
A Comprehensive Understanding of Web3 Data Track Unicorns, Disruptors, and Future Stars

 Although unicorns worth tens of billions of dollars have already emerged, the data track of Web3 is just beginning.
Although unicorns worth tens of billions of dollars have already emerged, the data track of Web3 is just beginning.Author: FC@SevenX Ventures
Editor: Iris
If the buzzword in the tech field in 2021 was the metaverse, then this year's seat will likely be reserved for "Web3." In a flash, various popular science articles, analyses, forecasts, and doubts have emerged, making this term the undisputed traffic password.
Among the various viewpoints, although people have different definitions of Web3, there is a consensus that Web3 allows users to have ownership and autonomy over their data, which is also a key factor driving the evolution from Web2 to Web3. As our lives and work become more thoroughly digitized, meaning that human activities will be presented as data flows, the transfer of data rights becomes particularly crucial.
Therefore, we have reason to believe that the data track of Web3 will become one of the most important components of the new order, with vast development space. From the perspective of entrepreneurs, the decentralized network driven by blockchain technology is essentially an open, permissionless distributed database, where there are naturally many scenarios that need to be served in terms of data direction. Choosing it is likely to evolve and grow on the right technological tree. In today's article, I will outline the market structure and typical players of the existing Web3 data track, briefly interpret its future development trends, and share some investment judgments from SevenX.
Core Points of This Article:
Web3 breaks down data silos while returning data rights to individual users, allowing users to carry their data at any time and interact with applications freely.
The structure of the Web3 data track can be divided into four levels: data sources, data acquisition, data querying and indexing, and data analysis and application. The degree of decentralization of the project, scalability, speed and accuracy of the services provided, and the irreplaceability of the scenarios are the main dimensions we use to judge projects.
With the gradual enrichment of data market participants and the accumulation of data itself, the value of data will significantly increase. However, how to better adhere to the fundamental spirit of blockchain to protect privacy while utilizing data to generate greater value is another important topic.
Building a decentralized reputation system through multi-dimensional data vectors is one of the next most important use cases in the Web3 data market. Based on the reputation system, various financial scenarios such as unlocking credit lending become possible.
What Am I Talking About When I Talk About Web3 Data
In the process of human civilization development, a large amount of data is generated. Some are forgotten, lost in the river of time, while others are recorded and solidified into known history. The advent of the internet has allowed humanity to record and share data in a more efficient and broader way, further uncovering the value of data, which has gradually become a consensus in society. In the cover story of The Economist in May 2017, data was even defined as "the most valuable resource in the world."
However, as the amount of data accumulated on the internet increases, a fundamental problem begins to emerge: the data generated by individuals creates value, but this data does not belong to individuals, and the value created is not distributed to them. Thus, people yearn for a new order, and Web3 was born.
So how does Web3 reshape data value? There are mainly three aspects:
- Data is open, transparent, and immutable.
In the world of Web2, applications obtain user data by providing free services, then profit by monopolizing this data and establishing their own business moats. Data is stored on their centralized servers, inaccessible to the outside world, and it is impossible to know what data is stored, how it is stored, and at what granularity. Moreover, once these applications are attacked or voluntarily cease operations, user data can disappear overnight. However, under the Web3 framework with blockchain technology as the foundation, on-chain data achieves openness, transparency, and immutability, which is a prerequisite for better utilization.
- Breaking down data silos and enhancing interoperability.
Every time a new application is used, users do not have to repeatedly go through the registration process. This is the most intuitive manifestation of the negative impact caused by Web2 data silos on the user side. Each application has its own database, independent of each other, making it impossible to connect, resulting in repetitive data collection. At the same time, user behavior data is fragmented across different applications, making it impossible to reuse across platforms or integrate. In the world of Web3, broadly speaking, users only need one address to access and use various decentralized applications, and every on-chain interaction that occurs with this address can be combined without any application permission.
- Achieving better value distribution through token economics.
