has been extended due to previous MEV activities. According to the analysis results, we found that when MEV activities occur, the waiting time of 50% of transactions in the subsequent two blocks will be extended. After MEV activities occur, the waiting time of 25% of transactions will be extended in the next 30 blocks. Miners or validators tend to place transactions with lower gas fees at the end of the packaged blocks; the lower the gas fee of a user's transaction, the greater the impact of MEV activities, leading to longer waiting times.
In conclusion, we first shared how to find unknown MEV activities through our workflow, along with detailed designs of the two modules in the workflow. We then validated the effectiveness of the workflow through empirical analysis and listed three applications. Currently, we have discovered 17 new MEV activities using our workflow.







