Stanford Blockchain Club: What Conditions Are Needed for the Widespread Adoption of Zero-Knowledge Technology?

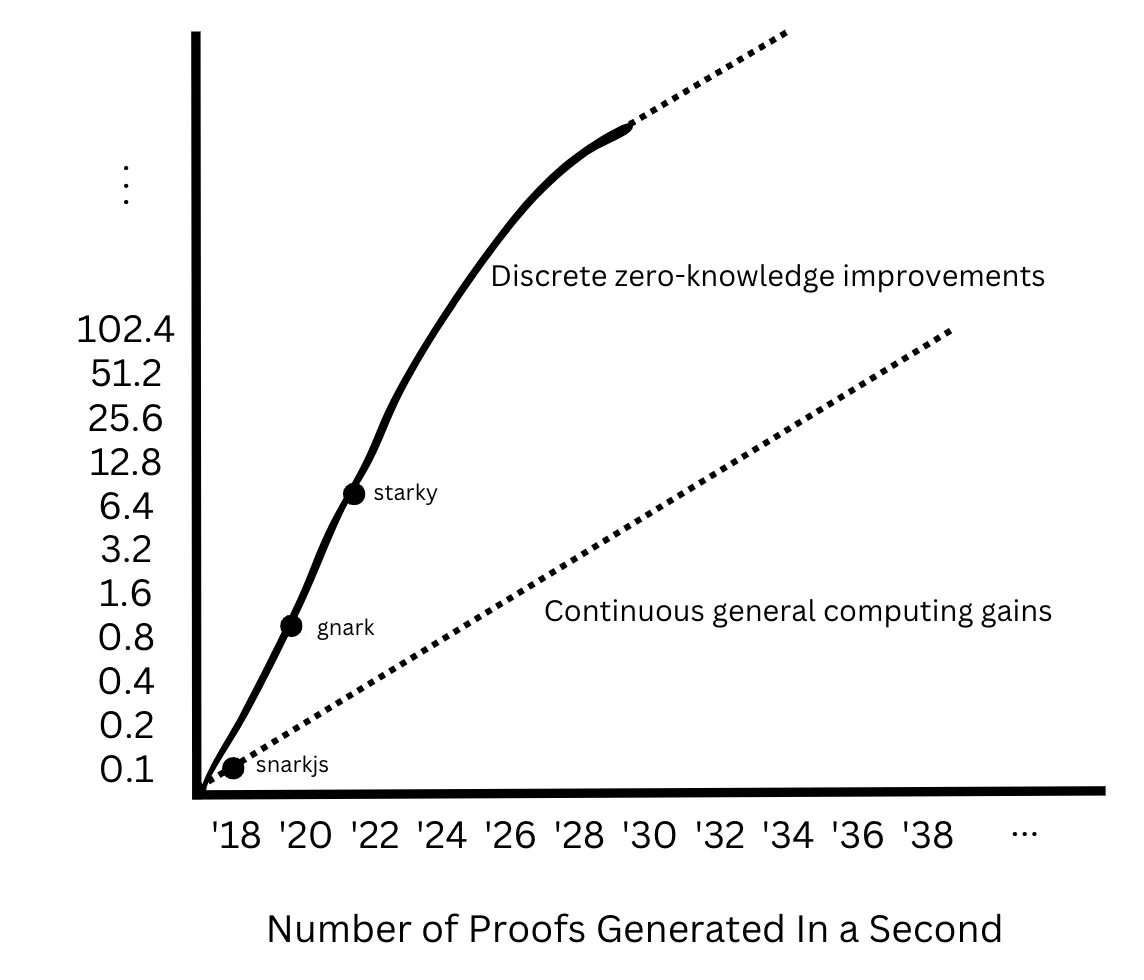
 In the coming years, the number of proofs generated per second will more than double, then asymptotically approach the underlying general computational gains.
In the coming years, the number of proofs generated per second will more than double, then asymptotically approach the underlying general computational gains.Written by: STANFORD BLOCKCHAIN CLUB, ROY LU
Compiled by: Deep Tide TechFlow
Note: This article is from the Stanford Blockchain Review, and Deep Tide TechFlow is a partner of the Stanford Blockchain Review, authorized to compile and reproduce it exclusively.