How the value created by data can be distributed to the individuals who generate this data is an important question that Web3 needs to answer. The evolving token economy may be the core means to achieve this value redistribution, which any user who has benefited from various airdrops should have a very intuitive feeling about. In the context of Web3, the data accumulated and generated from user interactions with any application serves as a vehicle for value capture.
In fact, the evolution of the crypto market itself has largely driven the development of the Web3 data track. On the supply side, the formation of a multi-chain universe, the explosion of various applications, the booming development of NFTs, and the influx of new users have led to an exponential increase in the types and quantities of data. On the demand side, the diversification and complexity of demand have spawned countless imaginative scenarios and opportunities around data acquisition, organization, access, querying, processing, and analysis.
Web3 Data Track Structure Diagram
The structure of the Web3 data track can be divided into four levels: the bottom layer of data sources, the second layer of data acquisition, the third layer of data querying and indexing, and the top layer of data analysis and application.
First Layer: Data Sources
Data sources are generally divided into on-chain and off-chain data. On-chain data mainly includes: chain-related data (such as hashes, timestamps, etc.), transfer transactions, wallet addresses, smart contract events, and some data stored in caches (such as queued data in Ethereum's mempool). This type of data is maintained by decentralized databases, with reliability guaranteed by the consensus of the blockchain. Additionally, storage is also a major source of on-chain data, currently concentrated in protocols like IPFS, Arweave, and Storj. Off-chain data mainly includes data from centralized exchanges, social media data, GitHub data, and some typical Web2 data, such as page views (PV), unique visitors (UV), daily active users (DAU), monthly active users (MAU), downloads, search indices, etc.
In the past two years, both the types and quantities of data have increased exponentially, but currently, there are three issues regarding data sources:
Some public chains adopt a light node model, leading to incomplete on-chain data, such as Solana.
The storage layer experiences congestion due to the large volume of data. My good friend REVA once uploaded her NFT work to IPFS, but when she tried to retrieve it, it took her two hours to download a file of several hundred megabytes (imagine the frustration of not being able to download a standard-definition movie in two hours). However, there are already projects in the market working to solve this problem, such as SevenX's Portfolio: Meson Network. It is a decentralized CDN network that aggregates idle servers through mining, schedules bandwidth resources, and serves the file and streaming acceleration market, including traditional websites, videos, live broadcasts, and blockchain storage solutions, and currently supports AR, IPFS, etc.
Off-chain data lacks methods to ensure its authenticity, and the dimensions of data need to be expanded.
Second Layer: Data Acquisition
The main players in this layer are node service providers. If one chooses to obtain on-chain data by building their own nodes, it requires high time, financial, and technical costs, and may face issues like memory leaks and insufficient disk space. Node service providers greatly optimize this process. As the infrastructure of the entire data track, node service providers were among the earliest participants and have birthed unicorns valued at over $10 billion.
Currently, well-known service providers include Infura, Quicknode, Alchemy, and Pocket. When developers and entrepreneurs choose, they mainly consider factors such as the number of chains covered, business models, and the diversity of additional services (e.g., whether there are CDN-like services, whether mempool data can be accessed, whether private nodes can be provided, etc.). Infura's previous node downtime incidents have also made decentralization one of the criteria for selection. (In November 2020, Infura did not run the latest version of the Geth client, and certain special transactions triggered a bug in this version, leading to Infura's downtime and a series of chain reactions: mainstream trading platforms could not deposit or withdraw ERC-20 tokens, MetaMask could not be used, etc.)
A simple comparison of the four node service providers is as follows:
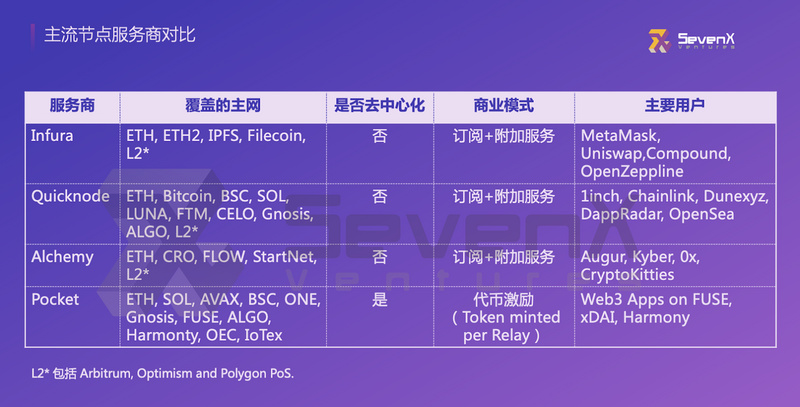
On February 8 of this year, Alchemy completed a $200 million financing round at a valuation of $10.2 billion; Infura's parent company ConsenSys also completed a $200 million financing round last year, with a valuation of $3.2 billion; as of March 2022, Pocket's circulating market value reached $3.28 billion.
