Methodology, Tools, and Team: How to Become a Web3 Data Analyst?

 Web3 will also open source data, which means that data scientists are no longer the only ones working in an open environment.
Web3 will also open source data, which means that data scientists are no longer the only ones working in an open environment.Original Author: Andrew Hong
Original Title: [2022] Guide to Web3 Data: Thinking, Tools, and Teams
Compiled by: GaryMa, Wu Says Blockchain
This article assumes you are a data analyst who has just started exploring web3, beginning to build your web3 analytics team, or have recently developed an interest in web3 data. Regardless of your approach, you should already be somewhat familiar with how APIs, databases, transformations, and models work in web2.
In this new guide, I will succinctly outline my three points:
- Thinking: Why open data channels will change the way data is utilized
- Tools: An overview of tools in the web3 data stack and how to leverage them
- Teams: Basic considerations and skills for web3 data teams
Data Thinking
Let’s first summarize how data is built, queried, and accessed in web2 (i.e., accessing Twitter's API). We have four steps to simplify data channels:
- Trigger API events (sending some tweets)
- Update to the database (connecting to existing user models/state changes)
- Data transformation for specific products/analytical use cases
- Model training and deployment (to manage your Twitter feed)
When data is open source, the only necessary step is after the transformation is complete. Communities like Kaggle (1,000 data science/feature engineering competitions) and Hugging Face (26,000 top NLP models) use some public data subsets to help businesses build better models. There are specific cases in certain domains, such as OpenStreetMap, which open data in the first three steps, but they still have write permission restrictions.
What I want to state is that I am only talking about data here; I am not saying web2 is completely devoid of open source. Like most other engineering roles, web2 data has a plethora of open-source tools to build their pipelines (dbt, Apache, TensorFlow). We still use all these tools in web3. In summary, their tools are open, but their data is closed.
Web3 also opens up data, meaning that it is no longer just data scientists working in open environments; analytics engineers and data engineers are also working in open environments! Everyone participates in a more continuous workflow rather than an almost black-box data cycle.
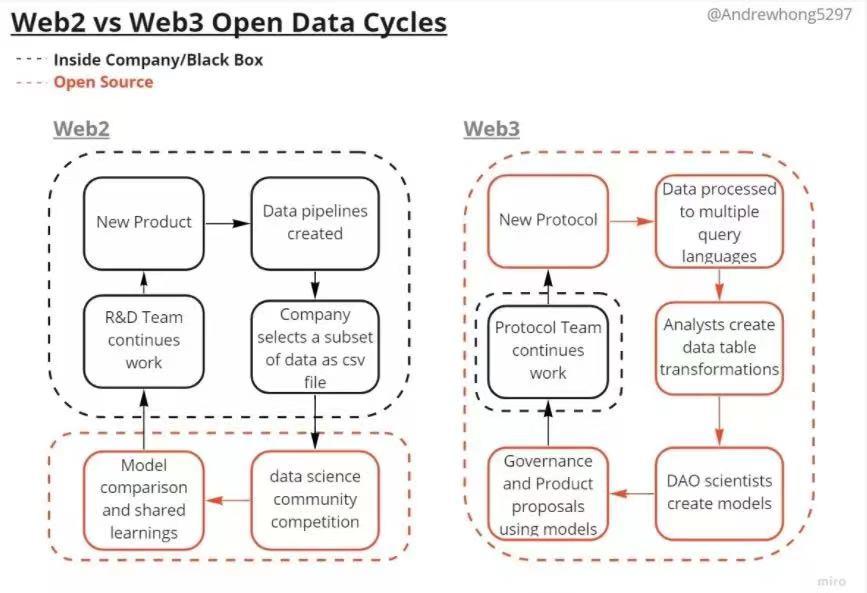
The form of work has shifted from web2 data dams to web3 data rivers, deltas, and oceans. It is equally important to note that all products in the ecosystem will be simultaneously affected by this cycle.