Introduction
In this article, we will explore how zero-knowledge proofs are changing our lives beyond Web3. I will discuss the leverage of performance enhancement, propose the "Moore's Law of Zero-Knowledge," and identify patterns of value accumulation.
Zero-knowledge is one of the most transformative technologies in today's Web3, with immense potential in scalability, authentication, and privacy. However, the current performance levels limit its application in many potential scenarios. Yet, as ZK technology continues to mature, I believe that ZK technology will experience exponential growth, widely applied in both Web3 and traditional industries. Just as Moore's Law predicts that the density of transistors on chips doubles every two years, I now propose a similar exponential law for zero-knowledge proofs, specifically:
In the coming years, the number of proofs generated per second will more than double, then asymptotically approach the gains of underlying general computation.
Overview of Moore's Law
Moore's Law, proposed by Intel co-founder Gordon Moore in 1965, predicts that "the complexity of semiconductor electronic integrated circuits will double approximately every two years." Over the past 58 years, Moore's Law has driven mobile computing, machine learning, and nearly every aspect of our digital lives, thereby changing the way we interact with technology.
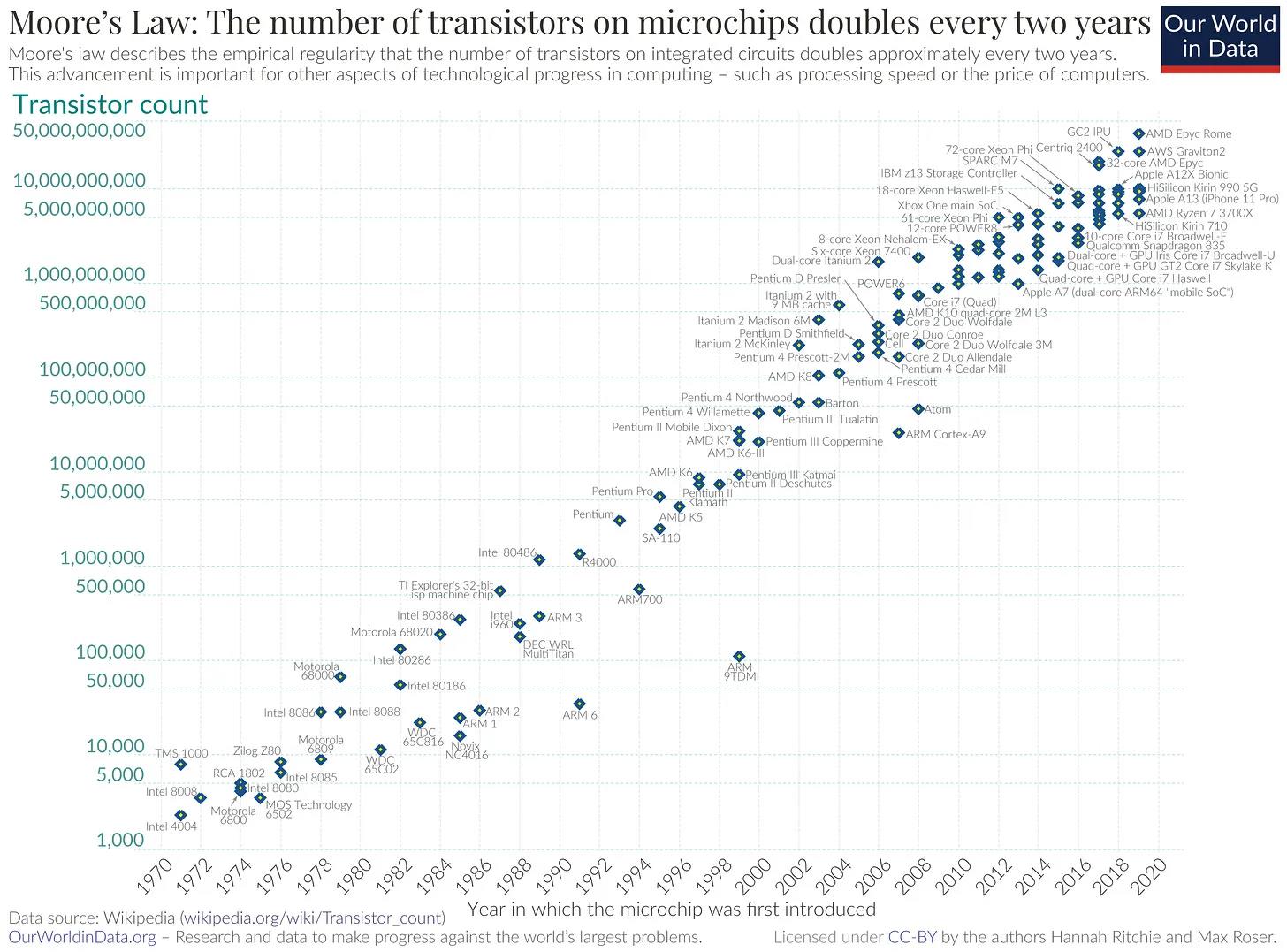
Gordon Moore empirically observed that as the number of transistors on a chip doubles, the manufacturing cost remains essentially unchanged due to economies of scale. He further noted that the demand for computing power would drive investments to increase transistor density.
