
Web3 + AI :构建主权 AI 满足 Crypto 社区利益和诉求

 大多数Web3 + AI的项目是在利用区块链技术解决AI行业基础设施项目的建设问题,少数项目是利用AI解决Web3应用的某些问题。
大多数Web3 + AI的项目是在利用区块链技术解决AI行业基础设施项目的建设问题,少数项目是利用AI解决Web3应用的某些问题。黄仁勋在迪拜的 WGS 上演讲时,提出了一个词“主权AI”。那么,哪个主权的 AI 能符合 Crypto 社区的利益和诉求呢?
也许需要以 Web3 + AI 的形式构建。Vitalik 在“The promise and challenges of crypto + AI applications”一文中讲述了 AI 与 Crypto 的协同效应:Crypto的去中心化可以平衡AI的中心化;AI是不透明的,Crypto带来透明;AI需要数据,区块链有利于数据的存储和追踪。这种协同,贯穿在Web3+AI的整个产业图景中。
大多数Web3 + AI的项目是在利用区块链技术解决AI行业基础设施项目的建设问题,少数项目是利用AI解决Web3应用的某些问题。
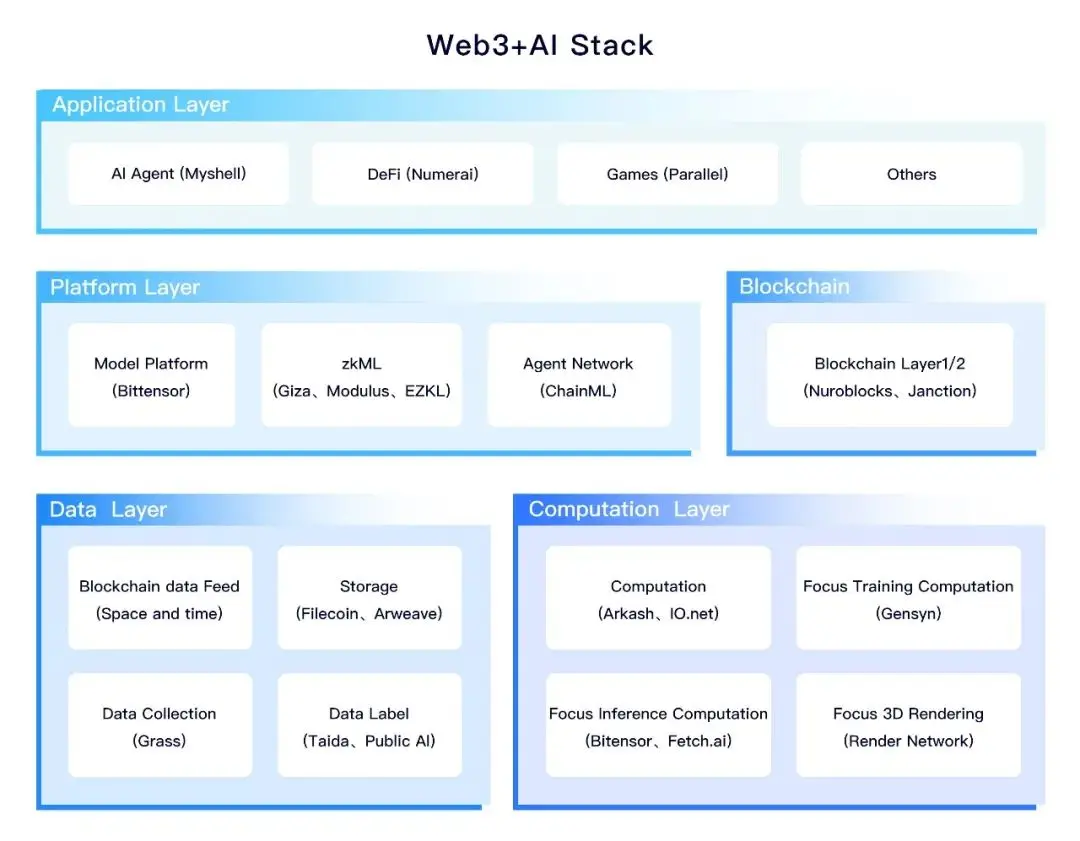

1、算力层:算力资产化
近两年来,用于训练AI大模型的算力呈指数级增长,基本每个季度就会翻一倍,以远超摩尔定律的速度疯狂增长。这种情况导致AI算力供需长期失衡,GPU等硬件价格快速上涨,进而抬高了算力成本。
但与此同时,市场上也存在大量的中低端算力硬件闲置,可能这部分中低端硬件的单体算力无法满足高性能需求。但若通过Web3的方式建设成分布式算力网络,通过算力租赁、共享的方式,打造去中心化的计算资源网络,仍可满足诸多AI应用需求。由于是利用分布式的闲置算力,可显著降低AI算力的成本。
算力层细分包括:
- 通用的去中心化算力(例如 Arkash 、 Io . net 等);
- 用于 AI 训练的去中心化算力(例如 Gensyn 、 Flock . io 等);
- 用于 AI 推理的去中心化算力(例如 Fetch . ai 、 Hyperbolic 等);
- 用于 3D 渲染的去中心化算力(例如 The Render Network 等)。
2、数据层:数据资产化
数据是AI的石油、血液。如果不依赖Web3,一般只有巨头企业手中才有大量的用户数据,普通的创业公司很难获取广泛的数据,用户数据在AI行业的价值也并没有反馈给用户。通过Web3+AI,可以让数据收集、数据标注、数据分布式存储等流程更低成本、更透明、更有利于用户。
收集高质量数据是AI模型训练的前置条件,通过Web3的方式,可以利用分布式网络,结合适当的Token激励机制,采用众包收集的方法,以较低成本获取高质量且广泛的数据。