Let’s look at an example of how a web3 analyst works together. There are dozens of exchanges using different trading mechanisms and fees, allowing you to swap token A for token B. If these were typical exchanges like Nasdaq, each exchange would report its data in 10k or some API, and then other services, like CapIQ, would aggregate all exchange data and charge you for access to their API. Maybe sometimes they would hold an innovation competition so they could charge for additional data/chart features in the future.
In web3 exchanges, we have the following data flow:
- dex.trades is a table on Dune (compiled over time by many community analytics engineers), where all DEX exchange data is aggregated, so you can easily search for the trading volume of a single token across all exchanges.
- A data analyst creates a dashboard through community open-source queries, so now we have a public overview of the entire DEX industry. Even if all queries appear to be written by one person, you can guess that this was accurately pieced together after extensive discussions on Discord.
- DAO scientists view the dashboard and start segmenting the data in their own queries, looking at specific pairs, such as stablecoins. They observe user behavior and business models and then begin to formulate hypotheses. Since scientists can see which DEX holds a larger share of trading volume, they will propose a new model and suggest changes to governance parameters for on-chain voting and execution.
- Afterward, we can always check public queries/dashboards to see how proposals create more competitive products.
- In the future, if another DEX emerges (or upgrades to a new version), this process will repeat. Someone will create insertion queries to update this table. This will, in turn, reflect in all dashboards and models (without anyone having to go back and manually fix/change anything). Any other analysts/scientists can build on the work that others have already completed.
Due to the shared ecosystem, discussions, collaborations, and learning occur in a tighter feedback loop. I acknowledge that this can sometimes be overwhelming; the analysts I know are basically rotating through data exhaustion. However, as long as one of us continues to push data forward (for example, someone creates insertion DEX queries), everyone else will benefit.
It doesn’t always have to be complex abstract views; sometimes it’s just practical functionalities, such as making it easy to search ENS reverse resolvers or improvements to tools, like automatically generating most GraphQL mappings with a CLI command! All of these can be reused by everyone and can be utilized in some product front-end or your own personal trading models via API.
While the possibilities opened up here are amazing, I do acknowledge that the wheels have not been running smoothly yet. Compared to data engineering, the ecosystem for data analysts/scientists is still quite immature. I believe there are several reasons for this:
Data engineering has been the core focus of web3 for years, from improvements in client RPC APIs to basic SQL/GraphQL aggregations. Products like TheGraph and Dune are examples of the efforts they have put into this area.
For analysts, understanding the unique cross-protocol relationship tables in web3 is very challenging. For instance, analysts may understand how to analyze Uniswap alone but find it difficult to add aggregators, other DEXs, and different token types into the mix. Most importantly, the tools to achieve all this only really emerged last year. Data scientists are often used to collecting raw data and doing all the work themselves (building their own pipelines). I think they are not accustomed to collaborating so closely and openly with analysts and engineers in the early stages of development. It took me some time personally.
In addition to learning how to work collaboratively, the web3 data community is also learning how to work across this new data stack. You no longer need to control the infrastructure or slowly build from Excel to data pools or data warehouses; as soon as your product is online, your data will be online everywhere. Your team is essentially thrown into the deepest end of the data infrastructure.