As computing power exponentially enhances on increasingly smaller chips, this magnitude of change in the number of transistors translates into a qualitative change in how we use and interact with computers.
Our smartphones are more powerful computers than Apollo 11, conveniently fitting in our pockets, enabling us to stream content from any website and communicate with anyone anywhere in the world. The training of large language models paved the way for the release of ChatGPT, changing the way we interact with information from data retrieval to intelligent synthesis.
The Explosion of Zero-Knowledge Proofs and Web3
Just as the doubling of transistor counts and Moore's Law brought about qualitative changes in our interaction with modern technology, the exponential growth of zero-knowledge proofs will usher in a new wave of application-layer experiences. Essentially, zero-knowledge proofs empower privacy, correctness, and scalability, rooted in private computation, provable correctness, and recursive succinctness. These characteristics represent a fundamental shift towards a new computational paradigm.
Private Computation
Zero-knowledge allows computation to occur on private modules, sharing only the results for external verification. In a real-world example, if banks adopt zero-knowledge computation, it can prevent identity theft. For instance, users can allow loan approval processes to run on their identity information and credit history to obtain loan approval without disclosing sensitive data to the bank—privacy is preserved. In Web3, ZK powers fully private L1 networks (like Aleo and Mina) or private payment networks (like Zcash, zk.money, Elusiv, and Nocturne). ZKP also enables teams like Renegade to operate dark pools to list trade orders without affecting market prices, transferring value without revealing users' private data.
Provable Correctness
For opaque computations, zero-knowledge provides traceability for the inputs, outputs, and processes of computation. One example is decentralized machine learning, which democratizes AI through a network of remote computing nodes. ZKP can prove the data, weights, and training iterations in machine learning, establishing that the entire training process proceeded as expected—correctness is established. In Web3, teams like Gensyn and Modulus Labs have begun implementing zkML, while general ZKVMs like Risc Zero are also in implementation. To prove the correctness of cross-chain states, ZKP is used in ZK bridges such as Polymer, Succinct Labs, Herodotus, and Lagrange. ZK also enables applications like Proven to prove the correctness of reserves.
Recursive Succinctness
ZK can also fold a set of proofs into a single proof. Another real-world example is authenticity tracking in supply chains. Manufacturers at each step of the supply chain can use ZKP to prove the authenticity of their products without disclosing sensitive manufacturing information. These ZKPs are then recursively proven, generating a final ZKP that proves the correctness of the entire supply chain—achieving scalability. In Web3, thousands of transaction ZKPs can be merged into a single proof, powering L2 networks like Starkware, Scroll, and zkSync, significantly increasing blockchain throughput.
Defining Moore's Law of Zero-Knowledge
From the above, we have seen the abstract similarities between transistors driving application-layer explosions and ZKP unlocking similar waves of innovation in Web3. It is now time to derive a concrete definition of a "Moore's Law of Zero-Knowledge" by comparing general computation and zero-knowledge computation.
General Computation vs. Zero-Knowledge Computation
In general computation, portals are composed of metal-oxide-silicon-based transistors. Each portal can belong to one of several operands, such as AND, OR, XOR, etc. These operands work together to run programs.
Other conditions being equal, zero-knowledge computation is more expensive than general computation. For example, "using Groth16 for SHA2 hashing 10kb takes 140 seconds, while not using zero-knowledge takes only a few milliseconds." This is because ZK computation uses complex arithmetic operations for each operand.
