
A comprehensive understanding: Why is "Consensus Layer ZK-ification" needed?

 What should we do when a large number of users and funds come in? The author presents a future scenario composed of three parts: data acquisition, off-chain computation, and on-chain verification. "Proof of Consensus" is an important part of this blueprint. If the consensus layer can achieve ZK (Zero-Knowledge) implementation, it will help scale Ethereum while ensuring security and trust, enhancing the robustness of the entire Ethereum ecosystem.
What should we do when a large number of users and funds come in? The author presents a future scenario composed of three parts: data acquisition, off-chain computation, and on-chain verification. "Proof of Consensus" is an important part of this blueprint. If the consensus layer can achieve ZK (Zero-Knowledge) implementation, it will help scale Ethereum while ensuring security and trust, enhancing the robustness of the entire Ethereum ecosystem.Written by: Zoe, Puzzle Ventures
TL; DR
Since the competition among numerous public chains began, from Danksharding in Ethereum's roadmap to layer two solutions like op/zk, we have been continuously discussing the scalability of blockchain—what to do when a large number of users and funds come in? Through a series of upcoming articles, I want to present a vision of the future, composed of data acquisition, off-chain computation, and on-chain verification.
Trustless Data Access + Off-chain Computation + On-chain Verification
"Proving consensus" is an important part of this blueprint. This article explores the significance of using zero-knowledge proofs for consensus based on Ethereum's PoS, including:
The importance of decentralization for EVM.
The importance of decentralized data access for scaling web3.
Proving full consensus on the Ethereum mainnet is a complex task, but if we can achieve zkification of the consensus layer, it will help Ethereum scale while ensuring security and trust, enhancing the robustness of the entire Ethereum ecosystem, and lowering participation costs, allowing more people to get involved.
I. Why Does Proving Consensus Matter? | Why does proving consensus matter?
Using zk to verify Ethereum L1's consensus layer is meaningful in two major directions. First, it can compensate for the current shortcomings in node diversity, enhancing Ethereum's decentralization and security. Second, it provides a foundation of usability and security for various protocols in the Ethereum ecosystem to face more users, including cross-chain security, trustless data access, decentralized oracles, and scalability.
1. Perspective from Ethereum
For Ethereum to achieve its decentralization and robustness, it needs an environment of client diversity. This means more people participating, especially ordinary users, running clients based on different code environments. However, it is unrealistic to require every user to run a full node, as this requires significant resources, and few can afford at least 16 GB+ RAM and Fast SSD with 2+TB, and these requirements are continually increasing.
The current goal is to achieve light nodes that can provide the same level of trust (trust minimization) as full nodes while having lower costs in terms of memory, storage, and bandwidth requirements. However, currently, light nodes do not participate in the consensus process, or are only partially protected by the consensus mechanism (Sync Committee).
This goal is referred to as "The Verge" in Ethereum's roadmap.
Goal: verifying blocks should be super easy - download N bytes of data, perform a few basic computations, verify a SNARK and you're done --- The Verge on Ethereum's Roadmap
"The Verge" aims to bridge the client gap, with a key step being how to achieve trustless light nodes with a security level equivalent to today's full nodes, filling the "client gap," thereby allowing more people to actively participate in the network's decentralization and robustness.
 https://www.ethernodes.org/network-types
https://www.ethernodes.org/network-types
 https://clientdiversity.org/
https://clientdiversity.org/
2. Perspective of Protocol Stacks on Ethereum
From first principles, we need to solve the problem of combining on-chain data access with off-chain computation verification.
Currently, the use of on-chain data is relatively primitive and insufficient. In many cases, the data required for protocol adjustments is too complex for on-chain computation, while the cost of obtaining data in a trustless manner is too high, requiring extensive historical data access and frequent digital computations.
For individual users and projects, our ideal situation is to achieve decentralized, end-to-end trustless data transfer and read/write, based on which, for more users in the future, we should achieve the lowest possible computational costs while balancing security, usability, and economy.
This includes the following aspects:
1. Decentralized and Trustless Oracles: Current protocols use centralized oracles to avoid direct access to large amounts of historical data on-chain, increasing unnecessary trust costs and reducing composability.
2. Data Read/Write for Protocols Sensitive to Data and Assets: For example, DeFi protocols need to make some parameter adjustments during operation, but whether it is possible to access historical data trustlessly and perform more complex calculations, such as adjusting AMM fees based on recent market fluctuations, designing on-chain derivative trading price models and dynamic volatility, introducing machine learning methods for asset management, and adjusting lending interest rates based on market conditions.
3. Cross-Chain Security: Currently, light node solutions based on zk technology excel in security, capital efficiency, statefulness, and information diversity. Current solutions like Succinct's Telepathy cross-chain solution and Polehedra's cross-chain solution on LayerZero are based on light node block header zk verification using Sync Committee. However, Sync Committee is not part of Ethereum's PoS consensus layer itself, which carries certain trust assumptions, and there is still room for improvement in the future.