Data Tools
Here is a summary of some data tools:
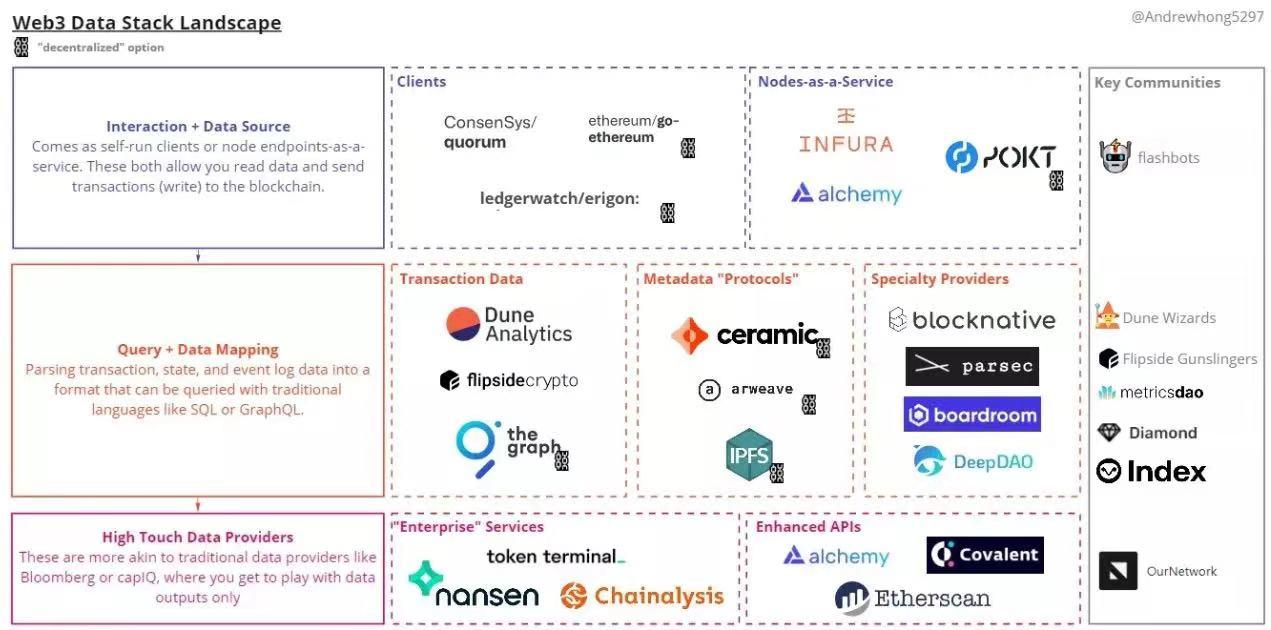
Now let’s look at each type and its usage:
- Interaction + Data Sources: This is mainly used for front-end, wallets, and lower-level data ingestion.
1.1. Clients: While the underlying implementation of Ethereum is the same, each client has different additional features. For example, Erigon has optimized data storage/synchronization significantly, and Quorum supports privacy chains.
1.2. Node as a Service: You don’t have to choose which client to run, but using these services will save you the hassle of maintaining nodes and keeping APIs running smoothly. The complexity of the node depends on how much data you want to capture (light node → full node → archive node).
- Query + Data Mapping: The data in this layer is either referenced as a URI in contracts or comes from using contract ABI to map transaction data from bytes to table schemas. The contract ABI tells us which functions and events are included in the contract; otherwise, we can only see the deployed bytecode (without this ABI, you cannot reverse engineer/decode contract transactions).
2.1. Transaction Data: These are the most commonly used, primarily for dashboards and reports. TheGraph and Flipside API are also used in the front end. Some tables are 1:1 mappings of contracts, while others allow for additional transformations in the schema.
2.2. Metadata "Protocols": These are not really data products but are used for storing DIDs or file storage. Most NFTs will use one or more of these data sources, and I believe we will start using these data sources more and more this year to enhance our queries.
2.3. Specialized Providers: Some of these are very robust data stream products, such as Blocknative for mempool data and Parsec for on-chain transaction data. Others aggregate on-chain and off-chain data, such as DAO governance or treasury data.
2.4. High-Dimensional Data Providers: You cannot query/transform their data, but they have already done all the heavy lifting for you.
Without a strong, outstanding community to complement these tools, web3 would not exist! We can see prominent communities corresponding to each type:
Flashbots: Focused on MEV, providing everything from custom RPCs to protect transactions to professional white-hat services. MEV primarily refers to the "miner extractable value" problem, where someone pays more gas than you (but directly to miners) so they can front-run their transactions.
Dune Data Elites: Data analytics elites focused on contributing to Dune's data ecosystem.
Flipside Data Elites: Data analytics elites focused on contributing to the ascension of Web3 data.
MetricsDAO: Working across ecosystems, handling various data rewards across multiple chains.