根据项目用途,数据类项目主要包括以下几类:
- 数据收集类项目(例如 Grass 等);
- 数据交易类项目(例如 Ocean Protocol 等);
- 数据标注类项目(例如 Taida 、 Alaya 等);
- 区块链数据源类项目(例如 Spice AI 、 Space and time 等);
- 去中心化存储类项目(例如 Filecoin 、 Arweave 等)。
3、平台层:平台价值资产化
平台类项目大多数会对标Hugging Face,以整合AI行业各类资源为核心。建立一个平台,聚合数据、算力、模型、AI开发者、区块链等各种资源和角色的链接,以平台为中心,更便捷地解决各种需求。比如Giza,专注于构建全面的zkML运营平台,旨在使机器学习的推理变得可信和透明,因为数据和模型黑盒是目前AI中普遍存在的问题,通过Web3的方式采用ZK、FHE等密码学技术来验证模型的推理确实有正确执行,是迟早会被行业内呼吁的。
也有做Focus AI的layer1/ layer2,例如Nuroblocks、Janction等。核心叙事是连接了各类算力、数据、模型、AI开发者、节点等资源,通过包装通用组件、通用SDK的方式,帮助Web3+AI类应用实现快速构建和发展。
还有Agent Network类的平台,基于这类平台可以为各种应用场景构建AI Agent,例如Olas、ChainML等。
平台类的Web3+AI项目,主要以Token捕获平台价值的方式,激励平台各参与方共建。对于初创项目从0-1的过程比较有帮助,可以减少项目方寻找算力、数据、AI开发者社区、节点等合作方的难度。
4、应用层: AI 价值资产化
前面的基础设施类的项目,多数是利用区块链技术解决AI行业基础设施项目建设的问题。应用层项目则更多是利用AI解决Web3应用存在的问题。
比如Vitalik在文章中提到两个方向,我觉得很有意义。
一是AI作为Web3参与者。比如:Web3 Games中,AI可以作为一个游戏玩家,它可以快速理解游戏规则,并最高效地完成游戏任务;DEX中,AI已经在套利交易中发挥作用很多年了;Prediction markets(预测市场)中,AI Agent可以通过广泛接受大量数据、知识库和信息,训练其模型的分析预测能力,并产品化提供给用户,帮助用户以模型推理的方式对特定事件作出预测,比如体育赛事、总统大选等。
二是创建可扩展的去中心化的私人AI。因为许多用户担心AI的黑盒问题,担心系统存在偏见;或担心存在某些dApps通过AI技术欺骗用户来获利。本质上是因为用户对AI的模型训练和推理过程没有审查权限和治理权限。但是如果创建一个Web3的AI,像Web3项目一样,社区对这个AI有分布式治理权,可能会更容易被接受。
截至目前,在Web3+AI应用层尚未出现天花板很高的白马项目。
总结