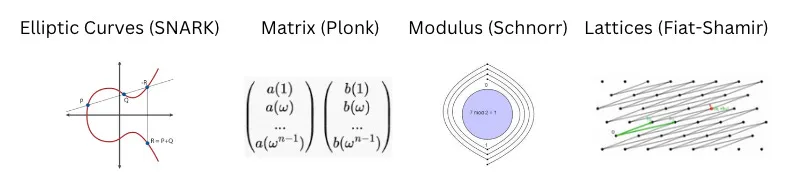
In zero-knowledge computation, operands can be represented in finite fields. In the case of SNARKs, each operand operates on elliptic curves. In other variants of zero-knowledge, operands may consist of matrices, lattices, or modular arrays, which are also complex mathematical structures for performing arithmetic operations. Performing simple addition, subtraction, and multiplication with these operands is very expensive. Data inputs are transformed into finite fields rather than numbers. The complexity of these structures is the foundation for the security of cryptographic techniques. While the arithmetic details are beyond the scope of this article, the key point is that just as logic gates execute in physical circuits, zero-knowledge logic executes in software circuits.
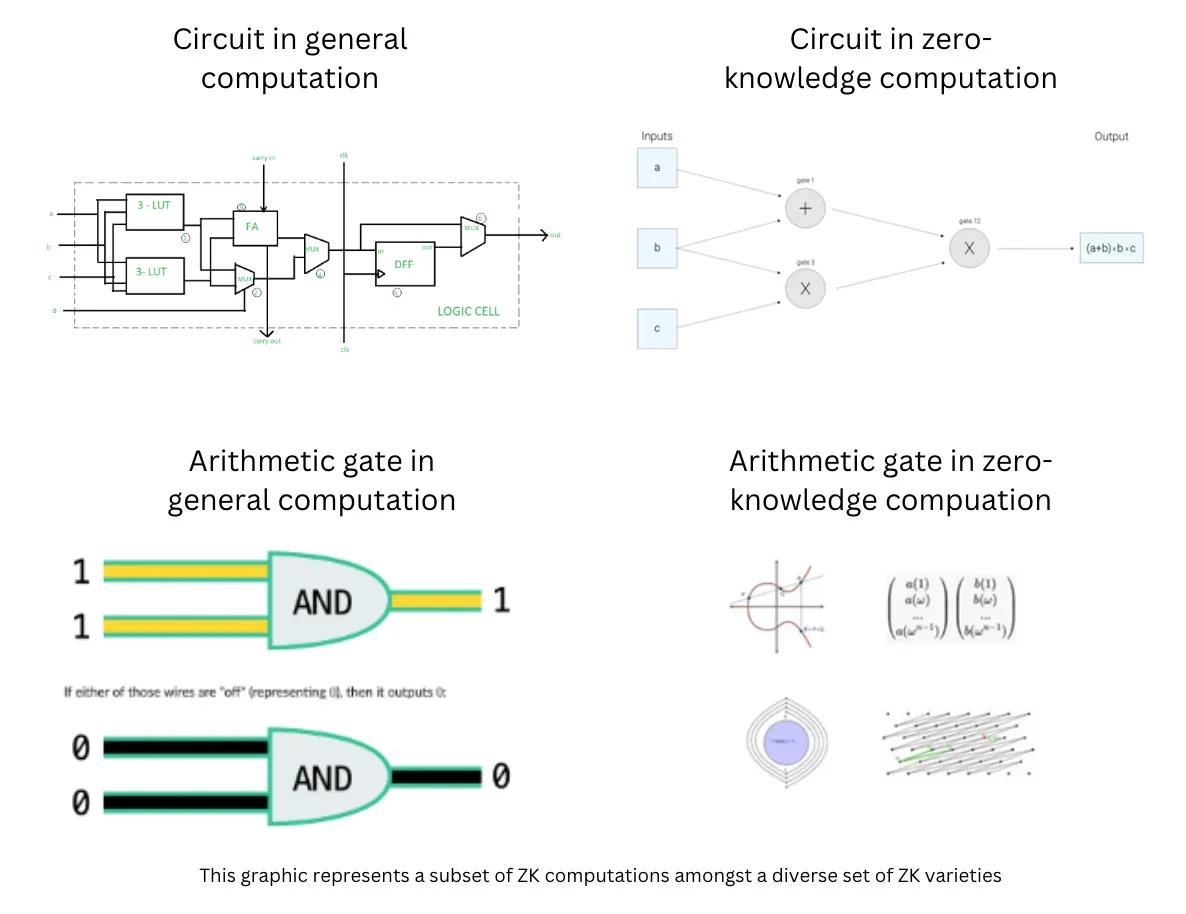
Thus, in general computation, performance improvements are controlled by physical laws, while in zero-knowledge computation, performance improvements are controlled by mathematical laws. Therefore, we recognize that while hardware acceleration also brings significant gains, applying Moore's Law to zero-knowledge exists in the software domain rather than necessarily in the hardware domain. Based on these fundamental principles, we can also derive what a specific Moore's Law of zero-knowledge looks like.