Third Layer: Data Querying and Indexing
Above the node service providers that interact directly with various public chains are market participants that provide data querying and indexing services. They parse and format data to make raw data easier to access and use.
- The Graph
The Graph is a decentralized on-chain data indexing protocol. Launched on the mainnet in December 2020, it currently supports indexing data from over 30 different networks, including Ethereum, NEAR, Arbitrum, Optimism, Polygon, Avalanche, Celo, Fantom, Moonbeam, Arweave, etc.
It is similar to traditional cloud service-based APIs, with the difference being that traditional APIs are operated by centralized companies, while on-chain data indexing consists of decentralized indexing nodes. With the help of GraphQL APIs, users can directly access information through subgraphs, quickly and resource-efficiently. The Graph has designed a GRT token mechanism to encourage multiple parties to participate in its network, involving delegators, indexers, curators, and developers. The flow of business can be summarized as follows: users submit query requests, indexers run The Graph nodes, delegators stake GRT tokens to indexers, and curators use GRT to indicate which subgraphs have query value.
- Covalent
Covalent provides a data querying layer that allows its users to quickly call data in the form of APIs, currently supporting Ethereum, BNB Chain, Avalanche, Ronin, Fantom, Moonbeam, Klaytn, HECO, SHIDEN, and mainstream Layer 2 networks.
Covalent supports querying all types of blockchain data, such as transactions, balances, log types, etc., as well as querying data for specific protocols. Covalent's most notable feature is cross-chain querying, which does not require re-establishing an index similar to The Graph's subgraphs; it can be achieved by changing the Chain ID. This project also has its own token CQT, which holders can use to stake and vote on events such as new database listings.
- SubQuery
SubQuery provides data querying services for Polkadot and Substrate projects, allowing developers to focus on their core use cases and front-end without wasting time building custom backends for data processing. SubQuery is inspired by The Graph and also uses GraphQL language, with its token economics similar to The Graph: there are three roles in the SubQuery system: consumers, indexers, and delegators. Consumers publish tasks, indexers provide data, and delegators stake idle SQT tokens to indexers to incentivize their honest participation in work.
- Blocknative
Blocknative focuses on real-time transaction data retrieval, providing a mempool data browser, such as address tracking, internal transaction tracking, information on unsuccessful transactions, and information on replaced transactions (accelerated or canceled). Because the data from the mempool and the final block data may not be consistent, the requirements for real-time data are high. The fields provided by Blocknative are more immediate and precise.
- Koii Network
Koii is a decentralized ecosystem aimed at helping creators permanently own content and earn value from it. Anyone can use the Koii system to earn token rewards by deploying tasks, running nodes, or creating/registering content. The system rewards participants based on data processed through real traffic proof, achieving a cycle of "attention economy." Additionally, the Atomic NFT developed by the Koii team realizes the preservation and rights confirmation of NFTs and their meta-information (the actual digital content represented by the NFT) on the same chain, allowing all content on the Koii platform to be generated according to the same standards. If this scalability successfully encourages content accumulation to a certain scale, Koii will also become an important content data indexing platform.
The following projects provide both data querying and indexing services and have products belonging to the data application and analysis layer. For convenience, they are described here.