Currently, due to economic costs, technical limitations, and user experience considerations, developers typically rely on centralized RPC servers when utilizing on-chain data, such as Alchemy, Infura, and Ankr.
II. Where is Blockchain Data? Trust Assumptions for Different Data Sources
There are two sources of computational data in blockchain: on-chain data and off-chain data. Corresponding to the two directions of on-chain and off-chain, calculations are performed. For example, the need to adjust DeFi protocol parameters mentioned earlier.

Data Access, computation, proof and verification
The reading and computation of on-chain and off-chain data have two notable characteristics:
To achieve decentralization and security, it is best to verify the data we obtain, i.e., "Don't Trust, Verify."
It often involves many complex and expensive computational processes.
If suitable technical solutions are not found, the above two points will affect the usability of blockchain.
We can illustrate different data acquisition methods with a simple example. Suppose you want to check your account balance, what would you do?
One of the safest ways is to run a full node yourself, check the locally stored Ethereum state, and obtain the account balance from it.

Full Node Benchmark. Sync mode and client selection will affect the required space requirements. Reference: https://ethereum.org/en/developers/docs/nodes-and-clients/run-a-node/; https://docs.google.com/presentation/d/1ZxEp6Go5XqTZxQFYTYYnzyd97JKbcXlA6O2s4RI9jr4/mobilepresent?pli=1\&slide=id.g252bbdac4960109)
However, running a full node yourself is costly and requires maintenance. To save trouble, many people might directly request data from centralized node operators. While there is nothing wrong with this approach, similar to operations in Web2, and we have never seen these providers engage in any malicious behavior, it also means we must trust a centralized service provider, which increases the overall security assumptions.
To address this issue, we can consider two solutions: one is to reduce the cost of running nodes, and the other is to find a method to verify the credibility of third-party data.
Why not just store the necessary data? To access data more efficiently, reduce trust costs, and independently verify data, some institutions have developed light clients, such as Rust-based Helio (developed by a16z), Lodestar, Nimbus, and JavaScript-based Kevlar. Light clients do not store all block data but only download and store block headers—a "summary" of all information in a block. Light clients can independently verify the data they receive, so when obtaining data from third-party data providers, you no longer need to fully trust the data from that provider.
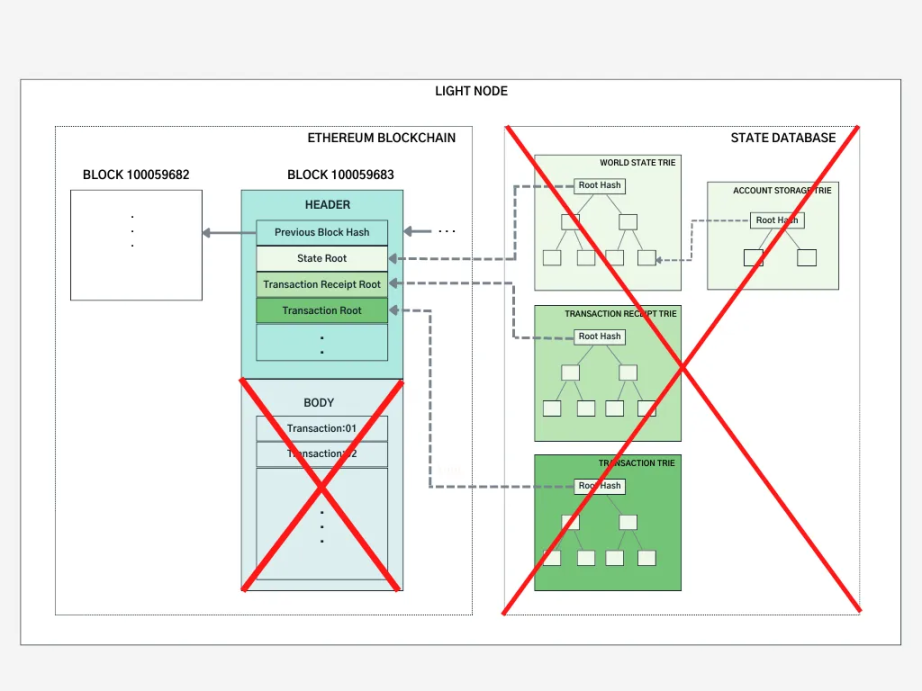
https://medium.com/coinmonks/ethereum-data-transaction-trie-simplified-795483ff3929
The main features of light nodes include:
- Ideally, light nodes can run on mobile or embedded devices.
- Ideally, they can have the same functionality and security guarantees as full nodes.
- However, light nodes do not participate in the consensus process, or are only partially protected by the consensus mechanism, namely the Sync Committee.