Breakthrough Improvements in Zero-Knowledge are Discontinuous
Perhaps the most important observation is that while improvements in general computation are continuous, improvements in zero-knowledge computation are stepwise.
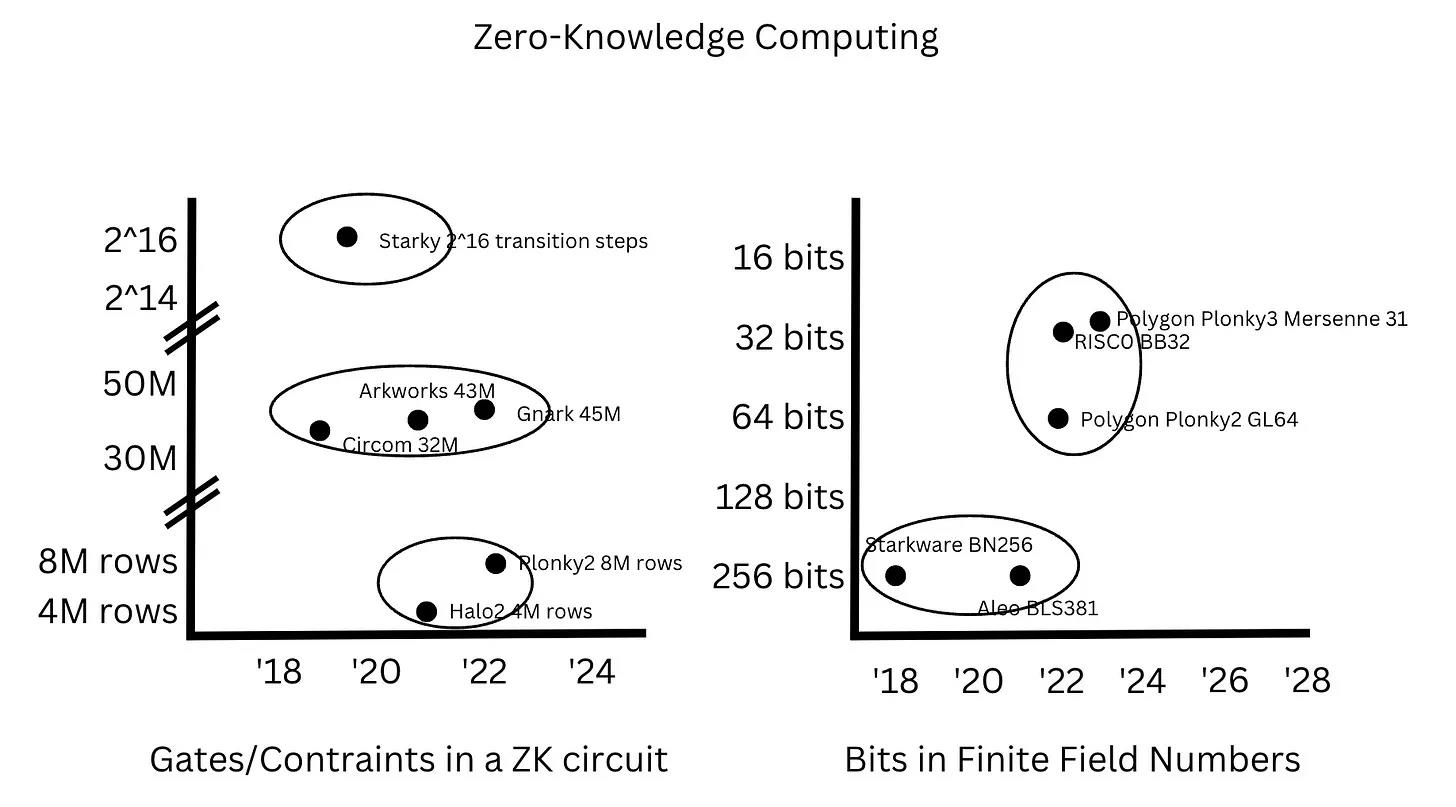
Specifically, from 2005 to 2020, the number of CPU cores roughly doubled every five years, while clock frequencies doubled approximately every five years from the 1990s to the 2010s. On the other hand, the number of constraints in ZK circuits did not "improve" continuously but jumped from 30-40M constraints in SNARKs to 4-8M rows in PLONKs, then jumped to 2^14-2^16 transformation steps in STARKs. Similarly, the bit count in finite fields was around 256 bits from 2018 to 2022, then jumped to 32 bits between 2022 and 2023 to leverage the advantages of 32-bit registers.