- Dune Analytics
Dune Analytics is a comprehensive Web3 data platform that allows users to query, analyze, and visualize massive amounts of on-chain data. It parses on-chain data stored in key-value databases and then inputs it into a PostgreSQL relational database, allowing users to query without writing scripts, using only simple SQL statements. Dune Analytics can provide three types of data tables: raw transaction data tables, project-level data tables, and aggregated data tables.
Dune Analytics encourages data sharing; by default, all queries and datasets are public, and users can directly copy others' dashboards and use them as references. Currently, some of the best data analysts in the Web3 field have gathered here. Dune Analytics currently supports data queries for Ethereum, Polygon, Binance Smart Chain, Optimism, and Gnosis Chain. In February of this year, it completed a Series B financing round of $69.42 million, reaching a valuation of $1 billion and officially entering the unicorn ranks.
- Flipside Crypto
Similar to Dune Analytics, Flipside also allows users to perform complex data queries through visual tools and automatically generated API interfaces using simple SQL statements. Users can also copy and edit SQL queries that others have already generated. Flipside actively collaborates with leading crypto projects, incentivizing on-demand analysis through structured bounty programs and guidance, helping projects quickly gain the data insights they need for growth.
Currently, Flipside supports public chain networks such as Ethereum, Solana, Terra, and Algorand. On April 19, Flipside announced the completion of a $50 million financing round.
- DeBank
DeBank is a DeFi portfolio tracker that allows users to track and manage all the DeFi applications they have interacted with in one place, viewing address balances and changes, asset distribution, authorization status, pending rewards, lending positions, and more. It currently supports 1,147 protocols across 27 networks.
Last April, DeBank officially launched its OpenAPI program, opening up 28 APIs for obtaining all protocols on a specific chain, obtaining all chains and contract address lists supported by a specific protocol, and obtaining real-time portfolio information on a specific protocol. All institutional and individual developers can apply to become official partners and access DeBank's DeFi analysis data in real-time. Currently, imToken, TokenPocket, Math Wallet, Mask, Hashkey Me, OneKey, and Zerion are all using DeBank's API, and DeBank has successfully extended its market from data applications down to data querying and indexing.
- CyberConnect
CyberConnect is a decentralized social graph protocol that aims to build a scalable standardized social graph module, allowing developers to easily transplant the social graph module into new applications, saving time and economic costs. For end users, their social data becomes a portable asset that can be easily transplanted into new applications, breaking down the barriers between platforms in the Web2 world.
- RSS3
RSS3 is the next-generation data indexing and distribution protocol derived from the RSS protocol. It allows users to generate RSS3 files based on their addresses and link their social platforms such as Twitter, Mirror, and Jike into the file. The file will synchronize the user's assets, content, and behavioral data (transactions, likes, retweets, etc.) in real-time, while storing this information in the decentralized network of RSS3. Developers can retrieve content published by users on different platforms through various API interfaces, filtering and displaying different information based on application characteristics.
- Go+
Go+ is dedicated to creating a "secure data layer" in the Web3 world based on its "security engine." It has released a token security monitoring feature for end users, allowing users to input token contract addresses to obtain nearly 30 security monitoring metrics covering contract security, transaction security, and information security for tokens across ETH, BSC, Polygon, Avalanche, Arbitrum, HECO, and other public chain ecosystems. At the same time, Go+'s security APIs can also be referenced by other developers and downstream applications to create a safer crypto ecosystem for their projects. These security APIs include token detection, NFT detection, real-time risk warnings, dApp contract security, interaction security, etc.
The emergence of Go+ actually showcases a trend in the Web3 data track: the verticalization of data indexing. SevenX has found in its research that with the surge in the number of protocols and projects, as well as the complexity of user behavior, there are more and more vertical data scenarios emerging in the data market. These scenarios are characterized by non-general data, high frequency of user demand, where users are both data consumers and providers. In the future, there will likely be more data indexing, querying, and analysis services aimed at these vertical scenarios, which are likely to become disruptors in the entire market due to their clear positioning.