The Sync Committee is the trust assumption for light nodes.
Before The Merge, starting in December 2020, the Beacon Chain underwent a hard fork called Altair, whose core purpose was to provide consensus support for light nodes. Unlike PoS full consensus, this group of validators (512) is composed of a smaller dataset, randomly selected over longer time intervals (256 epochs, about 27 hours).
Light clients such as Helios and Succinct are taking steps toward solving the problem, but a light client is far from a fully verifying node: a light client merely verifies the signatures of a random subset of validators called the sync committee, and does not verify that the chain actually follows the protocol rules. To bring us to a world where users can actually verify that the chain follows the rules, we would have to do something different. How will Ethereum's multi-client philosophy interact with ZK-EVMs?, by Vitalik Buterin*
This is why we need to verify the entire consensus layer of Ethereum, aiming for a future that is more secure, more usable, with more diverse protocols, and large-scale adoption, with the best current solution being zero-knowledge technology.
III. The Path to Prove Consensus Using ZK
To build a trustless environment, we must address the issues of light node credibility, decentralized data access, and off-chain computation verification. In these areas, zero-knowledge proofs are currently the most recognized core technology, involving but not limited to zkEVM, zkWASM, other zkVMs, zk Co-processors, and other underlying solutions.
Proving the consensus layer is an important part of this.
The PoS algorithm is very complex, and implementing them in a ZK manner requires a lot of engineering work and architectural considerations, so let's break down its components.
1. Key Steps in Consensus Formation in Ethereum 2.0
(1) Validator-related Algorithms
This includes the following steps:
- Becoming a validator: Validator candidates must send 32 ETH to the deposit contract and wait at least 16 hours to several days or weeks for the Beacon Chain to process and activate them as official validators. (Refer to FAQ - Why does it take so long for a validator to be activated)
- Exercising validation duties: Involves random numbers and block proof algorithms.
- Exiting the validator role: Exiting a validator can be voluntary or penalized (slashed) for violations. Validators can initiate "exit" at any time, but there is a limit on the number of validators exiting each epoch. If too many validators attempt to exit simultaneously, they will be placed in a queue, and until their turn comes, they still need to fulfill their validation duties. After successfully exiting, validators will be able to withdraw their staked funds after 1/8 of an epoch.
(2) Random Number-related Algorithms
- Each epoch contains 32 blocks (slots), and random grouping is done two epochs in advance, dividing all validators into 32 committees to exercise their duties in the current epoch, each responsible for the consensus of each block.
- Each committee has two roles: one proposer and the rest are block builders, who are also randomly selected. This separates the transaction ordering and block building processes (see proposer/builder separation - PBS).
(3) Block Attestation and BLS Signature-related Algorithms
- The signature part is the core of the consensus layer.
- Each slot's validation committee votes (using BLS signatures), requiring a 2/3 approval rate to build a block.
- In Ethereum's PoS consensus layer, BLS signatures use the BLS12--381 elliptic curve, which is pairing-friendly and suitable for aggregating all signatures, reducing proof time and size.
- In proof-of-work, blocks may undergo reorganization (re-org). After the merge, the concepts of "finalized blocks" and "safe heads" on the execution layer were introduced. To create a conflicting block, an attacker needs to destroy at least 1/3 of the total staked Ether; to a large extent, PoS is more reliable than PoW.
 https://blog.ethereum.org/2021/11/29/how-the-merge-impacts-app-layer
https://blog.ethereum.org/2021/11/29/how-the-merge-impacts-app-layer

At the end of June 2023, "Puzzle Ventures Evening Study" introduced Hyper Oracle's zkPoS (using zk methods to verify Ethereum's full consensus layer). For details, see zkPoS: End-to-End Trustless.
(4) Others: Such as Weak Subjectivity Checkpoints
One of the challenges faced by trustless PoS consensus proof is the selection of subjective checkpoints, which involves social consensus (social consensus based on social information). These checkpoints are revert limits, as blocks before the weak subjectivity checkpoint cannot be changed. For details, see: https://ethereum.org/en/developers/docs/consensus-mechanisms/pos/weak-subjectivity/
Checkpoints are also a point that needs to be considered in zkification of the consensus layer.
2. Tech Stacks to Prove Consensus
In proving the consensus layer, proving signatures or other computations is very expensive, but verifying zero-knowledge proofs is relatively cheap.
When choosing to use zero-knowledge proofs for the consensus layer, protocols need to consider the following factors:
- What do you want to prove?
- What is the application scenario after the proof?
- How to improve the efficiency of the proof?
Taking Hyper Oracle as an example, for proving BLS signatures, they chose Halo2. They chose Halo2 instead of Circom used by Succinct Labs for the following reasons:
- Both Circom and Halo2 can generate zero-knowledge proofs for BLS signatures (BLS12--381 elliptic curve).