Additionally, the latest developments in HyperSpartan support customizable constraint systems (CCS), which can simultaneously capture R1 CS, Plonkish, and AIR without additional overhead. The introduction of Super Nova builds on Nova, a high-speed recursive proof system with folding schemes compatible with different instruction sets and constraint systems. These two advancements further broaden the design space for ZK architectures.
Based on these findings, the fundamental Moore's Law in zero-knowledge is not based on any single continuous improvement vector but on the holistic performance gains in the number of proofs generated over a given time, driven by discontinuous improvements. I believe that before inheriting the gains of underlying general computation, Moore's Law in zero-knowledge will undergo discrete revolutionary leaps:
In the coming years, the number of proofs generated per second will more than double, then asymptotically approach the gains of underlying general computation.
Reducing the Cost of Zero-Knowledge Proofs
As previously mentioned, the current stage of zero-knowledge proofs is too fragile and expensive for widespread potential applications. In particular, the cost of verification far exceeds the cost of proof generation. Rough estimates suggest that the cost of generating a zero-knowledge proof is less than $1, based on the following facts: 1) On Amazon AWS, an EC2 instance with 16 CPUs and 32GB of memory costs $0.4/hour, while the cost of decentralized computing nodes is expected to be lower; 2) The cost of Polygon Hermez is $4-6 per hour, generating about 20 proofs per hour.
However, the on-chain cost of verification remains high, consuming 230,000 to 5 million gas per verification, roughly equivalent to $100-2000 per verification. While ZK Rollups benefit from economies of scale by spreading costs across thousands of transactions, other types of ZK applications must find ways to reduce verification costs to achieve the application-layer innovations mentioned earlier, thereby improving the quality of life for end users.
Given that breakthroughs in zero-knowledge proof capacity may occur in discontinuous and discrete steps, let’s look at potential areas where these breakthroughs might happen. Here are some potential optimization methods listed in zkprize:
- Algorithm optimization, including multi-scalar multiplication (MSM) and number-theoretic transforms (NTT), which are commonly used to accelerate elliptic curve cryptography and can themselves be hardware-accelerated. The Fourier transform is an example of NTT that has been optimized in various implementations.
- Parallel processing can increase zero-knowledge throughput by pre-processing data structures, delegating parts of circuit evaluation or proof generation to multiple processing units or threads.
- Compiler optimization can improve register allocation, loop optimization, memory optimization, and instruction scheduling.
In terms of algorithm optimization, one example is the arithmetic transition from R1 CS in SNARKS to Plonkish in Halo2, Plonky2, and HyperPlonk, which differ from the AIR used in Starky proofs. Additionally, the latest developments in folding schemes are exciting, as HyperNova can support incrementally verifiable computation with customizable constraint systems. In parallel processing, the Plonky2 recursion released by the Polygon team expands the possibilities for parallel proof generation. In compiler optimization, using LLVM suitable for zero-knowledge is intriguing, as the intermediate representation (IR) can be compiled into instruction-set-independent opcodes. For example, Nil Foundation's ZK-LLVM and Risc0's zkVM also use LLVM to generate zero-knowledge proofs that trace each step of execution. General ZKVM or LLVM will extend zero-knowledge to use cases beyond blockchain and increase code portability for a broader range of developer onboarding.