Fourth Layer: Data Analysis and Application
This layer directly faces end users (broadly defined, not just individual users), delivering ready-to-use data products. They help users complete all the heavy lifting, directly presenting data value from their methodological perspective. Participants in this layer can be roughly divided by data type into those targeting on-chain transactions, token prices, DeFi protocols, DAOs, NFTs, security, social aspects, etc. Of course, there are also more and more projects focusing on a specific type of data, aiming to become a more comprehensive data analysis platform.
- Blockchain Explorers
These may be the earliest data application layer products, allowing users to directly search for on-chain information through web pages, including chain data, block data, transaction data, smart contract data, address data, etc.
Glassnode & Messari & CoinMetrics.io
Blockchain data and information providers that offer on-chain data and trading intelligence from different perspectives and metrics, providing market analysis insights and research reports.
CoinGecko & CoinMarketCap
Token analysis tools used to observe and track token prices, trading volumes, market capitalizations, etc.
Token Terminal
Analyzes DeFi projects using traditional financial metrics such as P/S ratios, P/E ratios, and protocol revenues. It currently also supports analysis of NFT trading markets.
DeFiLlama
A data analysis platform focused on DeFi Total Value Locked (TVL), supporting nearly a thousand DeFi protocols across 107 Layer 1 & Layer 2 networks, allowing users to classify, compare, and view data using different metrics and time dimensions. DeFiLlama also supports NFT analysis, focusing on trading volumes and collections across different chains and trading markets.
NFTSCan & NFTGO
Data platforms focused on the NFT market, providing data analysis and whale wallet monitoring services, aimed at helping users better track and assess the value of NFT projects and assets to make informed investment decisions.
Nansen
If one word could summarize Nansen, it would be "label." Nansen has analyzed over 50 million Ethereum wallet addresses and their activities, combining on-chain data with a database containing millions of labels to help users better find signals and new investment opportunities. Nansen is currently one of the most prominent projects in the Web3 data analysis and application layer, completing a $75 million financing round at a valuation of $750 million last December.
Chainalysis
Known as the "on-chain FBI," Chainalysis was founded in 2014 and is a corporate data solutions company that helps governments, cryptocurrency exchanges, international law enforcement agencies, banks, and other clients comply with regulatory requirements, assess risks, and identify illegal activities through on-chain data monitoring and analysis. Last June, Chainalysis announced it had raised $100 million in Series E financing, reaching a valuation of $4.2 billion.
Footprint Analytics
Footprint is a comprehensive data analysis platform for discovering and visualizing blockchain data. Compared to other applications, Footprint has a lower barrier to entry and is very user-friendly for beginners. The platform offers a rich set of data analysis templates, supports one-click forking, and helps users easily create and manage personalized dashboards. Footprint also has tagging for other wallet addresses and their activities on-chain, allowing users to make investment decisions based on a rich set of metrics.
Zerion & Zapper
The earliest DeFi portfolio trackers and managers, both of which have now added support for NFT assets.
DeepDao
DeepDAO is a comprehensive data platform focused on various DAO organizations, allowing users to easily view treasury amounts and changes, treasury token distributions, governance token holdings, active members, proposals, and voting situations. DeepDAO also provides dozens of tools for creating and managing DAOs.
There are many more applications in this layer, which will not be listed one by one here.
In fact, SevenX has been paying attention to the data track for a long time and has invested in DeBank, Zerion, Footprint, Koii, DeepDao, RSS3, CyberConnect, and Go+. In the process of screening projects, we have some insights and judgments, which I will briefly share here:
Overall, the application layer traffic is no longer the core barrier. Users can quickly migrate due to the usability, update speed, and other factors of other products. Products that have data provision capabilities and form a closed-loop data channel with users will be more competitive. However, before barriers are formed, traffic products have the potential for feedback.
How do we evaluate? There are five dimensions:
1. Scenario Selection:
(1) Is there a demand, and is the maturity of that demand sufficient or will it occur in the future?
When projects are looking for demand, they need to assess the maturity or stage of that demand. Taking GoPlus as an example, "security" has become a necessity in the DeFi world, and security is a demand that almost everyone agrees upon. This demand has been activated and gradually matured after various security incidents that are diverse and difficult for ordinary users to identify and prevent. Therefore, people are now willing to take an extra step or spend money to purchase a safer experience.