- Hyper Oracle is not just doing zkPoS; its core product is a programmable on-chain zero-knowledge oracle (Programmable Onchain zkOracle). Directly facing users are zkGraph, zkIndexing, and zkAutomation, and it also uses zkWASM virtual machines to verify off-chain computations. Although Circom is easier for engineers to get started with, it has poor compatibility and cannot ensure that all functional logic can be used.
- Circom-pairing will be compiled into R1CS, which is incompatible with zkWASM and other Plonkish constraint systems, while Halo2 Pairing circuits can be easily integrated into zkWASM circuits; in contrast, R1CS is also not ideal for proof batching.
- From an efficiency perspective, the BLS circuits generated by Halo2-pairing are smaller, have shorter proof times, lower hardware requirements, and lower gas fees.
 https://mirror.xyz/hyperoracleblog.eth/lAE9erAz5eIlQZ346PG6tfh7Q6xy59bmA_kFNr-l6dE
https://mirror.xyz/hyperoracleblog.eth/lAE9erAz5eIlQZ346PG6tfh7Q6xy59bmA_kFNr-l6dE
Another key point in using zero-knowledge to prove the consensus layer is recursive proofs—proofs of proofs, packaging previous occurrences into a proof.
Without recursive proofs, the final output would be a proof of size O(block height), i.e., each block attestation and the corresponding zk proof. Through recursive proofs, aside from the initial and final states, for any number of blocks, we only need a proof of size O(1).

Verify Proof N and Step N+1 to get Proof N+1, i.e. you know N+1 pieces of knowledge, instead of verifying all N Steps separately.
Returning to the initial goal, our solution should target "light clients" with computational and memory limitations. Even if each proof can be verified in a fixed time, if the number of blocks and proofs accumulates, the verification time will become very long.
3. The End Game: Diversified Level 1 zkEVM
Ethereum's goal is not only to prove the consensus layer but also to achieve zero-knowledge for the entire Layer 1 virtual machine through zkEVM, ultimately realizing a diversified zkEVM to enhance Ethereum's decentralization and robustness.
In response to these issues, Ethereum's current solutions and roadmap are as follows:
"Lightweight" ------ Smaller memory, storage, and bandwidth requirements
- Currently, achieving light nodes that only store and verify block headers.
- Future developments will require further efforts in verkle tree and stateless clients, involving improvements to the mainnet data structure.
"Secure Trustless" ------ Achieving the same minimum trust as full nodes
- The basic light node consensus layer has been implemented, namely the Sync Committees, but this is only a transitional solution.
- Using SNARK to verify Ethereum Layer 1, including verifying the execution layer's Verkle Proof, verifying the consensus layer, and SNARKifying the entire virtual machine.
- Level 1 zkEVM aims to achieve zero-knowledge for the entire Ethereum Layer 1 virtual machine and realize the diversification of zkEVM.
Possible Risks
Ideally, when entering the zk era, we need multiple open-source zkEVMs—different clients have different zkEVM implementations, and each client will wait for proofs compatible with its own implementation before accepting a block.
However, multiple proof systems may face some issues, as each proof system requires a peer-to-peer network, and a client that only supports one proof system can only wait for the corresponding type of proof to be recognized by its verifier. Two major challenges that may arise include "latency challenges" and "data inefficiency." The former mainly stems from the slow generation of proofs, leaving a time gap for malicious actors to create temporary forks when generating proofs for different proof systems; the latter arises because generating multiple types of zk proofs requires saving the original signatures. Although theoretically, the advantage of zkSNARK is that it can delete original signatures and other data, contradictions arise that need to be optimized and resolved.
IV. What is the Future?
To welcome more users to web3, provide a smoother experience, create higher usability, and ensure the security of applications, we must build infrastructure for decentralized data access, off-chain computation, and on-chain verification.
Proving the consensus layer is one important component. In addition to Ethereum PSE and the previously mentioned zkEVM layer2, several protocols are also achieving their application goals through zero-knowledge proof consensus, including Hyper Oracle (Programmable zkOracle Network) planning to use zero-knowledge proofs for Ethereum PoS's entire consensus layer to obtain data; Succinct Labs' Telepathy is a light node bridge that submits state validity proofs by verifying Sync Committee consensus to achieve cross-chain communication; Polyhedra was originally a light node bridge but now also claims to utilize devirgo to achieve zk proofs of full nodes and full consensus.
In addition to cross-chain security and decentralized oracles, this method of off-chain computation + on-chain verification may also participate in Optimism rollup's fraud proofs, integrating with OP L2; or provide on-chain proofs for more complex intent structures in intent-based architecture, etc.
Here we are talking about not only the off-chain ecosystem surrounding Ethereum but also a broader market beyond Ethereum.