Implications for Zero-Knowledge Builders
In general computation, value accumulation typically favors existing participants; for example, chip manufacturers benefit from the moats formed around capital investments that support incremental improvements in manufacturing technology to produce increasingly smaller chips. However, since innovations in zero-knowledge occur through discrete revolutionary leaps, new teams still have ample opportunities to achieve breakthroughs driven by research-based technical capabilities, such as inventing new proof systems that surpass existing participants.
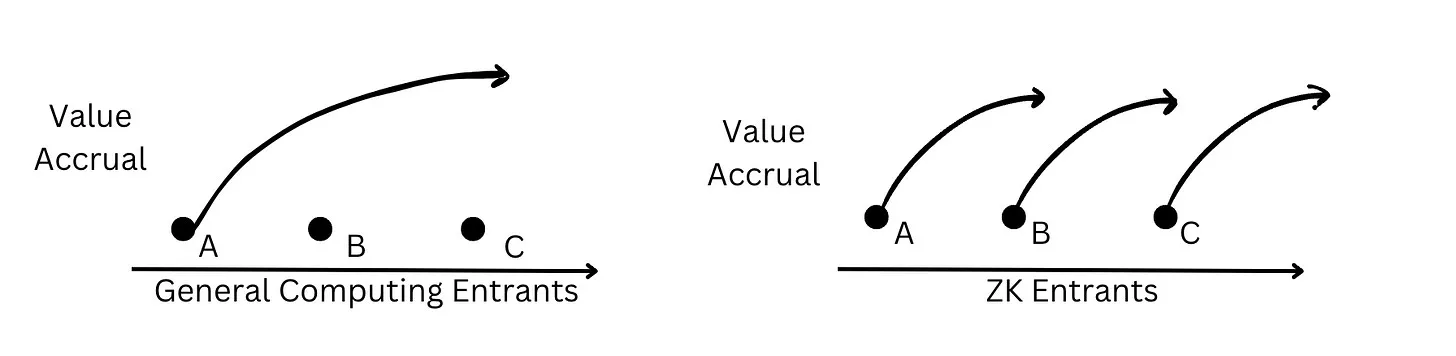
Based on this theory, there are several key points for Web3 zero-knowledge builders:
- Zero-knowledge builders should consider modular design. Protocol builders involving zk circuits should consider modular designs that allow them to replace components of cutting-edge ZK technology.
- Participants can benefit from research-driven disruption. For teams with research capabilities, there is potential to propose or be the first to implement revolutionary new proof systems, surpassing existing teams.
- Vertical integrators can benefit from the combination of the latest technologies. Since every layer in the zero-knowledge stack, from hardware to compilers to circuits, can undergo its own improvements, vertical integrators can modularly adopt the latest technologies and provide cutting-edge ZK technology to application teams at the lowest cost.
Based on these insights, I anticipate three major developments across the industry:
New teams surpass current ZK protocols through technological breakthroughs.
Existing protocols seek moats based on ecosystems rather than technology.
Vertical integrated ZK providers emerge to offer the latest technology at lower costs. Innovation and disruption will arise in this rapidly evolving field.
Conclusion
The paradox of technology is that when technology works well, it becomes invisible. We do not think about the cup when we drink water, just as we do not notice the computer chips when we send emails. The easier the goal is to achieve, the more we tend to overlook the process.
Zero-knowledge proofs have the potential to provide scalable applications that improve user experience. When technology is done well, we do not notice the existence of proofs, but we find our transactions more private, our information more accurate, and Rollups faster and cheaper. Thus, zero-knowledge proofs may ultimately become the foundation of our lives, just as transistors, microchips, and now artificial intelligence have become integrated into our daily lives.
We do not need to consider how zero-knowledge prevents fraud in elections, how it saves transaction costs by disintermediating the financial system, or how it democratizes AI training through decentralized computing using ZK. Perhaps one day, just as we revere Moore's observation that "the number of transistors on a circuit board will double every 18-24 months" as a so-called "law," we will also take for granted that "the number of zero-knowledge proofs per second will grow exponentially each year," while enjoying the benefits brought by these innovations. The goals will be achieved more simply, and no one will keep praising zero-knowledge; we will continue to live our everyday lives.