(2) Should we first target the C-end or the protocol?
We believe that when the scenario demand has not been fully activated, it is better to first create C-end products to identify user pain points; otherwise, it is easy to be hammering away at finding nails. For example, in the early stages, GoPlus created the Go Pocket wallet, which served as a model room. With a model room, other partners can better understand what problem the product is solving, which greatly aids in customer acquisition for the B-end when extending to protocols later.
In the future, SevenX will focus on scenarios such as GameFi, DeFi, DAO, NFT, social, and security.
2. Data Capability:
Data acquisition, structuring, etc., are basic skills, but whether one has data capabilities based on industry knowledge is key.
3. C-end Product Capability:
C-end product capability mainly looks at whether it can identify the urgent needs of the audience as a cold start method and whether it can be user-friendly.
4. To B Expansion Capability:
To B expansion is a complex decision-making process. Whether it can acquire benchmark users or efficiently acquire long-tail users based on product positioning are all factors to consider.
5. Team Background:
(1) Background in a vertical track in Web2, having independently operated a project.
(2) Experience in open-source communities.
(3) Rapid learning ability and unbiased learning.
The Possibilities of Web3 Data
With the increase in on-chain analysis, the anonymity of blockchain is gradually being broken. For example, people can track the trading addresses and behaviors of large holders based on Nansen's labels, and can identify the activities and organizations a specific address participates in through on-chain addresses, exposing our data to the sunlight and losing the right to choose privacy. Recently, Nansen stated that it has marked over 100 million wallets, highlighting the increasing importance of privacy needs.
Current privacy solutions mainly include privacy coins, privacy computing protocols, privacy trading networks, and privacy applications.
If we want to protect our on-chain transactions or selectively discover activities, or if we want the process to be invisible but the results visible, we can choose privacy computing protocols like Oasis Network, which commonly use technologies such as zero-knowledge proofs, secure multi-party computation, modern cryptography-based federated learning, and trusted execution environments (TEE).
However, the current usability of these protocols is relatively limited, with most still in the development stage. More applications have been launched on the Secret Network, which has already launched cross-chain bridges like Secret Bridge, privacy DeFi protocols like Sienna Network, privacy trading protocols like Secret Swap, and trustless privacy solutions for Bitcoin like Shinobi Protocol.
Since the second half of 2021, leading VCs and developers have begun to flood into the privacy track. It is believed that as this market gradually develops, people will find a balance between how to utilize data to generate greater value while adhering to the fundamental spirit of blockchain to protect privacy.
Finally, let me briefly mention our judgment on market trends: building a decentralized reputation system through multi-dimensional data vectors is one of the next most important use cases in the Web3 data market. Based on the reputation system, various financial scenarios such as unlocking credit lending become possible.
Lending has always been an important component of the DeFi ecosystem. Currently, the product types in the entire market mainly consist of collateralized lending (usually over-collateralized) and flash loans. Credit lending, which does not rely (or not completely rely) on collateral, has always been regarded as the most important evolutionary direction because credit creates a more freely exchanging market.
However, the biggest obstacle to introducing credit lending in DeFi is that lenders only face an address, making it impossible to effectively verify the borrower's repayment ability and whether they have a bad credit history. Some solutions attempt to achieve this goal by bringing off-chain credit data on-chain, but how to ensure the authenticity of off-chain data itself and during the on-chain process has not been well answered.
Now, with the gradual improvement of on-chain identity systems and the simultaneous growth of available data and data analysis tools, what users create, contribute, earn, and own on-chain can gradually accumulate into the user's reputation, enabling effective credit assessment between one address and another. In fact, the Lens Protocol backed by AAVE is doing just that, using NFTs to manage data and laying the foundation for on-chain unsecured credit lending.
In Conclusion
Although unicorns valued at billions of dollars have already emerged, the Web3 data track is just beginning. Standing amidst the surge of on-chain applications, every bit and byte is defining what kind of Web3 citizen you are. We need to seek new orders and paradigms to collectively resist the entropy increase of the new world.