DiamondDAO: Focused on data science work for Stellar, primarily in governance, treasury, and token management.
IndexCoop: Focused on analysis in specific areas like tokens to create the best indices in the cryptocurrency industry.
OurNetwork: Weekly coverage of various protocols and Web3 data.
Note: For participation contact details of the above DAOs, please refer to the original text.
Each community has done a tremendous amount of work to improve the web3 ecosystem. There is no doubt that products with communities will grow at a hundredfold pace. This remains a severely underestimated competitive advantage, and I believe that unless people build something in these communities, they will not gain this advantage.
Data Teams
Needless to say, you should also look for people in these communities to join your team. Let’s further analyze the important web3 data skills and experiences so you can truly know what you are searching for. If you want to be hired, consider this as the skills and experiences you should pursue!
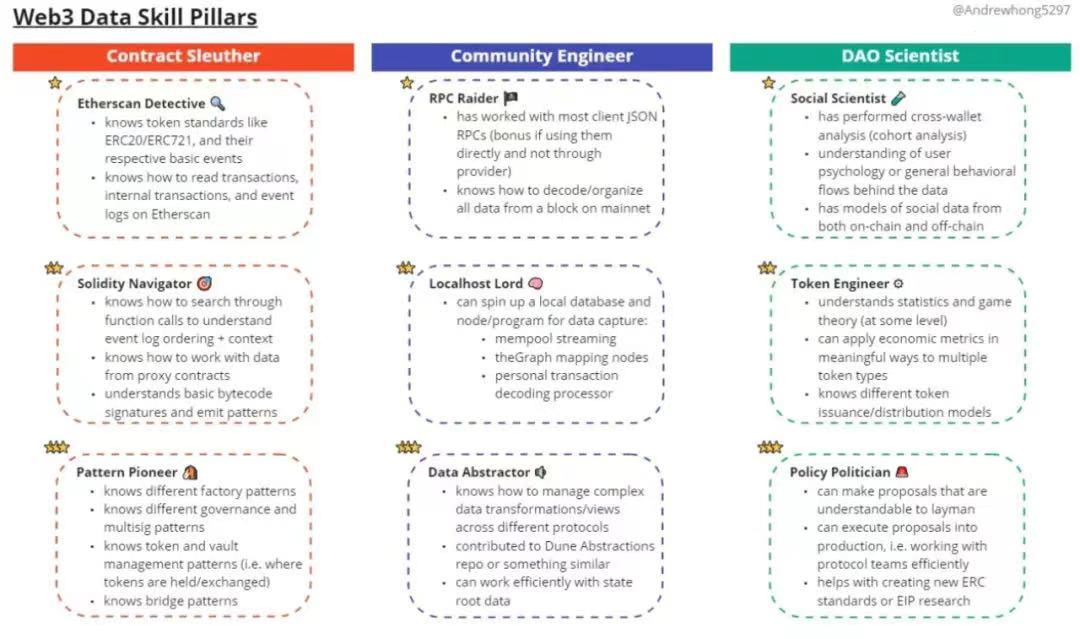
At a minimum, analysts should be Etherscan detectives, knowing how to read Dune dashboards. This may take about a month to adapt to leisurely learning, and if you really want to learn intensely, it will take about two weeks.
In addition, you need to consider more content, especially time allocation and skill transferability.
Time Aspect: In web3, data analysts will spend about 30-40% of their time keeping in sync with other analysts and protocols in the ecosystem. Make sure you don’t overwhelm them, or this will become a long-term detriment to everyone. Learning, contributing, and building with the larger data community is necessary.
Transferability Aspect: In this field, skills and domains are highly transferable. If using different protocols, it may reduce the onboarding time since the table schemas for on-chain data are the same.
Remember, knowing how to use these tools is not what matters; every analyst should more or less be able to write SQL or create data dashboards. It’s all about how to contribute and collaborate with the community. If the person you are interviewing is not a member of any web3 data community (and seems to have no interest in this area), you might want to ask yourself if this is a red flag.
 Risk warning
Risk warning Risk warning
Risk warning